
Hi everyone!
Below you’ll find the updates from the team for week 7 and 8. This sprint has been a little different for us, which I’ll go into more detail on later in this post. But first, as always, let me introduce the fantastic team and what we’re building.
This week, I’ll try a somewhat different format where we’ll go a little bit more in-depth into the things we’ve been working on. Let me know what you think below!
The Team
The observability team at Canonical consists of Dylan, Jose, Leon, Luca, Pietro, Ryan, and Simme. Our goal is to provide you with the best open-source observability stack possible, turning your day-2 operations into smooth sailing.
COS Lite
COS Lite is a light-weight, highly-integrated observability suite, powered by python operators and running on Juju. Find more information on charmhub or go straight to github.
Bridging the logging gap (#36)
One thing we’ve completed this sprint that we’re very excited about is support for using the LMA logging relations in the COS Proxy. This means that all charms that already support logging to LMA using the filebeat interface will now be able to also log to COS Lite through the proxy.
One of the key steps for making this happen is an open-source telemetry kitchen sink/swiss-army knife called Vector. Quoting the project webpage, Vector is A lightweight, ultra-fast tool for building observability pipelines. Using Vector, we were able to quite elegantly put together a transformation proxy listening to filebeat while forwarding Loki logs.
Adopting rockcraft
Something else worth highlighting from this sprint is that we’ve finally gotten started migrating the OCI images powering our charms from being built using Dockerfiles to instead use the wonderful rockcraft project.
rockcraft allows us to build small, deterministic OCI images based on Ubuntu, with the configuration being done in a way that is very similar to how snapcraft, charmcraft, and all of Canonical’s other craft tools work, making the maintenance of these OCI images far more unified with our other projects. Curious about how that looks? Have a look!
Documentation
We also put time into our documentation and written content, making sure it is kept current and useful. This included updating the content pieces we’ve published on the Juju and Ubuntu blogs, making sure the Ubuntu Server docs are referencing COS Lite as the successor of LMA, documenting design decisions and writing How To articles around COS Configuration and Juju Topology.
Deployment Model Hackathon
For the second week of the sprint, we did an internal hackathon. The purpose of the hackathon was to come up with a good, robust pattern for how to build highly available and scalable observability charms in Juju. During the first day of the week, we brainstormed a couple of feasible candidates, and we then split into teams for the remainder of the week to explore our two most promising options and uncover the advantages and disadvantages of each option.
While we’ve not made any final decisions yet, I think it might be interesting for the community to see how we think we could leverage the power of Jujus model-based deployments to create deployments that are highly scalable but yet remains easy for the operator to reason about.
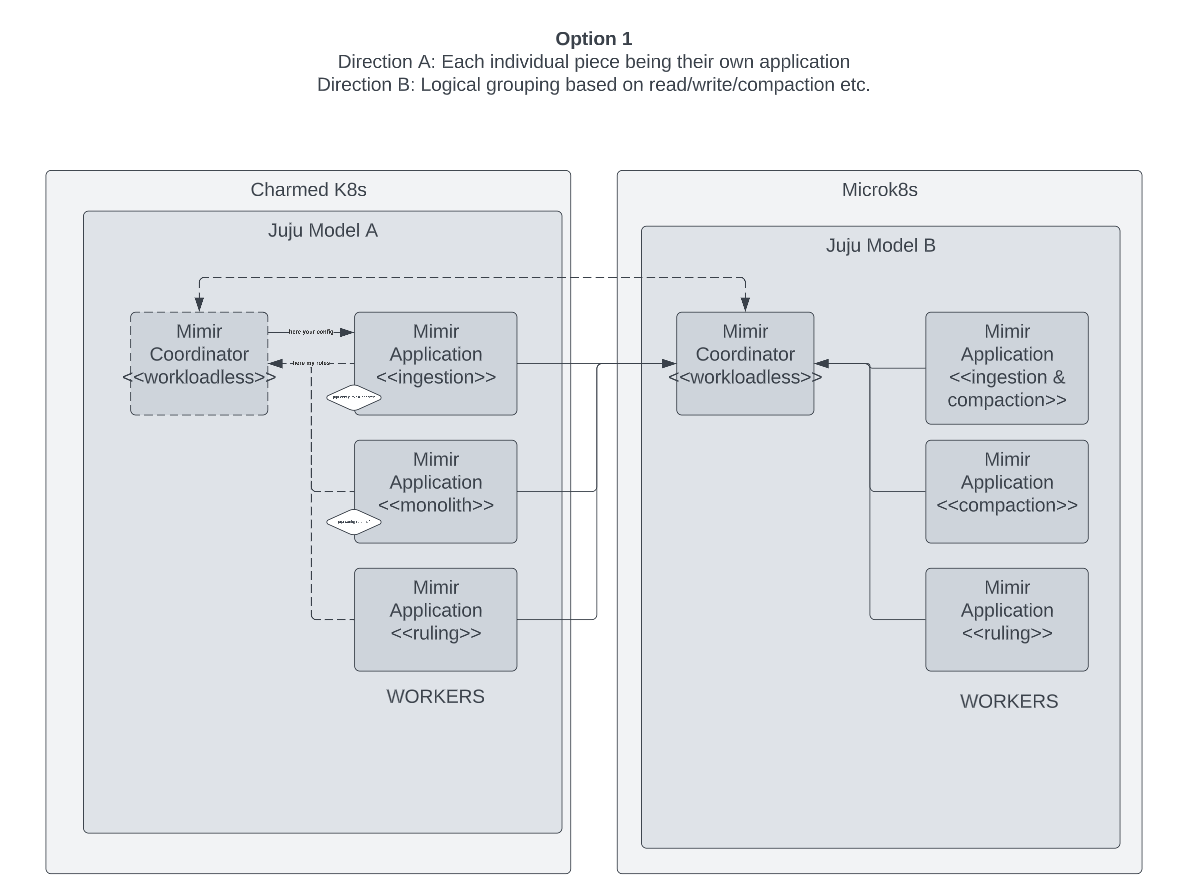
Option 1
For option 1, we explored having each role in the cluster deployed as a separate Juju application, using a coordinator to ensure we end up with a complete, functioning deployment. An interesting property of this is that it allows for two different directions, where one of them is made up of single-role application deployments, while the other one is made up of groupings based on data operations like read, write, and compaction.
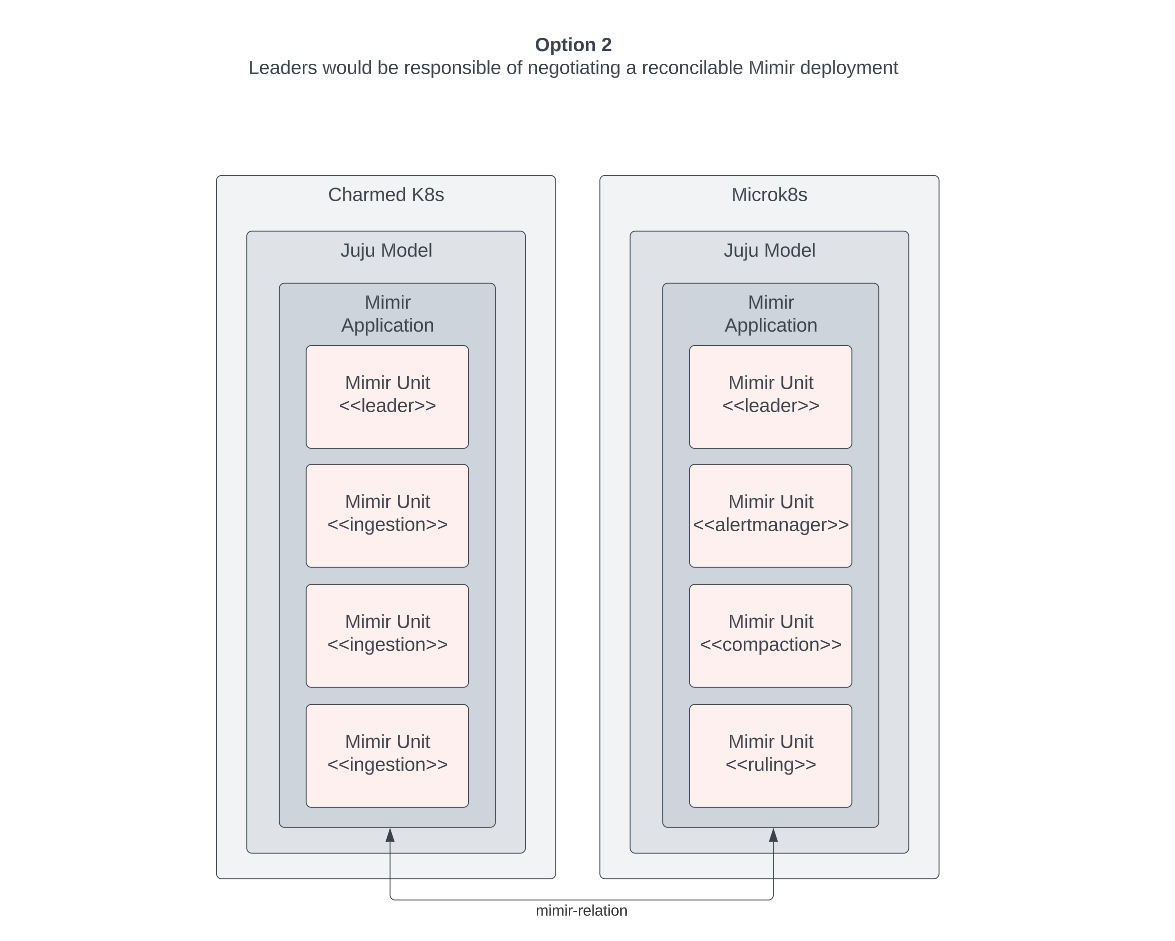
Option 2
For option 2, we explored having the leader of each application negotiate a functioning Mimir deployment, allowing for each unit of an application to have different roles.
Fixes
- Validate scrape configs/targets from incoming relations in Prometheus to bubble up whenever a charm is sending over corrupted or invalid config.
- Improved validation of parameters when setting up a
LogProxyConsumer.
Have a great week! 
