
Waiting for CI is painful
Does this sound familiar?
- You push a commit with minor changes
- CI is slow, so you start working on something else
- A couple hours later, you remember to check the CI. It failed and you don’t remember why you made the changes
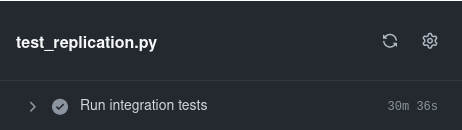
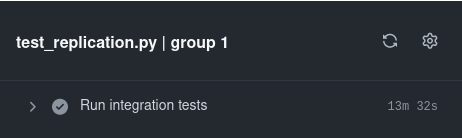
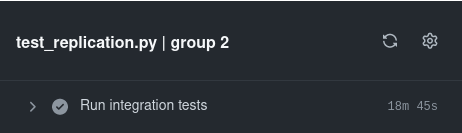
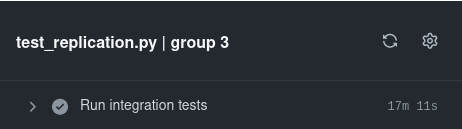
For the mysql charm, our replication integration tests took around 30 minutes. By running the tests in parallel we were able to reduce this by nearly one half.
Run tests sequentially
Run tests in parallel
Why are integration tests slow?
For the mysql charm, the vast majority of the test duration is spent:
- Building the charm (see the Faster integration tests with GitHub caching post)
- Waiting for a charm to deploy and reach active status
- Waiting for the mysql charm to scale up or scale down
Take this test function as an example. For one CI run, the total test duration (excludes building the charm) was 13 minutes 48 seconds. Eighty-five percent of the test duration (11 minutes 41 seconds) was spent waiting for the charm to deploy, scale up, or scale down.
Running tests in parallel
In the mysql charm, our integration tests are organized into multiple Python files. Each of these files already runs in parallel in our CI. To further shorten our total test duration, we can run test functions from the same Python file in parallel.
Step 1: Identify when to run tests in parallel
Running tests in parallel has tradeoffs. Parallel tests decrease the time spent waiting for your CI suite to pass, but increase the total machine time used. If your CI runners cost money or have a concurrent job limit, it may be better to run tests sequentially.
Defining “slow test”
For the mysql charm, all of our integration tests have a slow setup (deploy 3 mysql units & wait for active status). After the setup, some of our integration tests are fast (they do not deploy more charms or scale the mysql charm) and some of our integration tests are slow (they do deploy more charms or scale the mysql charm).
Goal: If our Python test file contains 2 or more tests that are slow after the initial setup, run the slow tests in parallel.
Each slow test should have its own group. Fast tests should share a group with a slow test (unless there are no slow tests—then there is only one group).
Exception: Sometimes, a slow test will depend on another slow test (e.g. the first test deploys charm A and the second test deploys charm B & relates it to charm A). If only one slow test depends on the first slow test, they should share a group.
Step 2
Follow these instructions: https://github.com/canonical/data-platform-workflows/blob/main/python/pytest_plugins/pytest_operator_groups/README.md