
My steps
- Diff against juju 2.9 tip:
juju diff to disable leadership auth
diff --git a/apiserver/facades/agent/leadership/leadership.go b/apiserver/facades/agent/leadership/leadership.go
index f0d9328554..8c62ffc426 100644
--- a/apiserver/facades/agent/leadership/leadership.go
+++ b/apiserver/facades/agent/leadership/leadership.go
@@ -79,18 +79,18 @@ func (m *leadershipService) ClaimLeadership(args params.ClaimLeadershipBulkParam
// In the future, situations may arise wherein units will make
// leadership claims for other units. For now, units can only
// claim leadership for themselves, for their own service.
- authTag := m.authorizer.GetAuthTag()
- canClaim := false
- switch authTag.(type) {
- case names.UnitTag:
- canClaim = m.authorizer.AuthOwner(unitTag) && m.authMember(applicationTag)
- case names.ApplicationTag:
- canClaim = m.authorizer.AuthOwner(applicationTag)
- }
- if !canClaim {
- result.Error = apiservererrors.ServerError(apiservererrors.ErrPerm)
- continue
- }
+ /// authTag := m.authorizer.GetAuthTag()
+ /// canClaim := false
+ /// switch authTag.(type) {
+ /// case names.UnitTag:
+ /// canClaim = m.authorizer.AuthOwner(unitTag) && m.authMember(applicationTag)
+ /// case names.ApplicationTag:
+ /// canClaim = m.authorizer.AuthOwner(applicationTag)
+ /// }
+ /// if !canClaim {
+ /// result.Error = apiservererrors.ServerError(apiservererrors.ErrPerm)
+ /// continue
+ /// }
if err = m.claimer.ClaimLeadership(applicationTag.Id(), unitTag.Id(), duration); err != nil {
result.Error = apiservererrors.ServerError(err)
}
@@ -101,18 +101,18 @@ func (m *leadershipService) ClaimLeadership(args params.ClaimLeadershipBulkParam
// BlockUntilLeadershipReleased implements the LeadershipService interface.
func (m *leadershipService) BlockUntilLeadershipReleased(ctx context.Context, applicationTag names.ApplicationTag) (params.ErrorResult, error) {
- authTag := m.authorizer.GetAuthTag()
- hasPerm := false
- switch authTag.(type) {
- case names.UnitTag:
- hasPerm = m.authMember(applicationTag)
- case names.ApplicationTag:
- hasPerm = m.authorizer.AuthOwner(applicationTag)
- }
+ /// authTag := m.authorizer.GetAuthTag()
+ /// hasPerm := false
+ /// switch authTag.(type) {
+ /// case names.UnitTag:
+ /// hasPerm = m.authMember(applicationTag)
+ /// case names.ApplicationTag:
+ /// hasPerm = m.authorizer.AuthOwner(applicationTag)
+ /// }
+
+ /// if !hasPerm {
+ /// return params.ErrorResult{Error: apiservererrors.ServerError(apiservererrors.ErrPerm)}, nil
+ /// }
if err := m.claimer.BlockUntilLeadershipReleased(applicationTag.Id(), ctx.Done()); err != nil {
return params.ErrorResult{Error: apiservererrors.ServerError(err)}, nil
- Bootstrap aws using a VPC and t3a.large instances.
$ juju bootstrap aws/us-east-1 jam-aws --config vpc-id=vpc-5aaf123f --bootstrap-constraints instance-type=t3a.large
Note about bootstrap being a bit slow
It is a bit surprising, but getting that initial bootstrap is slower than I expected. Cloud init starts at:
Cloud-init v. 21.3-1-g6803368d-0ubuntu1~20.04.4 running 'init-local' at Fri, 29 Oct 2021 18:44:34 +0000. Up 11.69 seconds.
The next interesting timestamp is during apt-install with:
Setting up tzdata (2021e-0ubuntu0.20.04) ...
Current default time zone: 'Etc/UTC'
Local time is now: Fri Oct 29 18:48:28 UTC 2021.
Universal Time is now: Fri Oct 29 18:48:28 UTC 2021.
Run 'dpkg-reconfigure tzdata' if you wish to change it.
I don’t know whether it took 3 min to run apt update && apt upgrade or if it just adjusted the clock, but it was slow to bootstrap (which is why I started looking).
apt-get update seems like it was fast:
Fetched 20.4 MB in 4s (5075 kB/s)
Maybe it was the time spent generating the SSH keys?
Juju itself started shortly thereafter:
2021-10-29 18:48:58 INFO juju.cmd supercommand.go:56 running jujud [2.9.18.1 0 282a0bae4cfabd5ac5d3a638d643549812b7594f gc go1.16.9]
snap install itself was reasonably fast, about 15s:
2021-10-29 18:48:59 INFO juju.packaging.manager run.go:88 Running: snap install --channel 4.0/stable juju-db
2021-10-29 18:49:14 INFO juju.replicaset replicaset.go:56 Initiating replicaset with config: {
- Enable ha
$ juju enable-ha -n3
- Switch to controller, create a prometheus user, deploy the bundle. Note that this differs from the Monitoring Juju Controllers because grafana moved to a proper name, and I wanted to deploy from charmhub. I’d love to move to LMA 2 but it needs K8s running.
$ juju add-user prometheus
$ juju grant prometheus read controller
$ juju change-user-password prometheus
bundle.yaml
applications:
controller:
charm: cs:~jameinel/ubuntu-lite
num_units: 3
to:
- "0"
- "1"
- "2"
grafana:
charm: grafana
num_units: 1
series: focal
channel: stable
to:
- "1"
expose: true
prometheus:
charm: prometheus2
num_units: 1
series: focal
channel: stable
to:
- "0"
telegraf:
charm: telegraf
series: focal
channel: stable
options:
hostname: '{unit}'
tags: juju_model=controller
machines:
"0":
"1":
"2":
relations:
- - controller:juju-info
- telegraf:juju-info
- - prometheus:grafana-source
- grafana:grafana-source
- - telegraf:prometheus-client
- prometheus:target
overlay.yaml
applications:
prometheus:
options:
scrape-jobs: |
- job_name: juju
metrics_path: /introspection/metrics
scheme: https
static_configs:
- targets:
- '$IPADDRESS0:17070'
labels:
juju_model: controller
host: controller-0
- targets:
- '$IPADDRESS1:17070'
labels:
juju_model: controller
host: controller-1
- targets:
- '$IPADDRESS2:17070'
labels:
juju_model: controller
host: controller-2
basic_auth:
username: user-prometheus
password: $PROMETHEUS_PASSWORD
tls_config:
insecure_skip_verify: true
juju deploy ./bundle.yaml --overlay overlay.yaml --map-machines=existing
$ juju run-action grafana/leader get-login-info --wait
Upload the dashboard.json. Note that it needs a few tweaks because of metric changes:
-
juju_apiserver_connection_countbecamejuju_apiserver_connections -
juju_api_requests_totalbecamejuju_apiserver_request_duration_seconds_count -
juju_api_request_duration_secondsbecamejuju_apiserver_request_duration_seconds -
Create another unit, upload leadershipclaimer to it (that way claimer load is separate from controller load)
# update the controller config so that you can add lots of logins
juju controller-config agent-ratelimit-rate=10ms
juju deploy cs:~jameinel/ubuntu-lite leadership-claimer
cd $GOPATH/src/github.com/juju/juju/scripts/leadershipclaimer
go build .
juju scp ./leadershipclaimer leadership-claimer/0:.
juju scp ./run.sh leadership-claimer/0:.
juju ssh leadership-claimer/0
And then inside the machine:
$ sudo grep apipassword /var/lib/juju/agents/unit-*/agent.conf
$ inject that into run.sh along with the controller API addresses and unit-leadership-claimer and `juju models --uuid`
Update run.sh to have 100 processes fighting over 100 leases.
When I try to run with normal pubsub, I end up getting a lot of:
362.122s claim of "a1787" for "a1787/0" failed in 54.137s: lease operation timed out
That led to:
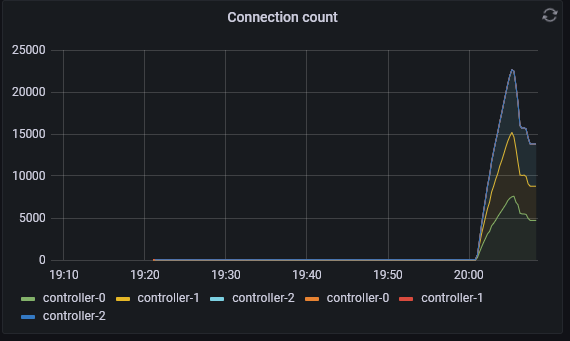
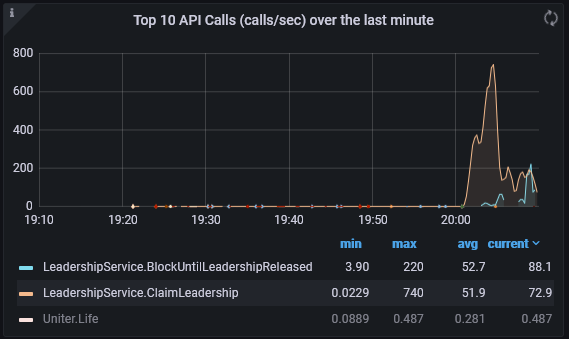
wipe it out, try again with fewer
killall leadershipclaimer
Drop it to 100 processes via for 20 leases (*3 units):
for i in `seq -f%02g 0 99`; do
x="";
for j in `seq -f%02g 0 19`; do
...
./run.sh
add another
for j in `seq -f%02g 20 39`; do
./run.sh
(note that this is also with renewtime=4.9s, claimtime=5s)
That actually worked for a while, but then:
413.937s blocking for leadership of "a0618" for "a0618/2" failed in 39.019s with error blocking on leadership release: lease manager stopped
...
killall leadershipclaimer
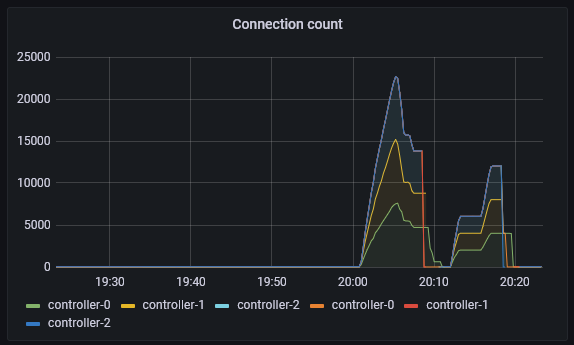
Then enable the feature:
$ juju controller-config "features=['raft-api-leases']"
Spin up the first 20:
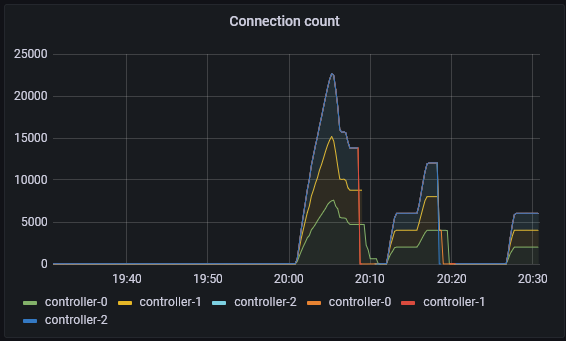
Interestingly, it is rock solid, and doesn’t have bounces or reconnects.
Add another 20:
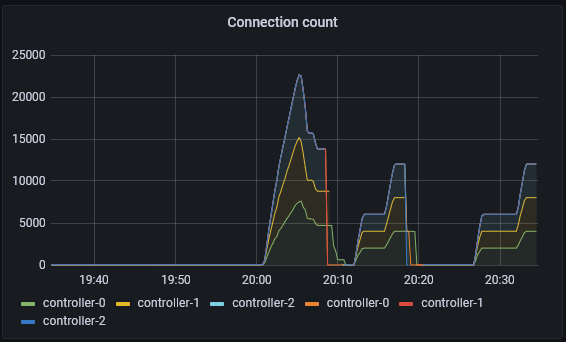
After waiting a bit, it is still pretty rock solid, and the facade call time is very steady.
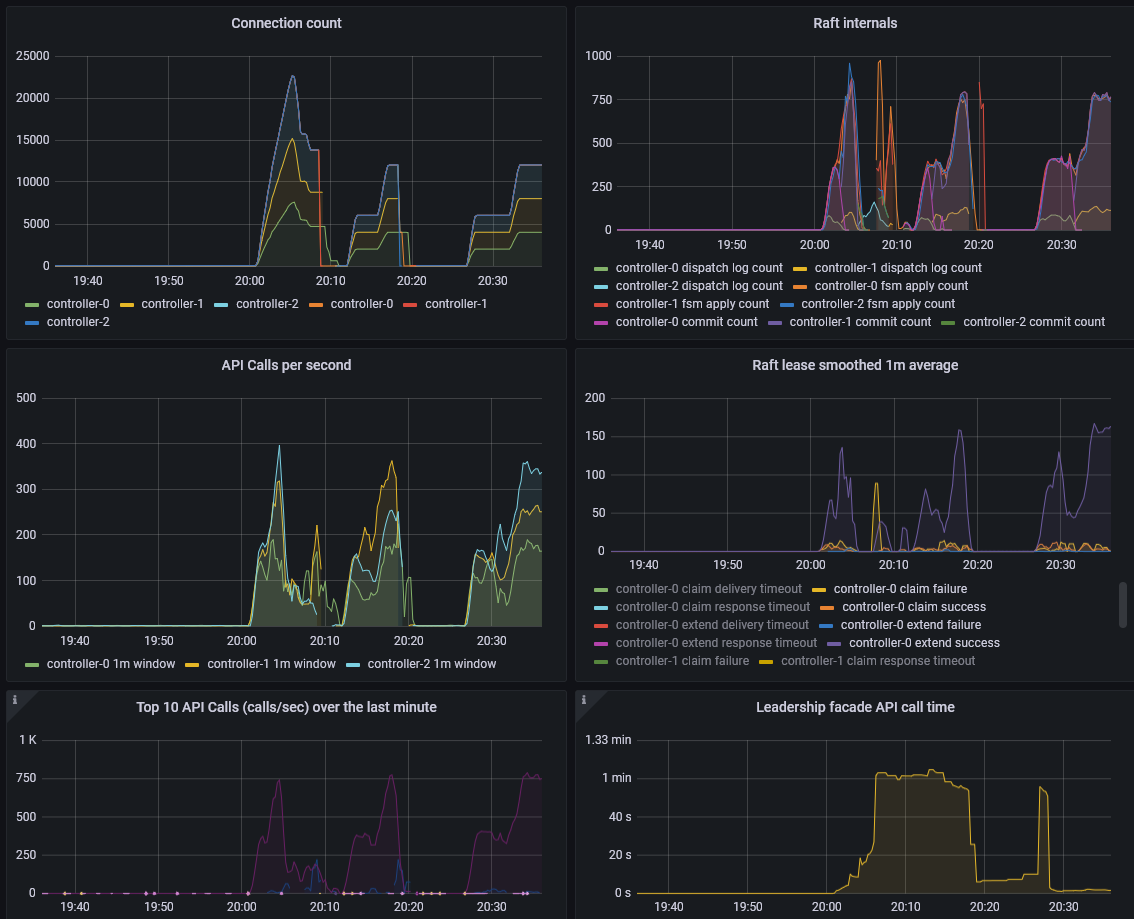
Double again by adding another 40
for j in `seq -f%02g 40 79`; do
./run.sh
At this point, it does start thrashing and getting
161.703s claim of "a8570" for "a8570/0" failed in 57.139s: lease operation timed out
However, I don’t see lease manager stopped.
At this point, controller machine-2 has gotten unhappy:
2021-10-29 20:43:34 ERROR juju.worker.raft.raftforwarder logger.go:48 couldn't claim lease "1a18744b-20a6-4514-8afd-42602dc6b078:application-leadership#a8122#" for "a8122/2" in db: no reachable servers
And seems like it cannot recover. at the same time, mongo is unhappy:
2021-10-29 20:43:34 WARNING juju.mongo open.go:166 TLS handshake failed: read tcp 172.30.3.137:53478->172.30.0.18:37017: read: connection reset by peer
I’m guessing one issue is that it is having back-pressure:
2021-10-29 20:41:14 WARNING juju.core.raftlease client.go:119 command Command(ver: 1, op: claim, ns: application-leadership, model: 1a1874, lease: a2745, holder: a2745/2): lease already held
2021-10-29 20:41:14 WARNING juju.core.raftlease client.go:119 command Command(ver: 1, op: claim, ns: application-leadership, model: 1a1874, lease: a4536, holder: a4536/2): lease already held
2021-10-29 20:41:14 ERROR juju.worker.raft.raftforwarder logger.go:48 couldn't claim lease "1a18744b-20a6-4514-8afd-42602dc6b078:application-leadership#a2913#" for "a2913/2" in db: Closed explicitly
2021-10-29 20:41:14 ERROR juju.worker.raft.raftforwarder logger.go:48 couldn't claim lease "1a18744b-20a6-4514-8afd-42602dc6b078:application-leadership#a9244#" for "a9244/0" in db: Closed explicitly
Which might be the patch that @simonrichardson has already proposed.
It does appear that there is work to be done, but it does look like it is going in the right direction.