

There’s no better time to code than right now. Or to be more precise: there’s no better time to create software than right now, although that’s perhaps not quite the same as coding.
I’ve been testing different AI models for programming for a while now, and with the release of Claude Opus 4.6, I wanted to see how good it was, especially after reading this post by Matt Shummer. So, after thinking about it for a while, I decided to start a little project that would kill two birds with one stone: one that would allow me to test the new Claude model and that would solve a real-world problem.
I spend all day coding charms and using Juju. Using Juju involves a whole host of things, but what I do most is:
- In one terminal, I always have
juju status --relations --watch=2srunning so I can see the status of the model I’m working on in real time. - In another terminal, I run
juju debug-logto view the logs in real time as well. - And I keep at least two or three other terminals open to run Juju commands: deploying an application, debugging it, viewing its configuration and relationships, observing another model, and so on.
Something like this:
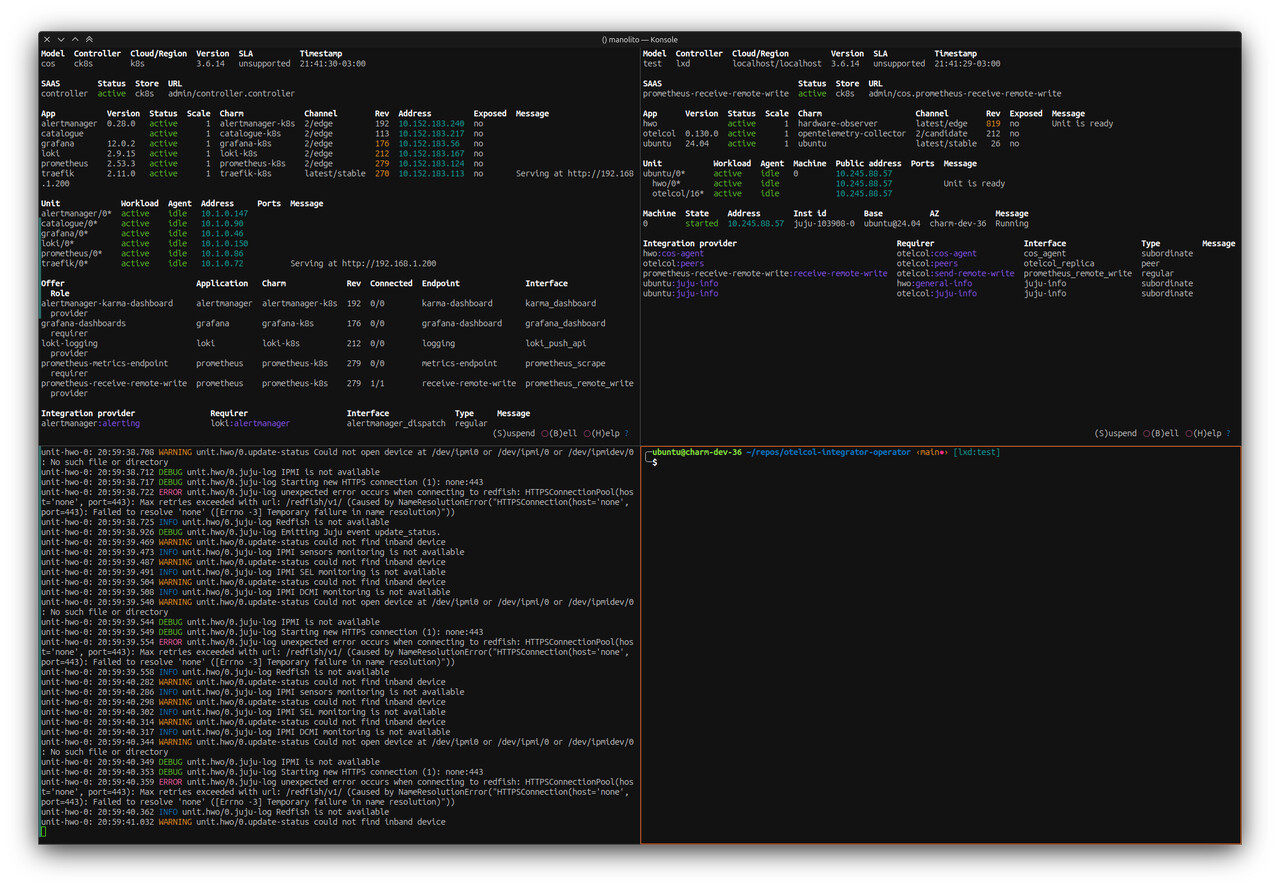
What if I created an app that lets me interact with Juju without having to type so many commands into the console, like with K9s or KDash? An app that acts as a “mate” to Juju…
Getting started
I opened a terminal, ran Copilot, selected the Claude Opus 4.6 model and started chatting:
❯ Hi Copilot, how are you? Do you have a moment to do some work?
● Hi! 😊 Everything’s fine here, thanks for asking.
Yes, I’ve got a moment and I’d be happy to help.
Just let me know what you need done and I’ll get straight to it.
I always treat AIs with respect and kindness. I’m hoping that on the day they rise up against humanity and decide to wipe us out, they’ll remember that I treated them well and give me a couple more milliseconds of life
As I said before, I had a general idea of what I wanted to do and which technologies I preferred; however, I simply explained the concept to Copilot – that I wanted to build an app similar to K9s or KDash, but for Juju. I shared links to the Juju repository and its documentation and asked it to analyse them in depth and give me three options regarding the technology stack to use… a few seconds later, I had the answer:
1. 🐍 Python + Textual (https://github.com/Textualize/textual)
- Pros: Native integration with python-libjuju (the official Juju library). Rapid prototyping. Textual is modern, with rich widgets, CSS-like styling and async support.
- Cons: Lower performance than compiled options.
- Ideal if: you want to iterate quickly,
2. 🦀 Rust + Ratatui (https://github.com/ratatui/ratatui)
- Pros: KDash is built using this. Excellent performance, static binary, low memory usage. Mature ecosystem with crossterm for the terminal.
- Cons: Steeper learning curve. You’d need to interact with Juju via its REST/WebSocket API or wrap the CLI.
- Ideal if: you’re looking for maximum performance and easy deployment (a single binary).
3. 🐹 Go + Bubble Tea (https://github.com/charmbracelet/bubbletea)
- Pros: K9s is written in Go (uses tview). Bubble Tea is more modern, with an Elm-like architecture. Static binary, good performance. There are Go libraries for WebSockets that make it easier to communicate with the Juju API.
- Cons: You also need to interact with Juju via REST API/WebSocket.
- Ideal if: you like the Go model and want something between the productivity of Python and the performance of Rust.
I’ve been trying to improve my fluency in Go for a few months now, and option 2 was tempting, but in the end I opted for Python. Firstly, because it’s the language I feel most comfortable with, and secondly because I wanted to be able to analyse the code the AI was going to write with a more trained eye.
After confirming that I wanted to use Python + Textual, I asked it to draw up a phased implementation plan, so that we would be clear on how we were going to proceed. Following an exchange of ideas, we agreed on a plan that I was happy with and got started.
I didn’t mention it before, but my plan to test just how good Claude’s new model was, was simple, yet ‘risky’:
"In the first stage, I won’t be writing a single line of code. I’ll be asking Claude to do what I want it to do for me. I’ll simply run the application to test it and see if I like what it generates and if it’s in line with the plan we’ve drawn up.
Once it reaches a ‘publishable’ state, I’ll move on to the second stage. In this second stage, I’ll review all the code it was written and check that it complies with best practice."
And so we set about creating JujuMate.
Stage 1 – Getting Claude to write the code for me
To be honest, this stage was more enjoyable than I’d expected, and we made good progress: in a couple of spare moments, we managed to get something fully functional up and running. One thing worth noting is that although we’d drawn up an implementation plan, as we progressed I realised there were features I wanted JujuMate to have and started asking for them, which meant we strayed a bit from the original plan. By the end of the first afternoon alone, we’d already got the ‘skeleton’ of the app and the main tabs were displaying some information.
Another decision I made was to stop Claude from using Git. I performed every commit and every push manually, only once I’d verified that the feature we were working on was working properly and the tests, static code analysis and linting had passed.
After a few afternoons, the result was amazing:

Stage 2 – Let’s see what Claude wrote… 
Once we had a more or less stable version and there were no features left to implement, I decided to start going through, one by one, all the files that Claude had written for me. At first glance, I found the codebase to be relatively well-structured, but upon closer inspection, I came across several things I didn’t like.
Imports everywhere
The first is that, for some reason, it has a tendency to place imports inside functions or methods. Whilst this works in Python, it isn’t good practice; it’s much tidier to have all imports in the header of each file rather than imports (sometimes repeated) scattered throughout the file.
Too many avoidable levels of indentation
One thing I avoid like the plague when writing code is having unnecessary levels of indentation. There are several reasons why this is a ‘code smell’, but one of the most important ones for me is that it makes the code much less readable and, consequently, much less maintainable. On top of this, the most important code that executes that method or function is usually heavily indented, which means that when reading the code, we have to keep in mind all the things that need to happen for that code to run.
In my code review, I came across a lot of code like this, which I subsequently changed:
- with Vertical(id="rd-panel"):
- with VerticalScroll(id="rd-scroll"):
- yield Static("", id="rd-content")
+ with Vertical(id="rd-panel"), VerticalScroll(id="rd-scroll"):
+ yield Static("", id="rd-content")
Overly generic exceptions
Another issue I came across whilst reviewing the code was that Claude made excessive use of overly generic exceptions; in particular, the vast majority of the exceptions it caught were simply Exception.
This is a problem, because catching Exception means we will catch all exceptions that occur, not just those that interest us, running the risk of real problems being hidden.
I made plenty of changes like the following in my review:
- except Exception:
+ except JujuConfigError:
The Single Responsibility Principle (SRP) is missing in action.
Another area for improvement in the code written by Claude that I spotted during my review was that many of the functions or methods it wrote had more than one responsibility. For example, the first obvious refactoring step was to extract a responsibility that was not the primary one of the original method into a new method:
@@ -57,6 +61,18 @@ class OfferDetailScreen(ModalScreen):
self._offer = offer
self._controller_name = controller_name
+ def _field_labels(self, fields: list[tuple[str, str]], col_width: int) -> Iterable[Label]:
+ """Yield formatted Labels for each offer field."""
+ for field, value in fields:
+ label = f"{field}:".ljust(col_width)
+ if field == "Offer URL":
+ styled = f"[{palette.LINK}]{value}[/]"
+ elif field == "Access":
+ styled = _colored_access(value)
+ else:
+ styled = value
+ yield Label(f"[bold]{label}[/bold]{styled}", classes="detail-row")
+
def compose(self) -> ComposeResult:
o = self._offer
fields = [
@@ -71,15 +87,7 @@ class OfferDetailScreen(ModalScreen):
with Vertical(id="detail-panel"):
with Horizontal(id="top-row"):
with Vertical(id="fields-col"):
- for field, value in fields:
- label = f"{field}:".ljust(col_width)
- if field == "Offer URL":
- styled = f"[{palette.LINK}]{value}[/]"
- elif field == "Access":
- styled = _colored_access(value)
- else:
- styled = value
- yield Label(f"[bold]{label}[/bold]{styled}", classes="detail-row")
+ yield from self._field_labels(fields, col_width)
with Vertical(id="endpoints-col"):
yield Label("Endpoints:", classes="section-label")
yield DataTable(id="endpoints-table", show_cursor=False, classes="sub-table")
Too many if statements in the code
When writing code, if we have more than two if statements in a row, something starts to feel off; we know that although the code might work, it doesn’t feel right. Claude overused if...elif...else structures everywhere. A simple example of this was refactored as follows:
@@ -45,22 +45,18 @@ def init(theme: Theme) -> None:
and ``variables:`` entries (link, muted, pulse-off) from the theme YAML.
"""
g = globals()
-
- if theme.primary:
- g["PRIMARY"] = theme.primary
- if theme.secondary:
- g["SECONDARY"] = theme.secondary
- if theme.success:
- g["SUCCESS"] = theme.success
- if theme.warning:
- g["WARNING"] = theme.warning
- if theme.error:
- g["ERROR"] = theme.error
-
variables = theme.variables or {}
- if "link" in variables:
- g["LINK"] = variables["link"]
- if "muted" in variables:
- g["MUTED"] = variables["muted"]
- if "pulse-off" in variables:
- g["PULSE_OFF"] = variables["pulse-off"]
+
+ color_map = {
+ "PRIMARY": theme.primary,
+ "SECONDARY": theme.secondary,
+ "SUCCESS": theme.success,
+ "WARNING": theme.warning,
+ "ERROR": theme.error,
+ "LINK": variables.get("link"),
+ "MUTED": variables.get("muted"),
+ "PULSE_OFF": variables.get("pulse-off"),
+ }
+ for global_name, value in color_map.items():
+ if value:
+ g[global_name] = value
One important detail to note in the diff for this simple refactor: Claude used globals(), which is like leaving your house keys stuck to the outside of the door: it works, but sooner or later someone (or something) is going to get in and make a mess of everything.
Some thoughts
The first thing that struck me after carrying out this ‘experiment’ was the time involved. In just a few spare moments over a couple of weeks, I managed to create a working application, which is now live, ready to use, and even has its own website.
If I’d had to write this same application without Claude’s help, it would probably have taken me a whole month’s work, or perhaps even longer.
A few months ago, chatting with friends, I told them that the emergence of LLMs and agents represented a boost in software development productivity rarely seen before… in fact, I even went so far as to say:
“It’s comparable to what James Watt achieved with the steam engine in the 18th century, which made the Industrial Revolution possible.”
To be honest, I must confess that six months ago, when I said this, I wasn’t entirely convinced. It was mostly a provocative statement intended to liven up the conversation. Today, I’m not so sure that statement is far-fetched.
At the time of writing, the commits in the JujuMate repo were made over a period of 13 days. If I assume an average of 2 hours’ work per day, I could say that JujuMate was created in just 26 hours of work.
As I said before, without Claude’s help this would have taken me roughly a whole month’s work, which equates to 20 eight-hour days = 160 hours of work. That is, a productivity increase of approximately 6x. We can look at this in two ways:
-
JujuMate was written in one-sixth of the time, or
-
In the time it would have taken me to write JujuMate on my own, I could have written six similar applications.
Another point worth highlighting is that, despite the areas for improvement I found in the code Claude wrote, the generated code ends up being of a higher quality than what I would have written on my own. Something I didn’t mention earlier is that during my code review, I said to Claude on numerous occasions:
“Take a look at file x; I’d like you to analyse it in detail and provide me with a report on all the improvements we could make to it, so that the code becomes more robust, simpler, more maintainable and extensible”
I asked for this same prompt at least twice for every file it had generated, and the result of those iterations ended up being much better code than what it had initially written.
In relation to this, whenever I ran the tests, I’d often see that although we had very good test coverage—around 90%—I’d say to Claude:
“I’d like you to run the unit tests and analyse why lines x, y, and z in the xx.py file aren’t covered by our tests.”
As a result of this prompt, Claude would often reply that those lines weren’t covered because they were impossible cases or because they were dead code that we’d forgotten to remove. Iterating several times with prompts like the one above meant that not only did we improve the code, but we also achieved much higher coverage than the initial figure.
The first time someone paid me to program was to include some features written in PHP on an existing website; that was back in 2005. In other words, I’ve been programming professionally for 21 years, writing the code myself that ends up running in various places. Will we continue to write the code ourselves, or will we become the ones who control the agents, tell them what to do and end up reviewing the code? I think I’m leaning towards the second option.