
[excerpt of a community workshop @ 16 sept 2022]
When the juju agent decides it’s time to execute the charm, the dispatch script is ran with a certain environment. ops translates bits and pieces of that environment into an Event object, which the charm can use to reason about why the charm code itself is being executed; e.g.
- this remote unit touched its relation data
- my config changed
- the user ran an action
- …
When developing or debugging a charm, it is often useful to make subtle changes to the source code and see how that affects the runtime behaviour. However, it takes time to re-pack, re-deploy, re-run the (potentially long) sequence of actions and events that led to that specific, possibly broken state of affairs.
Ideally, we would like to spin up our development environment, and either:
- force a specific event to occur, so that we can observe the runtime code paths
- wait for an event to occur (or for an event to break something!)
In both those cases, we’d like to be able to quickly iterate between making changes to the source and re-firing the same event over and over until the behaviour converges.
In this post I’ll explain some tooling that makes this process possible, with some limitations. We’ll dive straight into it, hands-on.
What you need: jhack revision > 82 (available on the edge channel at the time of writing).

Access to a (micro)k8s cloud, a model, and a good cuppa coffee.
Setting the stage
We’re going to work with two charms, traefik and prometheus. To set the model up:
j model-config logging-config="<root>=WARNING;unit=DEBUG"
j deploy traefik-k8s --channel edge trfk --config external_hostname=foo.bar
j deploy traefik-k8s --channel edge trfk
j relate trfk prom:ingress
Wait for the model to settle.
Meanwhile we can fire up jhack tail -rl 10 to see the events come up.
Injecting a recorder script
We can visualize the standard charm runtime for a k8s charm as:
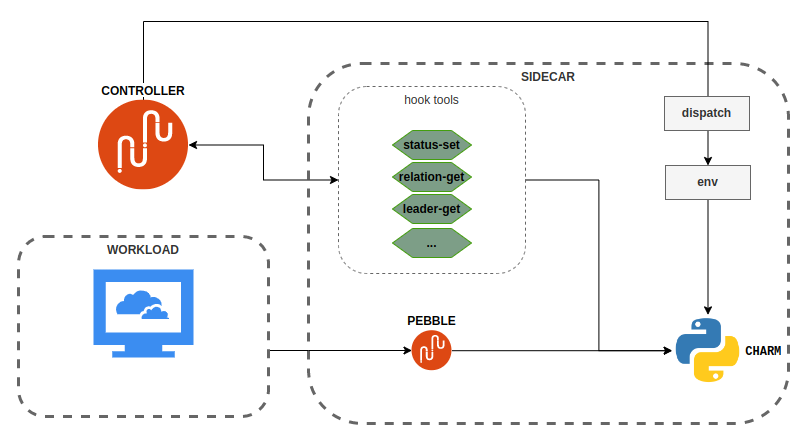
This graph is about k8s charms, the picture for machine charms is a bit different but the same runtime flow applies.
What we want to do is insert a listener between dispatch and the charm that, on each incoming event, serializes the environment and drops it to a database, where we can access it and use it to repeat the charm execution “with the same environment”. There are plenty of caveats to this, but we’ll get there later.
If you execute jhack replay install trfk/0, that is exactly what will happen.
The picture now looks like:

At this point jhack replay gives you access to three more commands:
-
list: to enumerate the events that the database has recorded so far. -
dump: to get the raw database contents. -
emit: to re-emit a previously recorded event, by its enumeration index.
Populating the database
If you try to jhack replay list trfk/0 at this point, you’ll likely get a message telling you that the database is empty. The recorder has just been installed, so we need to wait for something to happen.
Of course, we can speed up time (jhack ffwd) and get an update-status, but wouldn’t it be nice to just get an event right now?
Type jhack fire update-status trfk/0 and the charm is going to execute an update-status hook. How is this possible? Jhack fire takes a different approach than jhack replay: it synthesizes an environment from scratch, instead of copying it from some “real” recorded event.

To make it more interesting, try jhack fire ingress-per-unit-relation-changed.
Behind the scenes, jhack fire is using juju exec, a command which runs a command in a unit “as if” the juju agent were running it in a live event context; and in this case, jhack is using it to call dispatch.
Question: In this case, the event context requires several context variables to be set (JUJU_RELATION_ID for example), for ops to be able to determine which ingress relation has changed. How does jhack get the relation id?
At this point, running jhack replay list trfk/0 will show the event you just fired (and maybe others that fired as you were reading this).
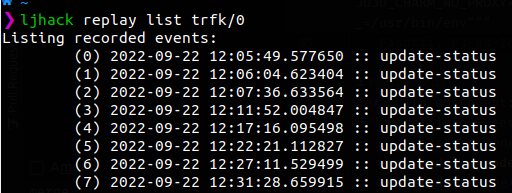
The context generated by jhack fire has been enriched by a number of other context vars injected by the juju agent, including for example the model name and UUID, without which charm code would misbehave.
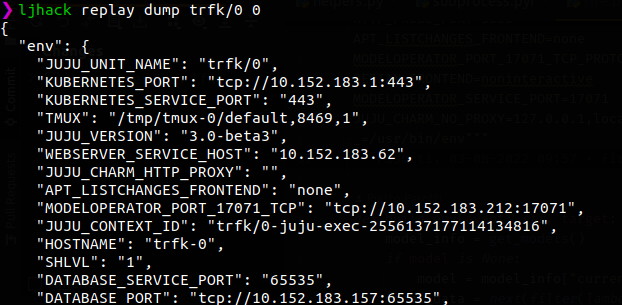
If you run jhack replay dump trfk/0 0 you should be able to inspect that environment.
Simulating events
If you now run jhack replay emit 0, the charm will re-run that event:  .
.

The warnings you see are due to an unsolved issue involving how to escape the whitespace in the wrapped juju exec command. If you know how to fix it, by all means: https://github.com/PietroPasotti/jhack/issues/18
You can mix and match fire and replay to get where you want, but there are a couple of serious caveats to keep in mind.
State we wrap, state we don’t wrap: false positives
The execution context of a charm is a dynamic thing. Only a part of it, the env, the metadata, the config, is static (within the context of a charm execution, that is). But if your charm, say,
- makes HTTP calls to a remote server to check if it’s up
- checks
container.can_connect() - reads/writes relation data
- manipulates stored state
- checks leadership throughout a hook which takes longer than 30 seconds to return
- makes pebble calls to check the live status of workload resources
- makes substrate api calls to retrieve the live status of substrate resources
… or basically anything else which is not part of the environment variables the charm is ran with, in all of these cases, the runtime behaviour can’t be guaranteed to be the same every time you fire/replay an event.
For example, suppose that the first time you fire an event, the charm gives an error because the relation data provided by the remote end is invalid. If you re-fire this event, it might well be that the remote unit fixed the relation data in the meantime. Or that the unit lost/gained leadership. And so on…
The next step to make this tool more useful, and recorded charm runs to be truly reproducible, is to cache every single piece of data that the charm calls state, including the list above. Only then, we can be assured that we can exactly replicate a code path remotely – or, at that point, even locally.
Idempotency and false negatives
If your charm code is truly idempotent, you should be able to re-run every event any number of times in a sequence without things breaking. However, charm code rarely is truly idempotent because we all make (some justified, some less) assumptions about what events will only ever run once, or will never run before/after some other event, etc…
So it is in practice often justified for a remove hook not to be idempotent and omit checking whether the resources are already released before attempting to re-release them (and raise an exception). Which means that by using fire/replay indiscriminately we may reveal some false negatives: bugs which will never occur in production because juju guarantees, for example, that a remove hook will never run twice on a unit.
Conclusions
We have seen how we can use jhack fire and jhack replay to trigger charm execution given a certain context (specifically: an event). We have seen that this approach is currently severely limited by the amount of charm ‘state’ that we can collect, serialize, and finally “mock” or force-feed to the resurrected charm instance to obtain a perfect replica of a given execution.
Happy hacking!
