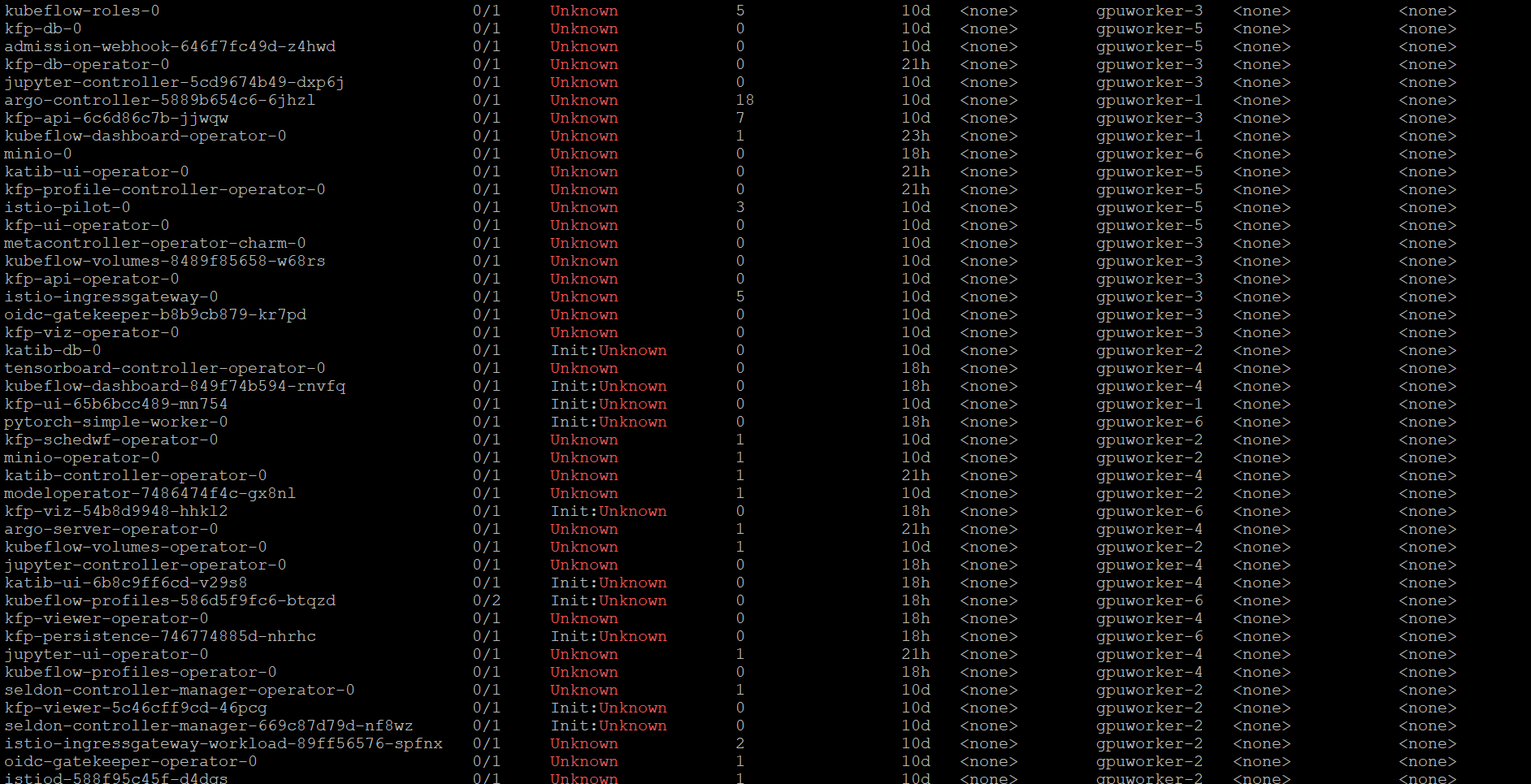
I have a 6 node Microk8s cluster with charmed kubeflow deployed.
I performed some network maintenance which meant the VMs with Microk8s were briefly disconnected for around 5 minutes from the network. After this they had some connectivity issues so I restarted the nodes. After restarting all 6 nodes Microk8s comes up succesfully and forms a quorum yet everything deployed in the Kubeflow namespace has an Unknown state. I’ve seen some old articles from 2019 where users where having a similar issue but it was patched so keen to see if anyone has any suggestions.
In the log report I see that the performance of the disk is not great and this causes the k8s services to give up. See for example:
Sep 23 09:25:51 gpuworker-1 microk8s.daemon-kubelite[1475]: Trace[562495236]: ---"Object stored in database" 8120ms (09:25:51.360)
Sep 23 09:25:51 gpuworker-1 microk8s.daemon-kubelite[1475]: Trace[562495236]: [8.120782622s] [8.120782622s] END
Sep 23 09:25:51 gpuworker-1 microk8s.daemon-kubelite[1475]: F0923 09:25:51.363899 1475 server.go:213] leaderelection lost
Sep 23 09:25:51 gpuworker-1 systemd[1]: snap.microk8s.daemon-kubelite.service: Main process exited, code=exited, status=1/FAILURE
Sep 23 09:25:51 gpuworker-1 systemd[1]: snap.microk8s.daemon-kubelite.service: Failed with result 'exit-code'.
Sep 23 09:25:51 gpuworker-1 systemd[1]: snap.microk8s.daemon-kubelite.service: Scheduled restart job, restart counter is at 1.
It took k8s 8 seconds to persist something on the datastore. If the performance of the storage substrate is acceptable, is it possible there are I/O heavy workloads present?
There appear to be no performance issues on the VM’s disk:
ubuntu@gpuworker-1:~$ dd if=/dev/zero of=./test.img bs=1G count=1 oflag=dsync
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.48401 s, 432 MB/s