Juju contains a number of primitives that allow for building robust charm solutions. One of these is the concept of an application leader. The leader primitive allows units of an application to hold the leader status (akin to a distributed lock that expires) via an election process. The leader status gives authoritative status to a given charm allowing the charm to execute commands if they are the leader. You can read a more in-depth overview at the Leadership SDK.
The current leadership backend runs a Raft FSM instance, that is fronted by a publisher and subscriber event hub (juju/pubsub). In highly available (HA) setups, all communications are redirected from all the Juju controller nodes to the leader node. Pubsub nicely handles the complexity of this by forwarding all events to the leader via the raftforwarder worker. Applying any Raft logs to the FSM before sending the resulting event back.
In some scenarios pubsub can cause some quite problematic issues:
- If the Raft FSM fails to process the logs in a timely manner, the pubsub subscriber queue backs up and there isn’t a way to currently shed the load. The caller of the publish event times out the publishing of the event and returns an error, which can be subsequently retried.
- As we can’t shed the load in the subscriber queue, we compound the issue more by retrying, so more load is applied. A tsunami of events is visible.
- Even if we’ve timed out and performed the retry, we didn’t actually stop anything from processing the log and attempting to apply it to the Raft FSM. This can lead to weird state issues; where we tried to claim, we timed out waiting for a response, we try again for a claim, not knowing if we actually successfully made a claim.
Having said all of these issues, one thing to note is that the pubsub will continue processing claims as fast as the Raft FSM can process the logs. The Raft FSM will dictate the pressure it can handle if everything is humming along nicely.
The problem occurs if the load on pubsub is so high it causes some telltale signs:
- The controller flat-out dies and requires a restart (OOM death). There are so many resources required to keep the pubsub up that we just run out of memory. Restarting the controller allows us to shed the load, but if the other controllers haven’t also died, it creates a stampede of lease timeout errors.
- Starvation attempting to apply the global time to the Raft FSM. The Raft FSM has a global time that is advanced by the globalclockupdater worker, which ensures that an agreed time is coordinated between all nodes and the lack of an update causes problems downstream in the lease manager.
Having identified these problems, a design was settled upon to see if it was possible to reduce the number of restarts required and allow Juju to continue working, even under load. The proposed solution was to route the lease requests from pubsub through the API Server facades. This gave us two distinct benefits:
- We can use the tried and tested facade setup that has been battle-tested and is key to how Juju works.
- We can shed the load if attempting to apply a log to the Raft FSM takes too long.
This ended up being quite tricky to implement, as it required some machinery to get around the circular dependency engine problem (it required the API server to be up for us to accept the Raft logs, but Raft required the API server to be up at the same time).
Load testing
The last couple of days I’ve been attempting to load test the new implementation and although we’ve had good success in preventing Juju from falling over, even under extreme load, I haven’t managed to find the sweet spot on getting it to process more load (more on this later).
To run these examples for yourself, you can follow along with the series of pull requests #13453 #13418. Additional information about lease scale testing.
The test was run using the localhost (LXD) provider, using HA 3 node setup. Using the leaseclaimer script from the previous lease scale testing.
Observations
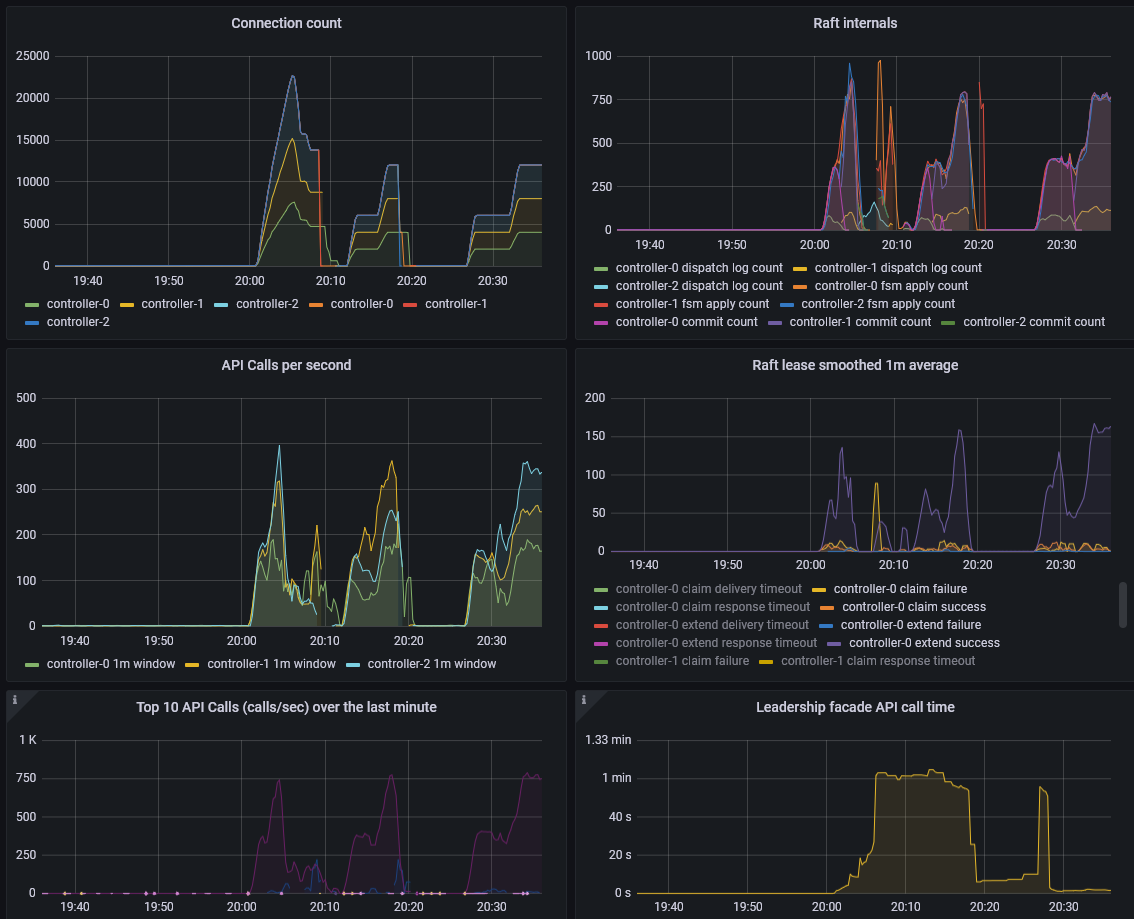
The dashboards are not exactly matching because the pubsub and API offer different metrics. Pubsub implementation offers the number of published and consumed events over a given time and the API showing the lease operations of consuming a raft log in milliseconds.
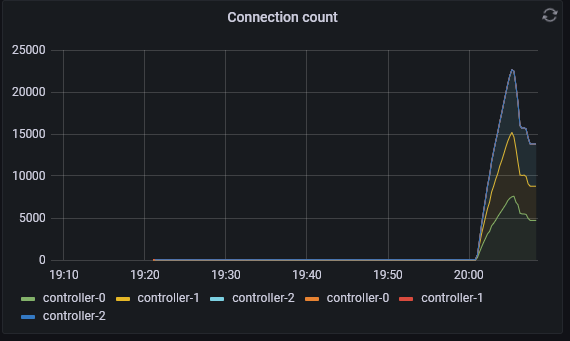
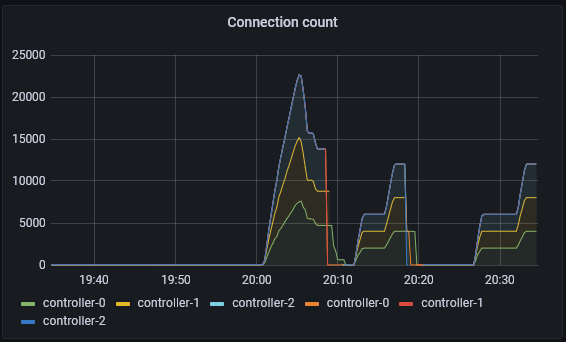
The following grafana dashboard shows pubsub easily handling 100 different processes, each with 40 leases, each with 3 units (roughly 3 * 100 * 40 = 12000 connections, vying for 4000 leases).
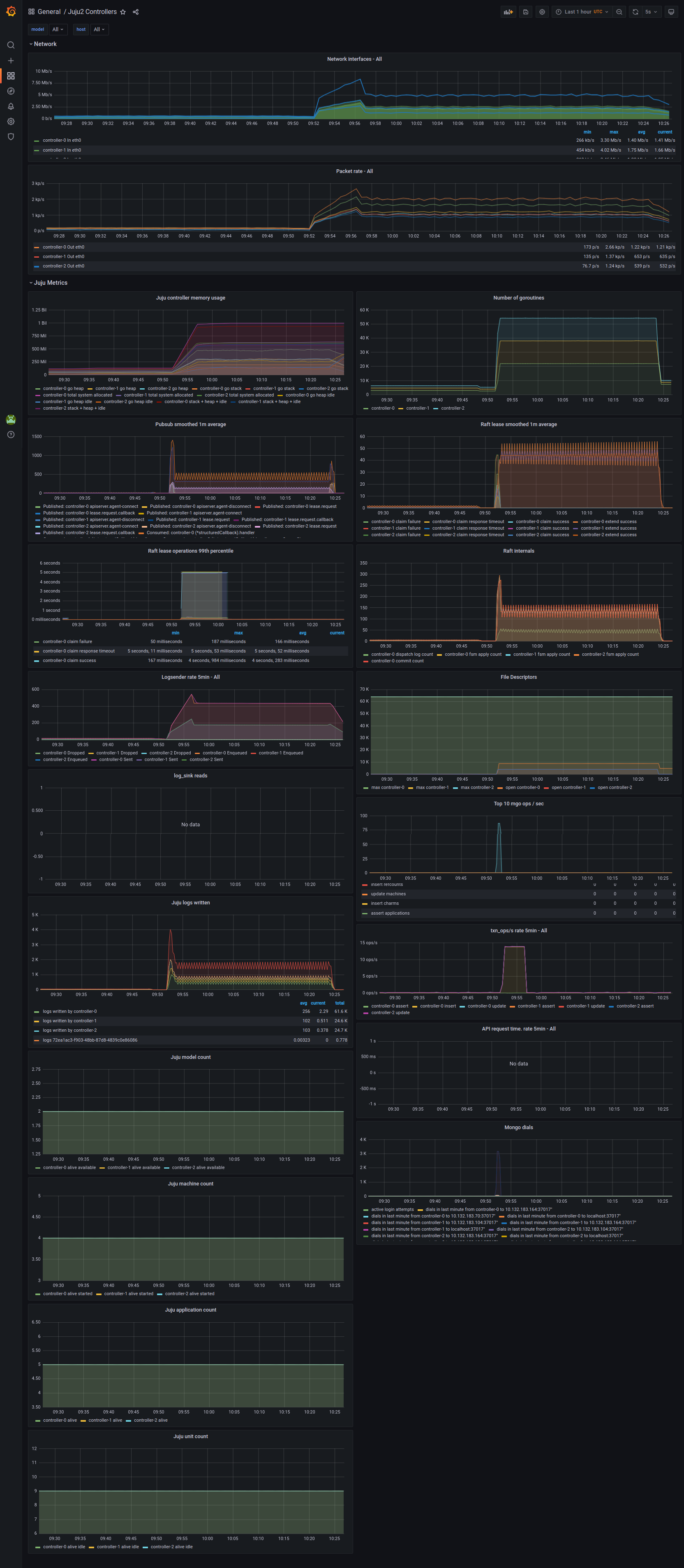

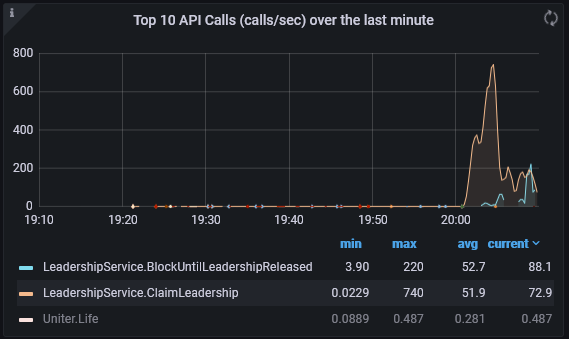
Pubsub is the first, API is the second.
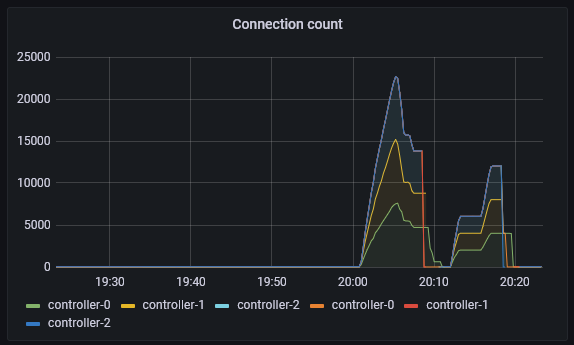
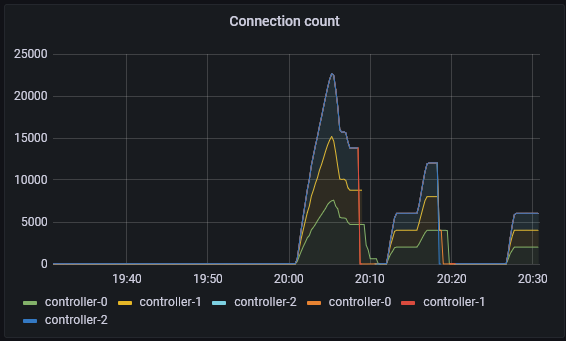
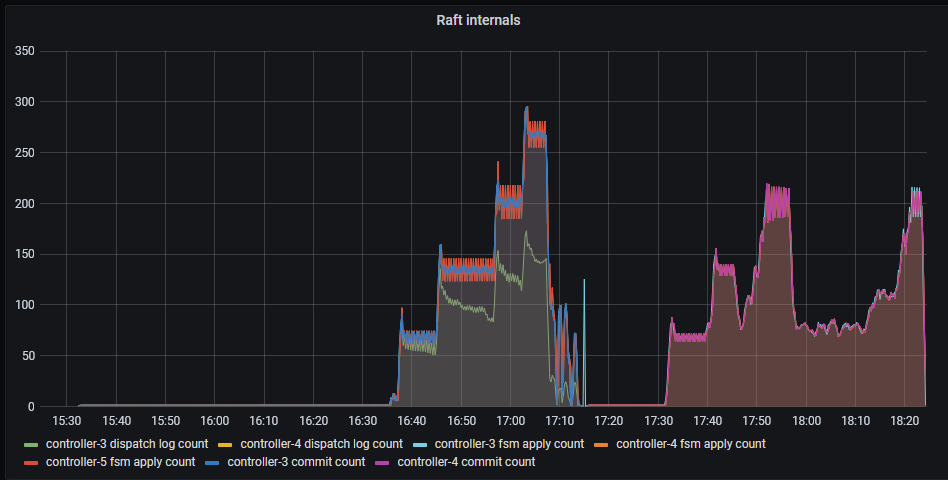
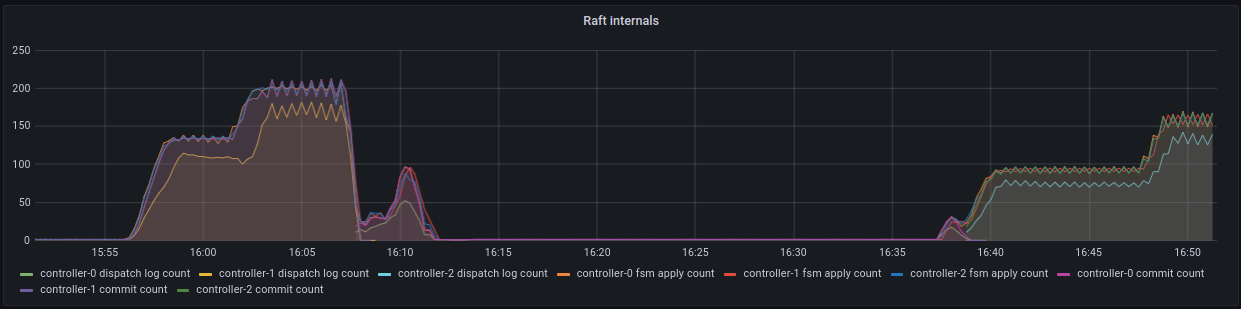
When we turn this up a few more levels; 300 different processes, each with 200 leases, each with 3 units (roughly 3 * 300 * 200 = 180000 connections, vying for 60000 leases). We can see that pubsub has started to see failures and the number of failures has started to rise. Although the number of apply count rate is very impressive at over 1000. At this point, the API implementation has started to shed the load and can not even get close to the pubsub implementation.
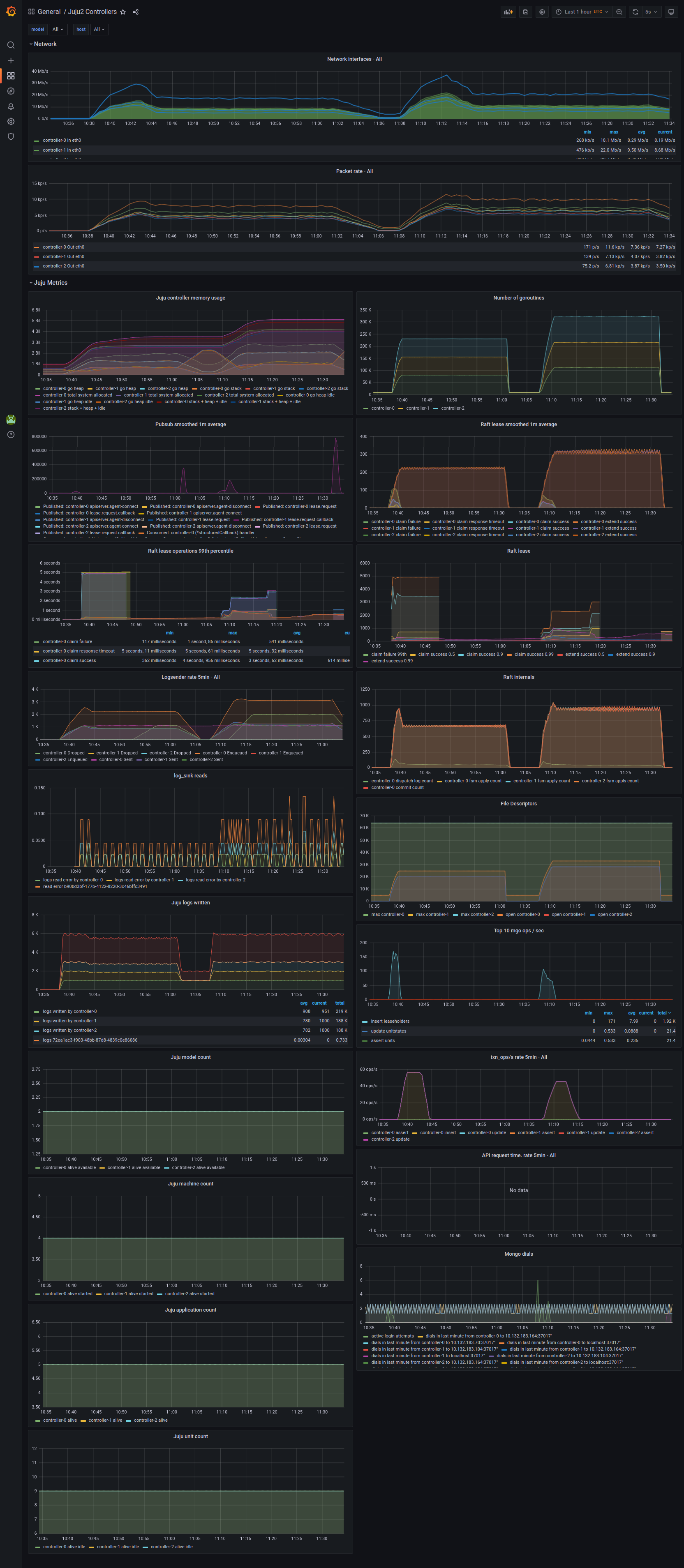
More work is required to push the API version through to a higher commit rate against the Raft log. The idea here is not to overload Juju till it’s crippled, but to correctly shed the load so that it never gets into a state where we have to restart it. Improving the API numbers should be possible, given that the pprof output from the API implementation shows that the raft log application isn’t in the hot path.
The future
There is ongoing work to relook at the way leadership is currently implemented and I’ll post the spec here once I’ve finalized it.