
Hi everyone!
Below are the team’s updates for weeks 15 to 20. First, as always, let me introduce the fantastic team and what we’re building.
The Team
The observability team at Canonical consists of Dylan, Jose, Leon, Luca, Pietro, and Simme. Our goal is to provide you with the best open-source observability stack possible, turning your day-2 operations into smooth sailing.
Working together in-person
You might wonder why we’ve been somewhat less frequent in these updates for a while now. The reason is that we’ve been busy working together, in person, ironing out the details for the coming six months of work ahead of us.
Being a fully distributed team, we really value these opportunities as they allow us to really double down and focus.
Mimir and distributed deployments
Part of our focus for the coming six months will be getting Mimir, and the distributed deployment of our charms, to a point where they really benefit from the fact that they’re being managed by Juju.
After spending quite a lot of time on the initial architecture, how it would fit together, and how to make the deployments both flexible and robust, we came to the conclusion that we’ll need two new charms to support the distributed deployment scenario:
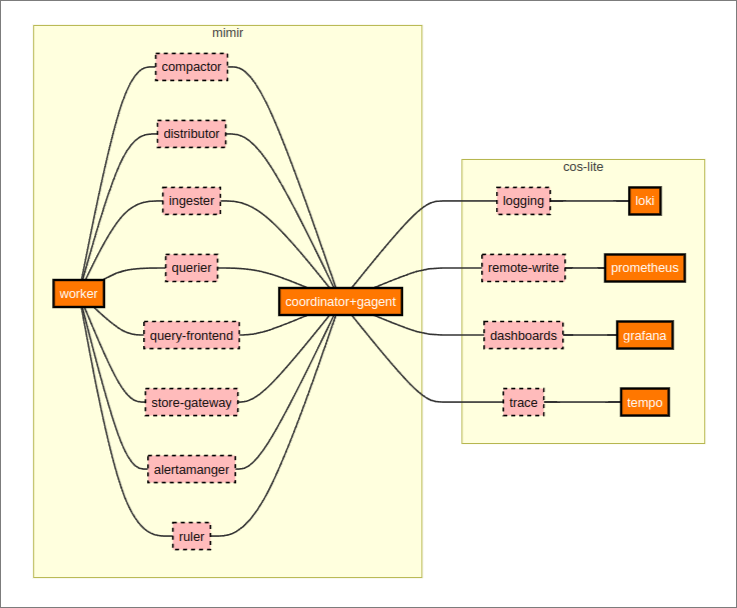
To quote @lucabello’s write-up from the design sessions:
The Mimir coordinator will run Grafana agent as a sidecar, to be able to push self-monitoring and worker metrics to cos-lite. On the same
mimir_workerinterface, the coordinator will accept one relation to a worker per each Mimir component. That relation determines the role the worker will assume.Each Mimir worker can take on multiple roles; however, there can be no role replication among workers related to the same coordinator (this can be enforced with
limit: 1on the coordinator side of the relations). The role is determined by the type of relation between the worker and the coordinator: for a fresh deployment, something likejuju relate worker:mimir-compactor coordinatorwill make the worker run the compactor role.The worker metrics will be scraped by the Grafana agent on the coordinator and then remote written to Prometheus.
A minimal deployment consists of one worker related to the coordinator through all the interfaces of the required components.
Charm Relation Interfaces
Charm Relation Interfaces now supports running interface tests on charms claiming to be compatible with a certain interface. We’re quite excited about this addition as we think it will allow us to level up the quality and consistency of charms and their relations yet another notch.
More on this in a later, separate post.
What else?
- Grafana Agent for Machines now properly traverse nested log directories (#181)
- COS Alerter now sports a dashboard, allowing you to see the status of all of your alertmanagers configured to talk to it. (#47)
- COS Proxy now properly handles variables in legend templates (#62)
- COS Proxy no longer duplicates composite_keys in the nrpe_lookup table (#60)
- COS Proxy now provides a dashboard for NRPE checks that combine the logs sent to Loki and the metrics sent to Prometheus (#57)
- Alertmanager no longer sends the wrong URL to Prometheus when ingressed by Traefik (#130)
Feedback welcome
As always, feedback is very welcome! Feel free to let us know your thoughts, questions, or suggestions either here or on the CharmHub Mattermost.
That’s all for this time! See you again in two weeks! ![]()
![]()