
Abstract
This specification proposes support for reactive scheduling of Github’s self-hosted runners to better meet user needs.
Rationale
Currently, the Github runner charm is used with a set of configured runners of a given flavour. The number of runners configured by flavour does not necessarily match the needs of users. In order to use the underlying infrastructure as efficiently as possible, and to meet user demand, a more reactive approach to determining how many runners to spawn for a flavour will be implemented.
Specification
GitHub provides the ability to receive notifications from webhooks containing the requested labels for self-hosted runners in the workflow_job event. The requested jobs can then be used to determine the number of runners to be spawned by flavour.
The high-level idea would be to add the flavour matching these labels from these received webhooks to a message queuing system, which could then be accessed by a charm to decide the number of runners to spawn. This is shown in the diagram below:
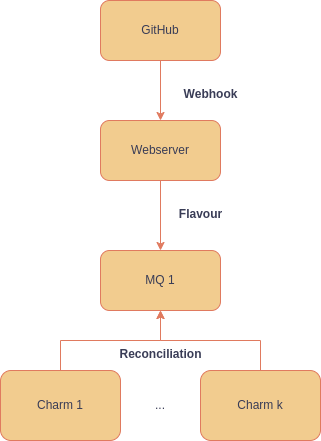
The webhook sent from GitHub would be received by a web server, which would add the extracted flavour to a message queue. On reconciliation, each charm would consume the matching flavour requests from the queue and adjust the reconciliation accordingly. The details and necessary adaptations are outlined in the following subsections.
Webhook Router
A web server needs to be written that accepts incoming webhooks and distributes these accordingly to the message queue.
The main logic would be to parse the labels from the webhook using the workflow_job event if the event contains the label self-hosted and if the action type is queued, i.e. the job is waiting to be picked up by a runner, and enqueue a message containing the flavour, labels and run url into the MQ system.
The flavour is used to determine which type of runner should be spawned for the job, the labels are used when spawning the runner and the run url can be used to interact with the Github API to get the current status of the job.
In the first iteration of implementing reactive scheduling, we retain the approach of predetermining a flavour at deployment time, which means that the flavour is actually the name of a particular Github runner charm application. Messages can be queued in a separate queue per flavour.
The web server needs to map the labels to a particular flavour, which is currently defined as a particular Github runner application. So it needs to know which flavours exist, and which flavour should be the default if a user does not specify a particular flavour. Furthermore, the charm needs to know the message queue URI. Therefore, the following configuration needs to be provided
flavors = ("small", "large" , "edge", ...)
default_flavor = "small"
queue_uri = "uri_queue_1"
Note that a user may specify invalid label combinations (e.g. “large” and “small”) in their workflow file. This could result in unprocessable messages in the queue, so the label combinations need to be validated as much as possible and not forwarded if they are found to be invalid.
We pass the labels of the current webhook along with the message to delegate further validation to the runner manager consuming a message.
Below is a sample snippet from a Flask application that demonstrates the high-level idea:
from flask import request, app
from message_queue import publish_message, consume_message
from exc import MultipleFlavorError
from config import load_clouds, flavors, default_flavor
CLOUDS = load_clouds()
def translate_to_flavor(labels):
flavor = None
for label in labels:
if label in flavors:
if flavor is not None:
raise MultipleFlavorError
flavor = label
if flavor is None:
return default_flavor
return flavor
@app.route('/webhook', methods=['POST'])
def handle_github_webhook():
payload = request.get_json()
action = payload["action"]
if action == "queued":
labels = payload["workflow_job"]["labels"]
flavour = translate_to_flavor(labels)
run_url = payload["workflow_job"]["run_url"]
msg = {run_url: run_url, labels: labels}
publish_message(msg, cloud, flavour)
return '', 200
It is also recommended to use secrets for the webhooks to validate that they are coming from GitHub. The charm needs to be adapted to include a configuration option for such a secret (similar to the token used by the runner to register) and to validate it for each webhook accordingly.
In addition, in order to provide a stable public IP, the charm needs to be adapted to provide ingress integration, so that it can be integrated with an ingress charm such as traefik or nginx-integrator.
Message Queue
Unfortunately, there aren’t a lot of up-to-date charmed message queue systems available at the moment. So we decided to use MongoDB as the underlying technology for the message queue system, as there is a pretty modern machine charm available with a quite recent version of MongoDB.
To be as technology agnostic as possible in the code, and to use typical message queue functionality as provided by RabbitMQ, we decided to use kombu as the message library. Kombu emulates AMQP behaviour for non-AMQP based technologies.
The charm needs to be adapted to support the mongodb_client interface.
Charm adaption
Reconciliation adaption
A charm unit should, if reactive scheduling is desired per config option, change the reconciliation to dynamically match the number of jobs available in the message queue for that flavour. The virtual machine option should be interpreted as the maximum number of virtual machines that can be spawned.
Since we’re using a message queue with a (virtual) AMQ protocol, unacknowledged messages will be requeued into the queue. If the connection to the message queue is lost, the messages are also requeued. To ensure that a job is actually handled by a spawned runner, we have to wait for a runner to be spawned and for the job to be picked up. This can take some time and we need to decouple it from the reconciliation event (blocking the reconciliation event would basically block the juju event queue and might interfere with the following scheduled reconciliation event). Therefore, consuming a message should be done in a separate process using a script.
The script would be spawned up to the number of virtual-machines and would have the following logic
- Get or wait for the next message from the queue.
- Check to see if it’s possible to spawn the job at all (if the requested labels match the ones of the runner manager) and otherwise reject the message and requeue. Another runner manager might be able to spawn it, and if not, the job will likely get cancelled in the future and be removed from the queue by step 3.
- Use the run-url and the github token to check if the job has already been started (this may be the case as we cannot ensure a 1:1 mapping between runners and jobs) or completed (may happen if the job has been cancelled). If it has, acknowledge the message and return.
- If it has not yet started, spawn a runner. This may not work, e.g. due to capacity problems. Then reject and requeue.
- If spawning works, retry a certain number of times to see if the job has started (see point 2), and if so, confirm and return, otherwise reject and quit.
Following code using kombu should illustrate the high-level idea
import argparse
import logging
from time import sleep
from kombu import Connection
import requests
from somewhere import spawn_runner, SpawnError, validate_labels
logger = logging.getLogger(__name__)
def check_job(run_url):
run = requests.get(run_url).json()
return run["status"] == "in_progress" or run["status"] == "completed"
def consume(mongodb_uri):
with Connection(mongodb_uri) as conn:
with conn.channel():
simple_queue = conn.SimpleQueue('simple_queue')
try:
message = simple_queue.get(block=True)
if not validate_labels(message["labels"]):
logger.error("Cannot spawn a runner with these labels")
simple_queue.reject(message, requeue=True)
return
if check_job(message["run_url"]):
simple_queue.ack(message)
return
try:
spawn_runner()
except SpawnError as e:
logger.error("Cannot spawn a runner due to %s", e)
simple_queue.reject(message, requeue=True)
return
for _ in range(10):
if check_job(message["run_url"]):
simple_queue.ack(message)
break
sleep(30)
else:
simple_queue.reject(message, requeue=True)
finally:
simple_queue.close()
if __name__ == '__main__':
argparser = argparse.ArgumentParser()
argparser.add_argument("--mongodb", help="mongodb url")
args = argparser.parse_args()
consume(args.mongodb)
We cannot guarantee a 1:1 mapping of runners and jobs, and it is also possible that there are other runner assignments outside of reactive scheduling, so it is possible that we have spawned unnecessary runners during a reconciliation. To mitigate this, the charm should check at the start of the reconciliation loop if the queue is empty, meaning that no runners need to be created for that particular flavour. If there are still idle runners, they should be removed, and spawning of additional runners during this cycle should be skipped. Note that there may be a race condition: A script from the previous reconciliation event may have just created a runner for a very recent job. To avoid removing this runner, a grace period should be considered (e.g. remove the runner only if it is older than x minutes).
Also note that the code snippet is very simplified - kombu emulates the acknowledgement mechanism that is normally implemented on the server side (e.g. in RabbitMQ). This means - if the process is killed by a signal like SIGKILL, all unacknowledged messages might get lost. To handle most signals, it may be necessary to implement a signal handler that restores the unacknowledged messages.
There is also an issue that Kombu does not necessarily requeue jobs to the end of the queue. This issue needs to be addressed as a matter of urgency, as it means that jobs that cannot be spawned by a particular runner manager may have a significant delay in being picked up. This issue is already mitigated by using a queue per flavour, but can still arise due to additional labels.
E.g. if a job is labelled “arm64” and the runner manager that consumes it does not support spawning arm runners, it may take some time for an arm runner to be spawned.
COS integration
The current COS integration should not be affected as most metrics are calculated/extracted at reconciliation and the basic reconciliation loop is not affected (See [specification] ISD075 GitHub Runner COS integration) for more details on COS integration). The spawned scripts which consume messages from the message queue still can issue the runner installed event by appending the event to the log file.
Reconciliation
In addition to the current behaviour, the spawned scripts which consume messages from the message queue should create an error event if the message queue could not be contacted.
In addition to the number of idle runners, the number of active runners should be added to the reconciliation event, as the number of idle runners in the reactive case is ideally zero and does not accurately reflect the current use of runners.
Web server
The web server discussed above should export basic http prometheus metrics. Instrumentation could be done using a library such as Prometheus Flask exporter. The scrape configuration within the cos agent configuration would need to be adapted to scrape the exporter.
In addition, the web server should log application-specific metrics such as
- the number of jobs received for particular labels - distinguished by the status (queued,in_progress,completed)
- the number of jobs forwarded to a particular queue
- the number of jobs that cannot be forwarded due to invalid labels
- the number of times a job could not be forwarded due to a connection error with a message queue
Every received webhook should be logged to a log file so that it can be passed to Loki and the order of webhooks received can be analysed for troubleshooting purposes.
Alerts
- Errors in contacting the message queue should be logged and appropriate alerts should be defined.
- An alert should be issued for a high rate of jobs not being forwarded due to invalid labels, as this may indicate a user information error.
Discussion
Multiple flavour support
The current architecture predetermines the flavour a charm can spawn at deployment time. This is not flexible enough, nor is it very useful when using LXD VMs for runners, as the machine containing the LXD VMs is pre-allocated and could therefore also just directly spawn a maximum number of runners that the machine can hold, rather than using reactive scheduling.
In a future step, the charm needs to be adapted to support multiple flavours for a particular deployment, and the reactive scheduling mechanism should be adapted to support this.
Reduce job queue duration by pre-spawning runners
In order to reduce the duration of a job in the job queue (runner installation on LXD currently takes 2.5 minutes), it should be ensured that there is always a pre-set of idle runners for the most requested flavours.
This could be achieved by using a set of runner deployments without reactive scheduling.
Prespawning runners also makes the system more robust against webhook delivery failures. This was experienced by the author prior to writing the specification, where a webhook might not be sent at all.
If Github fails to send the webhook for a newly created job, that job will still be waiting for a runner to pick it up. Since the system has not received a webhook, it would not spawn a runner. If there is already a pre-spawned runner, that runner can pick up the job. There is also a way to handle the redelivery of webhooks that have failed to deliver, which is discussed in a sub-section below.
Job allocation
When the charm is customised in this way, and there are pre-spawned runners, it is clear that there is no 1:1 mapping between runners and the jobs associated with the messages in the queue. This is also difficult to achieve, as we want to allow an arbitrary number of charm deployments without any central instance knowing which charm is currently processing which job. Beyond that, failures with a webhook or an unreachable queue can also hinder a 1:1 mapping of requested jobs and runners.
It should be sufficient, however, as resources are still used relatively dynamically according to the jobs requested, and idle runners that are no longer needed are scaled down accordingly, freeing up unnecessary resources.
Specifying no particular flavour
There is also a pitfall when users do not specify a flavour (e.g. just the label “self-hosted”). We would be spawning a runner without knowing what flavour of runner will be assigned to that job, as Github assigns a job to a runner which contains all of the labels requested (https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/using-self-hosted-runners-in-a-workflow#routing-precedence-for-self-hosted-runners )
This could mean that we spawn a runner that is not taken up at all, and have to respawn a runner for a different job. For example, suppose there are two incoming job webhooks, w1 specifies flavour large
and w2 specifies no particular flavour. We would spawn a large runner for w1 and say we have a default of small so a small runner for w2. As w2 did not specify a particular flavour, it could be that w2 is picked up by the large runner and the job requested by w1 is still queued. In this case,the job corresponding to w1 would have to wait for the next reconciliation to respawn a runner (the job message would be requeued into the message queue). If another webhook w3 comes in without specifying a flavour, this problem could repeat (we have no insight/control into how github assigns jobs to runners).
Note that this problem can happen without reactive scheduling as well, so it is not specifically related to it. You could try to work around it by instructing users to specify jobs as specifically as possible.
Externalisation of the runner manager
Since the runner managers will be adapted to contact the queue, this is a good indicator that the charm code has too many responsibilities and that the runner manager application should be outsourced.
Therefore, a new application should be developed that contains the current runner manager code. This application should probably be released as a snap and installed by the charm.
Further Information
There is documentation on GitHub about autoscaling, which also suggests using webhooks: https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/autoscaling-with-self-hosted-runners
There is also an operator for Kubernetes that is recommended by GitHub: https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners-with-actions-runner-controller/about-actions-runner-controller .
Furthermore, there is another project by Canonical that tries to redesign our operator using the source code of the aforementioned operator: https://github.com/canonical/ngrm . This project would also solve the problem addressed by this spec.