
ISD267 - haproxy-route policy charm
Abstract
This spec outlines the design of the haproxy-route-policy charm, the haproxy-route-policy relation and the underlying workload that together provide the ability for an administrator to approve/deny incoming load balancing requests via the haproxy-route relation.
Rationale
Currently, any charm with access to the haproxy-route endpoint can integrate with the HAProxy charm and request for a backend to be exposed via the loadbalancer. However, right now HAProxy does not and can not in a reliable manner:
-
Detect and resolve conflicts between requests ( name, paths, hostnames, rewrites, … ).
-
Define what hostname is allowed to be requested.
-
Detect potential issues in the backend request that can affect routing ( aside from syntax errors )
-
Detect values / configurations that doesn’t make sense given the context of the requested backend’s workload
The haproxy-route-policy charm is therefore a way to introduce a human factor to resolve the issues mentioned above. See here for a more detailed explanation on spec rationale .
Specification
Below is an overview of the high-level architecture for the haproxy-route-policy charm.
Proposed architecture
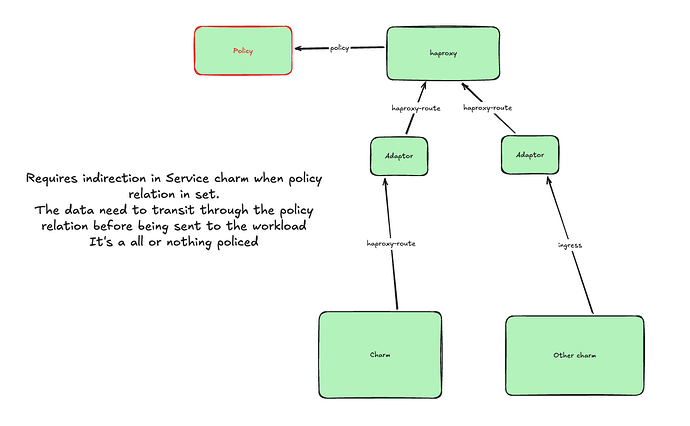
Note: The diagram above shows the adaptor charm related with haproxy-route on both sides, this is not correct and the interface between the adaptor charm and the backend charm should be ingress
This architecture is different from what’s done in the http-proxy-policy charm and the dns-policy charm. In this design, the policy charm is no longer transparent. This means that the HAProxy charm will be required to add custom logic to its charm code to take the policy charm into account when compiling the relation data and rendering the HAProxy config.
This is because the haproxy-route relation is decoupled by design, and information from different relations cannot be grouped and sent over a single relation like in the dns interface and the http-proxy interface. The haproxy-route interface is designed this way because the modelling of the haproxy-route relation data is more complex than in the other two interfaces, and mapping each relation to an HAProxy backend makes logical sense.
Alternatively, the policy charm could receive the haproxy-route relations from the requirers (See the Further Information section but this approach would require relocating all the existing relations to turn on/off the policy engine.Relation data flow between the policy charm and HAProxy
Below is a quick overview of the lifecycle of the relation data of the haproxy-route interface:
-
[requirer] [library] Data is validated on the requirer side and serialized into JSON before being put into the relation databag.
-
[haproxy] [library] Data is deserialized and validated separately for each relation
-
[haproxy] [charm code] Data from each relation is grouped together for further validation checking things like overlapping service name, port conflicts with TCP backends, etc.
-
[haproxy] [charm code] Data is transformed into HAProxy-specific language and prepared to be rendered in the Jinja2 templates
Here is the updated flow of the data when HAProxy is related to the policy charm
-
[requirer] [library] Data is validated on the requirer side and serialized into JSON before being put into the relation databag.
-
[haproxy] [library] Data is deserialized and validated separately for each relation
-
[haproxy] [charm code] Data from each relation is grouped together for further validation checking things like overlapping service name, port conflicts with TCP backends, etc.
-
[haproxy] [charm code] [haproxy-route-policy library] Data is transformed into HAProxy-specific language and sent over to the policy charm via the haproxy-route-policy relation.
-
[haproxy-route-policy] [library] data is deserialized and sent to the policy engine to go through the approval workflow
-
[haproxy-route policy] [charm code] Any entry that is approved is sent to HAProxy through the haproxy-route-policy relation
-
[haproxy] [charm code] Data of approved entries are deserialized and rendered to the Jinja 2 template
The haproxy-route-policy relation
As mentioned above, the data that the policy charm receives through the relation is the data that has been parsed from the raw haproxy-route application data into HAProxy-specific language, consisting of mainly Backend and Server objects. Both sides of the relation will have the same structure which is a list of Backend objects. On the requirer side the list of Backend represents the parsed data from the haproxy-route requirers, and on the provider side it’s the list of backend that has been approved by the policy engine.
Core logic of the policy charm
Let’s first take a look at what has been done previously for http-proxy-policy
-
The operator needs to create “rules” that will be used to evaluate the request
-
The requests are in a “Pending” state if no rules can be matched for it
-
Manually clicking on “Approve”/”Deny” in the web UI creates a rule for that specific request. For the first iteration we will create an ID match rule directly and for future iterations a prompt can be created to allow the user to modify the rule before creating it.
-
Generic rules can be added to automatically approve/deny requests
-
If a requirer removes the relation, the request will be deleted.
We will use the rules engine approach similar to what’s done in http-proxy-policy. One of the main benefits that the rules engine provides in the context of haproxy-route is for example the ability to automatically deny requests for any domain not supported by the charm.
Dataflow
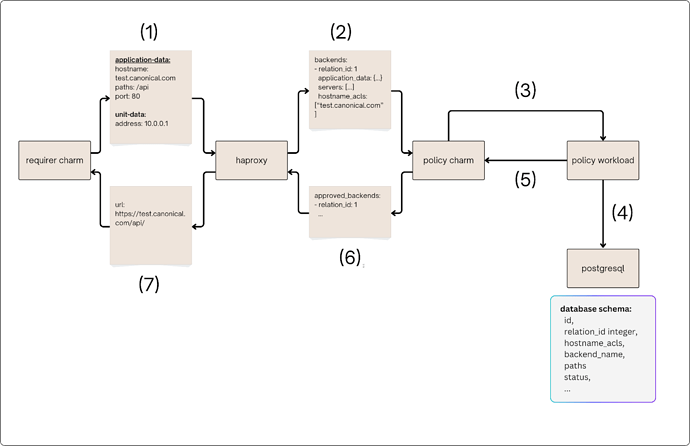
Below is a diagram showing the flow of a successful request from the requirer to being applied to the HAProxy config and an URL is returned in the context of a policy charm.
At (2), the HAProxy charm has transformed the raw haproxy-route relation data into a list of backend objects, and this list is sent to the policy charm via the haproxy-route-policy relation.
In the main policy logic, which consists of step (3), (4) and (5) the policy charm extracts the relevant information from the backend object such as hostname_acls, paths, etc … and sends them to the policy workload via API requests. At this level, the requests are matched with predefined rules to determine its status and then stored in a postgresql database. Rules matching happens immediately in the context of the request and the list of approved requests is returned in the API response.
At (6), for each request that is approved, the charm will match the approved request to the full data in the haproxy-route-policy relation data and set it under the “approved_backends” attribute.
Storage
Requests
Below is the postgresql schema for the backend_requests table. Aside from the metadata, uuid and status fields the schema contains information extracted from each Backend object in the relation data.
CREATE TYPE request_status AS ENUM('pending', 'accepted', 'rejected');
CREATE TABLE backend_requests (
id SERIAL PRIMARY KEY,
relation_id integer,
hostname_acls NOT NULL TEXT[],
backend_name NOT NULL TEXT,
paths NOT NULL TEXT[] DEFAULT [],
port int
status request_status NOT NULL DEFAULT 'pending',
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
Rules
Rules will be designed to be specific, in which case the logic of the rule is abstracted away in the code of the policy workload. For example, the rule “deny all requests that asks for example.com” can be represented by:
{"kind": "hostname_and_path_match", "value": {"hostnames": ["example.com"], "paths": []}, "action": "deny"}
Exact match through uuid ( request ID ) can be created when the administrator click on “Allow”/”Deny” for pending requests in the web UI:
{"kind": "match_request_id", "value": "<id>", "action": "deny"}
More rules can be added as the workload gets developed. Adding a new rule generally means implementing the matching logic for that rule in the policy workload, no change should be needed for the database schema.
For future iterations this will also leave room for the operator to define their own custom rules by writing python code.
Rule priority
For the first iteration, rules will have 1 of 2 possible actions: deny and allow and they will have a priority assigned to them which will be a positive integer. Rules will be evaluated following these 2 main principles:
P1: Rules with the same priority will be evaluated together, starting with the rules that have the highest priority
P2: “Deny” rules have priority over “allow” rules if they have the same priority
For example, for the following batch of rules:
| Rule | Kind | Value | Action | Priority |
|---|---|---|---|---|
| # Rule 1 | hostname_and_path_match |
{"hostnames": ["example.com"], "paths": []} |
deny |
0 |
| # Rule 2 | hostname_and_path_match |
{"hostnames": ["example.com"], "paths": ["/api"]} |
allow |
0 |
| # Rule 3 | hostname_and_path_match |
{"hostnames": ["example.com"], "paths": ["/client"]} |
allow |
1 |
A request for "example.com/client" will be allowed, while a request for "example.com/api" will be denied
The updated postgresql schema would be:
CREATE TYPE rule_action AS ENUM('allow', 'deny');
CREATE TABLE rules (
id uuid DEFAULT gen_random_uuid(),
type TEXT NOT NULL,
value JSONB NOT NULL,
action rule_action,
priority int,
comment TEXT
);
Interfacing between the policy workload and charm
For http-policy and dns-policy, both use a timer and create a systemd service to send out custom events when there has been an update on the workload side. The HAProxy policy charm will also follow this method.
REST API
The application will expose the following endpoints:
| Method | Endpoint | Description |
|---|---|---|
| GET | /api/v1/requests?status=<status> |
List all requests, with an optional query parameter. |
| POST | /api/v1/requests |
Bulk create and evaluate requests |
| GET | /api/v1/requests/<id> |
Get a request by ID. |
| DELETE | /api/v1/requests/<id> |
Delete a request by ID. |
| POST | /api/v1/requests/<id>/allow |
Allow a request. |
| POST | /api/v1/requests/<id>/deny |
Deny a request. |
| GET | /api/v1/rules |
List all rules |
| GET | /api/v1/rules/<id> |
Get a rule by ID |
| POST | /api/v1/rules |
Create a rule |
| PUT | /api/v1/rules/<id> |
Update a rule |
| DELETE | /api/v1/rules/<id> |
Delete a rule by ID |
Exposing the web UI
The policy charm will automatically add information to expose the web UI on its side of the haproxy-route-policy relation. This will live under a separate attribute than the normal backends. An example can be found below:
application-data: {
"approved_backends": [...],
"policy_backend_port": 8000
}
unit-data: {
"haproxy-route-policy": {
"address" "10.0.0.1"
}
}
Only the port and the unit addresses are given through the relation data, and the HAProxy charm will generate a path ACL for the policy backend in the form of model_name-app_name.
This will be the only ACL that is used to route traffic to the policy backend. This means that if the HAProxy charm has not set the external_hostname config option, the policy web UI will be accessible through the IP address of the HAProxy charm units.
http://<haproxy_unit_ip>/model_name-app_nameIf another backend is present ( which means that TLS redirection is enabled, the scheme will be https:
https://<haproxy_unit_ip>/model_name-app_nameIf haproxy is configured with a virtual IP, then the web UI is also accessible via the virtual IP address:
https://<virtual_ip>/model_name-app_name
Further Information
-
[ISD198 - DNS policy app - Internal]
-
Requests are manually approved, clicking on “Approve”/”Deny” will call an API to modify the status of the request directly in the database.
-
Requests are identified by an “UUID”, updating the relation data will actually create a new request with a different UUID, which will need to be approved again.
-
Currently, requests cannot be updated.
-
If a requirer removes the relation, the request will be deleted.
-
Other approaches considered for rules design
A generic approach would be to represent a rule as a list of objects ( field, op, value ). This means that for a rule such as “deny all requests that asks for example.com”, the object would be something like this:
{"rules": [{"field": "hostname_acls", "op": "contains", value: ["example.com"]}], "action": "deny"}
Additional clarification on spec rationale
- (1): detecting conflicts (for paths and hostnames) automatically is hard because:
- paths can have different depths ( for example /v1/api and /v1 will route everything to /v1 if the “use_backend” for /v1 is placed in front. ).
- Hostnames can have wildcards ( .* )
- Routes are determined by a combination of paths + hostnames so the previous 2 points I mentioned needs to be taken into account together and for each backend. For example, one backend might request hostname=.example.com, paths=/v1/api. And another might request hostname=.first.example.com, paths=/v1,/v2, and the third might do hostname=canonical.com, paths=/v1/api, etc … Detecting conflicts quickly become a mess in that case
- (3) and (4): something like paths=/v1/api,deny_paths=/v1 for example is technically valid syntax for haproxy config but won’t work for obvious reasons. Another example would be requirers setting invalid addresses for the backend servers, syntactically it’s correct even if the backend server IP is unreachable.