
Kubeflow is an open source, cloud-native platform designed to simplify, orchestrate, and scale machine learning (ML) workflows. Built entirely on Kubernetes, it acts as a comprehensive toolkit for MLOps, bridging the gap between data science experimentation and production engineering.To handle the different stages of the ML lifecycle, Kubeflow integrates several open source components into a highly modular platform:
-
Kubeflow Notebooks: Provides web-based development environments inside a cluster, natively supporting JupyterLab, VS Code, and RStudio.
-
Kubeflow Pipelines (KFP): A platform for building and deploying end-to-end, portable, and reproducible ML workflows.
-
Kubeflow Trainer: Handles distributed training and fine-tuning for large models (including LLMs) across frameworks like PyTorch, TensorFlow, and JAX.
-
Katib: An automated ML (AutoML) engine used for hyperparameter tuning and neural architecture search.
-
MLFlow: A model registry to store and versions trained models (alongside their parameters and metrics) as well as ML experiments
-
KServe: A highly scalable, multi-framework platform for model serving and generative/predictive AI inference.
Deploying and integrating all these components while leveraging cloud-native architectures is no small feat. Over the past few months, the engineering team has worked relentlessly to make the experience of deploying Kubeflow on Azure Kubernetes Service (AKS) as seamless as possible. Today, with its integration into the Azure Marketplace, deployment is only a few clicks away. Canonical Managed Kubeflow on Azure is now available on the Azure Marketplace, making it easier to deploy and manage Kubeflow at scale.
In this post, we take a deeper look into the architecture of the managed offering for Canonical’s Charmed Kubeflow, describing the various layers from the infrastructure stack up to the application layers. We have organized the presentation into three sections: we will start with the Foundation to dive into the underlying infrastructure. We will then progress to describe the true Enabler for the implementation of data-analytics and modelling pipelines: the Kubeflow platform. And finally we will focus on how users (you!) can leverage the platform and deliver Value using Kubeflow. We will explore what happens in the background when a new deployment of Charmed Kubeflow on Azure is triggered.
The Foundations: infrastructural layer
Azure Kubernetes Service
At the foundational runtime layer sits Azure Kubernetes Service (AKS). Kubernetes serves as the ideal orchestrator for modern AI infrastructure because it natively abstracts heavy-duty compute pooling, network scaling, and containerized scheduling. By deploying our MLOps orchestration engine directly on AKS, the architecture inherits native horizontal scalability, elasticity, and direct interaction with cloud infrastructure resources.
To maximize cost efficiency and performance, our offering supports the configuration of heterogeneous worker pools, so that platform administrators can seamlessly provision and mix varied hardware architectures. When allocating heterogeneous worker pools, it is important to bear in mind the type of workloads that will run on the Kubernetes cluster:
-
Platform control plane, where all the various services required to have a fully functional MLOps platform are executed
-
User worker pools, where the various user jobs are executed (e.g. notebooks, pipelines, model training, etc). Being able to use different architectures (such as AMD or ARM) or accelerations (such as CPU-optimized and GPU-accelerated node pools), will ensure that each stage of the machine learning lifecycle runs on its ideal underlying infrastructure.
When creating a Managed Solution offering for Charmed Kubeflow, the user can configure how many worker pools are to be used, allowing the selection of the type of nodes to be used by each worker pool, thus ensuring flexibility and cost-effectiveness. Each worker pool will also be able to automatically scale up or down, such that when using expensive hardware you will only be spinning resources as long as it is required by your workloads and data-pipelines.
The Operational Engine: A Deep Dive into the Juju Control Plane
To understand how this reference architecture overcomes the operational burdens of managing all the various components that make up the Charmed Kubeflow platform, it is essential to look closely at its central management engine: Juju.
What is Juju and What Does It Do?
Juju is an open source, model-driven orchestration engine and control plane framework developed by Canonical. Unlike traditional infrastructure tools that treat software deployment as a static, one-time configuration event, Juju is designed to manage the entire runtime lifecycle of complex solutions, made of multiple application suites.
Architecturally, Juju splits its responsibilities into two distinct concepts:
-
The Juju Controller: The centralized brain of the control plane. It provisions the required resources, maintains the state of the environment, orchestrates changes, and monitors the health of the system.
-
Charms (Software Operators): Open source, platform-agnostic software components that embed operations logic into runtime packages. Charms act as “digital site reliability engineers (SREs),” translating high-level architectural intentions into local operational actions.
Within this specific architecture, Juju is the critical component that drives the lifecycle of all other application services running inside Kubernetes. It is important to emphasize that Juju’s capabilities extend far beyond initial provisioning or automated deployment. Its real value lies in solving two of the hardest problems in modern infrastructure engineering:
-
Service integration: Standard cloud-native configurations require engineers to manually copy secrets, update environment variables, and map endpoint ports across microservices. Juju replaces this manual plumbing with declarative Integrations (also referred to as Relations). For example, when you integrate the MLflow charm to the MySQL database charm, Juju automatically handles database creation, user provisioning, credential sharing, and network routing in the background without manual intervention.
-
Automated Day-2 operations: Once software is deployed, it must be maintained. Juju charms codify complex operational procedures directly into scripted runbooks. Maintenance tasks like certificates rotations, backup and restore procedures, upgrades, etc are executed reliably via standard Juju Actions.
Architectural Layout: Split Control Plane Design
The physical topology of Juju within this MLOps solution follows a strict separation of concerns, designed specifically to safeguard production uptime and maximize computing efficiency.
In this reference architecture, we chose to run Juju controllers on independent, external infrastructure nodes (independent VMs) outside of the main Kubernetes cluster. From this external, isolated vantage point, the Juju controller securely communicates with the cloud control plane. It continuously watches, communicates with, and manages all of the individual Charms that are running directly inside Kubernetes. The charms execute inside the cluster alongside their respective applications (such as Kubeflow Pipelines, KServe, and MLflow), translating commands from the external controller into immediate Kubernetes API instructions (like spinning up pods, establishing services, or attaching volume claims).
This split-plane design provides distinct enterprise advantages:
-
High Reliability: If the Kubernetes worker nodes experience intense resource starvation during a massive distributed deep learning training job, the Juju control plane remains completely unaffected, responsive, and available to remediate the cluster state.
-
Hard Operational Boundary: Infrastructure administrators retain a secure, standardized management perimeter outside of the active data science workspace, preventing developers or pipeline errors from accidentally modifying or destabilizing the foundational deployment engine.
When deploying Canonical’s Managed Kubeflow on Azure, you can decide whether the Juju control plane needs to be highly available. If you select this option, three VMs will be deployed and Juju controllers will be installed on them. If you de-select the highly available check box, Juju will run in a single VM. Given how critical Juju is for driving the system, we recommend running in high-availability mode, especially for production environments where uptime requirements and reliability are more critical.
The Enabler: MLOps platform
Once we have set up the K8s infrastructure as well as the Juju control plane connected to it, we can use the latter to drive the deployment of every single other service on top of Kubernetes. There are three kinds of service layers in the Charmed Kubeflow solutions:
-
Platform Layer: Provides general functionality, such as authentication and cluster communication management.
-
Data Layer: Includes stateful components responsible for storing data securely and reliably.
-
Core MLOps Layer: Provides specific data analytics functionality (e.g., Notebooks, Katib, KFP, MLFlow, Trainer, and KServe).
Let’s see more in depth what these layers consist of.
Platform Layer
Beyond the core analytics components, operating a corporate platform requires robust capabilities to ensure enterprise-grade authentication, isolation, and governance. Specifically, two critical functionalities are provided:
-
Authentication Layer, responsible for managing and validating the requests/access to the Kubeflow cluster
-
Service mesh layer, responsible for routing and managing the various requests between services and also from the outside
As you may imagine, the two layers also integrate with one another in order to make sure that requests – both coming from outside and inside the cluster – are correctly authenticated, and validated. But let’s look deeper into these two services.
Authentication Layer (Dex IdP + OIDC Client)
User management and authentication are orchestrated via an OIDC client that intercepts incoming requests, validates them by verifying that they are correctly authenticated (if they need to be) or – if not – forwards the user to the Identity Provider (IdP) to perform the authentication. The Kubeflow solution integrates Dex IdP that exposes a single OpenID Connect endpoint, that can be integrated with a number of external Identity providers (such as Azure, Google, SAML, LDAP), thus providing a single authentication layer agnostic on the backend Authentication layer being used. The Charmed Kubeflow solution allows you to configure the Authentication backend in the step-by-step deployment process under the “Access” tab, by configuring the integration with an external OIDC provider. To do so, just register an application in an OIDC provider (such as Azure EntraID, Auth0, Okta, etc) and then configure the Authentication layer by providing:
-
Client-id, the identifier of the OIDC application
-
Client-secrets, an access secret generated by given OIDC application and required to connect to it
-
OpenID Connect endpoint, that will be used when redirecting unauthenticated requests
The external OIDC application will also need to be configured with the redirect URI, namely the endpoint in the Kubeflow dashboard where the user will be redirected upon successful authentication. When a user logs into the platform, the OIDC flow triggers, the user is authenticated and its memberships are resolved, so that the user can be granted access to their dedicated namespaces.
Service Mesh: Istio
To secure intra-cluster microservices communications and manage traffic routing, Charmed Kubeflow ships with Istio, which is a component that provides Service Mesh capabilities. In short, Istio is a framework that allows to build additional layers of security/authorization by intercepting the various requests and communications between microservices, modifying the request (e.g. by encrypting traffic or implementing mutual TLS between services) such that additional authorization layers can be implemented, e.g. by only allowing traffic between selected components.
To manage service-to-service traffic in the so-called `sidecar` mode, Istio deploys a high-performance proxy – an Envoy proxy – directly alongside every single application container within the exact same Kubernetes pod. Whenever a pod is created, a mutating admission webhook automatically injects this “sidecar” proxy and configures local firewall rules (iptables) so that all incoming and outgoing network traffic is intercepted by Envoy before reaching the actual application code. Because the proxy intercepts all data plane traffic, it allows Istio to enforce security rules like mutual TLS (mTLS), apply advanced traffic management patterns like canary routing and load balancing, and generate deep observability metrics across the cluster – all entirely transparently to the application itself, without requiring developers to change a single line of their code. In the current Charmed Kubeflow distribution, side-car containers are only applied to all user workloads spawned on the Kubeflow cluster, thus injecting a secure layer and an isolation between user workloads.While sidecar mode provides robust service mesh capabilities, it also introduces significant operational challenges, as,for instance, it requires application teams to restart their workloads just to update the mesh information (e.g. certificates), and generally creates larger resource overhead, especially in lightly used clusters. More recently, the Istio project has solved these pain points by centralizing the component that intermediates the traffic into a shared, node-level ztunnel for lightweight L4 security and independent Waypoint proxies for L7 traffic routing, which eliminates the need of the side-car container. Although Ambient mode is not yet supported by Kubeflow upstream, in the past few months we have been integrating as experimental into Charmed Kubeflow. However, since this is not yet GA, this feature is currently not part of the Canonical’s Managed Kubeflow yet, but please stay tuned for this exciting change in an upcoming release.
Data Layer
Machine learning pipelines require distinct database boundaries to capture operational states, system metadata, and raw binary artifacts natively. In particular, Kubeflow generally requires two different types of storage:
-
Relational database, that is generally used to store structured data
-
Object storage, that is generally used to store unstructured data
Let’s see what is used for what.
Relational Engine: MySQL
As the backend for relational data, the Kubeflow distribution uses MySQL, which is one of the most widely deployed database technologies in the world, that is able to provide full ACID (Atomicity, Consistency, Isolation, Durability) transaction support, row-level locking, and crash-recovery capabilities. Because of its high performance, reliability, and ease of scaling, MySQL has now become a foundational pillar in many applications, and as such, its charmed operators is a well-established component that backs a number of Canonical products, also able to provide robust and production-ready features for complex operations, such as rolling upgrades that ensure uptime as well as well-tested backup/restore/recovery operations.
Within the Kubeflow ecosystem, MySQL is generally used as the physical storage layer for recording execution logs, parameters, pipeline run statuses, and artifact tracking data as well as storing essential metadata for the Kubeflow Pipelines (KFP) API server, Katib hyperparameter trials, and MLFlow artifacts metadata (e.g. model name, parameters, metrics, etc). By keeping this relational metadata highly organized and indexable, MySQL ensures that the platform can instantly query pipeline history, track experiment lineages, and maintain cluster-wide operational consistency at all times.
Object Storage: MinIO
While MySQL is used for all structured data, all non-relational unstructured data, such as model binaries, training logs, and runtime pipeline artifact steps, are routed directly to an object storage backend. To store these artifacts, the Charmed Kubeflow solution employs MinIO, which provides an S3-compliant object storage endpoint within the cluster boundary. Even keeping data within the cluster boundaries is not a requirement, note that MinIO can also work in gateway-mode, thus proxying the various requests to an external object storage backend, which is externally managed. This option is not yet configurable out of the box in Canonical’s Managed Kubeflow, as this generally requires further configuration and integration between components, but get in touch with us if you have such a need.
Core MLOps Layer
Above the Platform layer and the Data Layer lives the core MLOps platform layer, that is composed of all of the user-facing tools that allows data scientists and data engineers to interact with datasets, build pipelines, train models, and manage live inference endpoints. To allow users to perform all these tasks (required when building data science pipelines end to end), the Kubeflow platform integrates several microservices – both including backend components and frontend components – that ultimately make up the Kubeflow control plane. All of these services are deployed in the same namespace and they are tightly connected to one another. The following schema shows an overview of the various sets of services and their integration in the MLOps lifecycle. In the following sections we will briefly discuss each component.
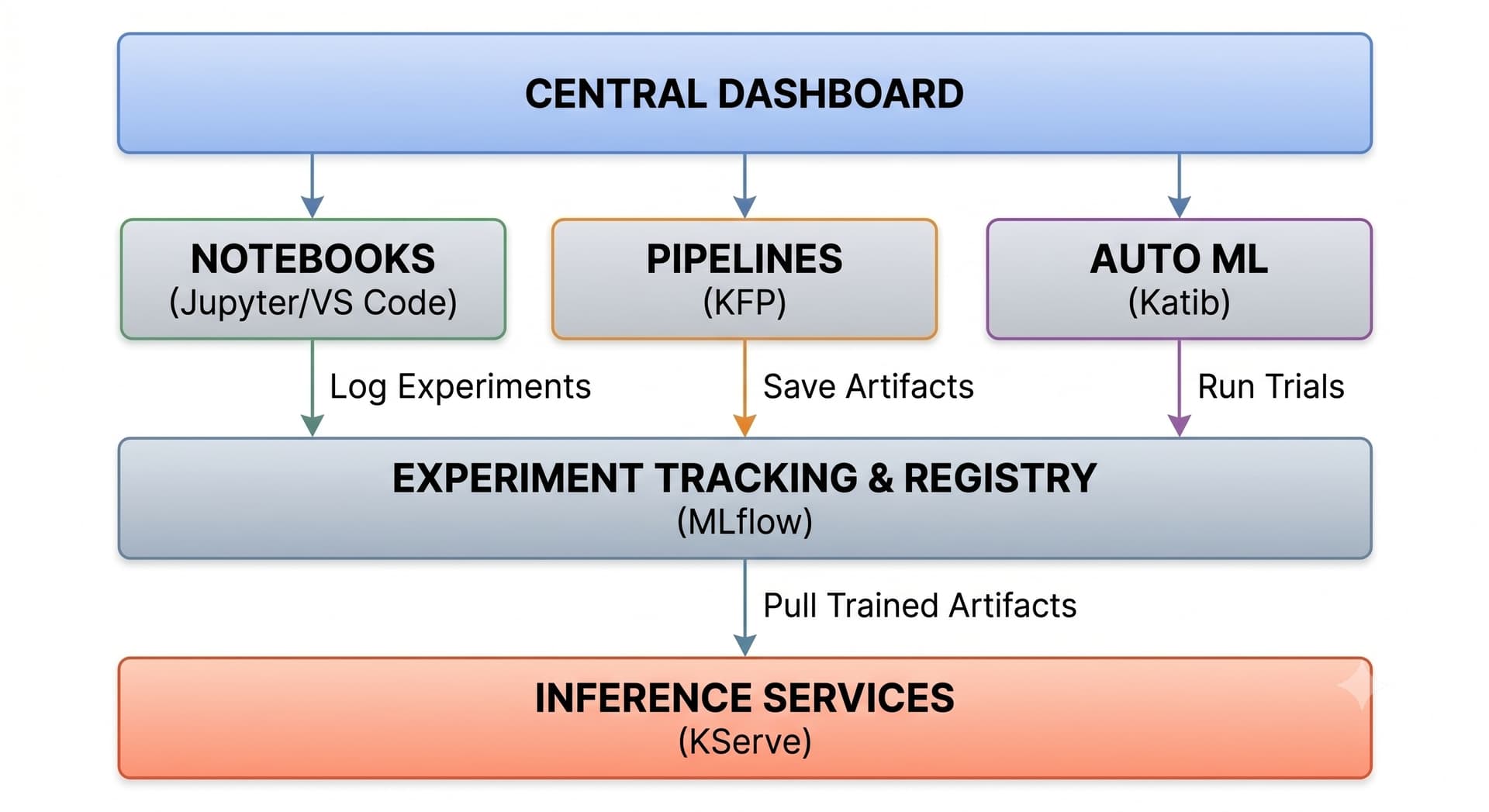
Central Dashboard & Notebook Servers
The Central Dashboard provides a single multi-user login portal. From here, practitioners spin up web-based development environments running JupyterLab or VS Code notebook servers on-demand. Each notebook runs inside a stateful Kubernetes pod, mounted to a dedicated Persistent Volume Claim (PVC) that acts as the user’s secure home directory.
Pipeline Orchestration: Kubeflow Pipelines (KFP)
The Kubeflow Pipelines (KFP) core engine allows data engineers to package machine learning workflows into repeatable components structured as a Directed Acyclic Graph (DAG). When a pipeline executes, the KFP API server translates each node in the graph into an asynchronous container execution step running inside a dedicated pod, ensuring fully auditable and scalable metadata tracking.
Training at scale: Kubeflow Trainer and Katib for AutoML
Kubeflow also provides Kubernetes-native platform components specifically engineered to orchestrate large-scale machine learning model training and LLM fine-tuning, by leveraging on two strategic components: Kubeflow Trainer and Katib. Rather than forcing data scientists to manually manage complex training procedures to leverage on a multi-node and horizontally scalable infrastructure, these components abstract distributed training frameworks into declarative Kubernetes Custom Resources that express the goals of the training.
For instance, under the hood, the Kubeflow Trainer controller automatically coordinates pod allocation, configures master/worker network rings, injects environment variables for distributed libraries (like DeepSpeed, Megatron-LM, or Hugging Face), and handles fault tolerance across high-performance GPU and CPU worker pools. Similarly, the Katib controller efficiently manages the hyper-parameter optimization for Machine Learning models on a Kubernetes cluster by independently scheduling and planning trials and experiments for optimizing a given object function over a user-defined parameter search space. By translating abstract data science jobs into robust, containerized scheduling matrices and job executions, Kubeflow Trainer and Katib allows teams to scale seamlessly from a single local experiment to heavy, multi-node distributed deep learning clusters and large scale parameters searches with minimal operational friction.
Experiment Tracking and Model Registry: MLflow
Rather than utilizing disconnected experiment systems, the application layer natively integrates MLflow. Through a background automated helper layer (the Resource Dispatcher), MLflow credentials and object store endpoints are automatically injected into active user profiles. Data scientists can track code metrics, capture parameter arrays during model tuning with Katib, and record final weights into a centralized, audited model registry.
Serverless Model Serving: KServe
When a trained model is ready for a production workload, it is packaged as an Inference Service Custom Resource via KServe. KServe maps the model artifact directly onto standard prediction runtimes, utilizing serverless components to execute automatic low-latency scaling – including scaling completely to zero when idle (when running in serverless mode) – and enabling progressive canary rollouts without dropping traffic perimeters.
The Value: user workloads
Finally, at the top of the stacks live the user workloads: the actual pods/processes owned by the users that implement the various data-analysis and modelling tasks. These workloads can be of various kinds:
-
Notebooks/VS Code kernels for interactive sessions
-
Standalone (generally) short-lived processes that are triggered either as part of KFP pipelines or as part of Training jobs
-
Long-lived inference services exposing Machine Learning and LLM models
These workloads live on a different Kubernetes namespace with respect to the platform services, and generally run on a dedicated set of worker pools so as to not conflict or starve resources for the platform components, thus avoiding instabilities in the operations of the core MLOps platform services. In the Managed Offering solution, you can decide how many worker pools you would like to use, thus also allowing you to customize your cluster with different architectures (AMD64/ARM64) and accelerations (e.g. GPU-accelerated hardware) to power your workloads.
Moreover, different users can also run their workloads on different namespaces. In fact, in Kubeflow, multi-tenancy and user isolation are governed by a core Custom Resource Definition (CRD) called a Profile. The concept of Profile ensures that data scientists can build, train, and deploy models within secure, self-contained project environments while maintaining strict separation from other users and system components, as each profile is associated with a different namespace. Multiple people can belong to the same Profile, and one user can also be added to different profiles at the same time, thus allowing Kubeflow administrators and Profile owners to manage different groups of users with a large degree of customization.
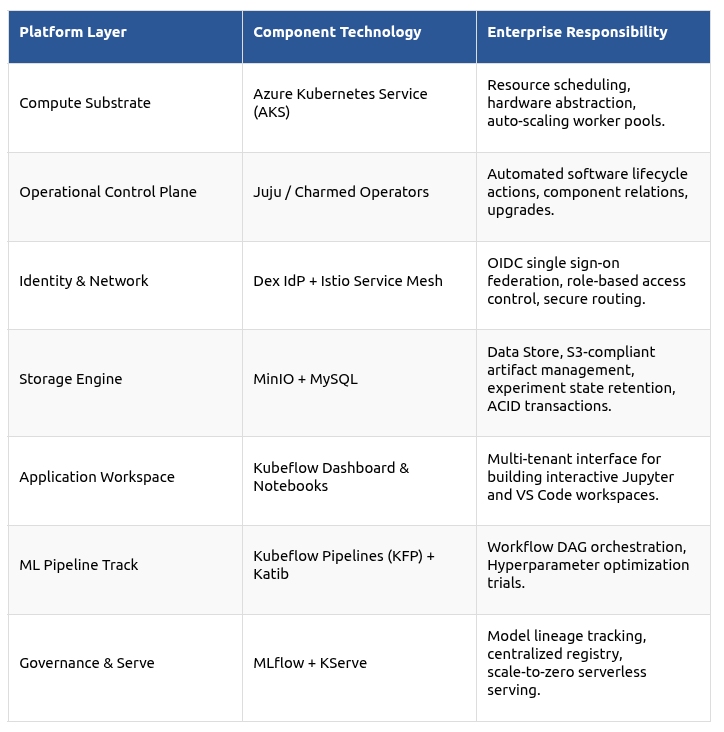
The Summary: Architectural Mapping Matrix
To conclude, let us summarize all the various layers and services in the table below, that illustrates how the different layers map out across the platform ecosystem to fulfill enterprise requirements:
Contacts
Get started today directly from the marketplace.
If you have any questions or would like to learn more, our team is here to help.