
Who this is for: Operators familiar with Juju who want to run a production-grade Charmed OpenSearch cluster with specialized node roles. By the end, you’ll have a working multi-role cluster with an optional failover orchestrator.
Prerequisites: Juju 3.x, a bootstrapped controller, and basic familiarity with charms and relations.
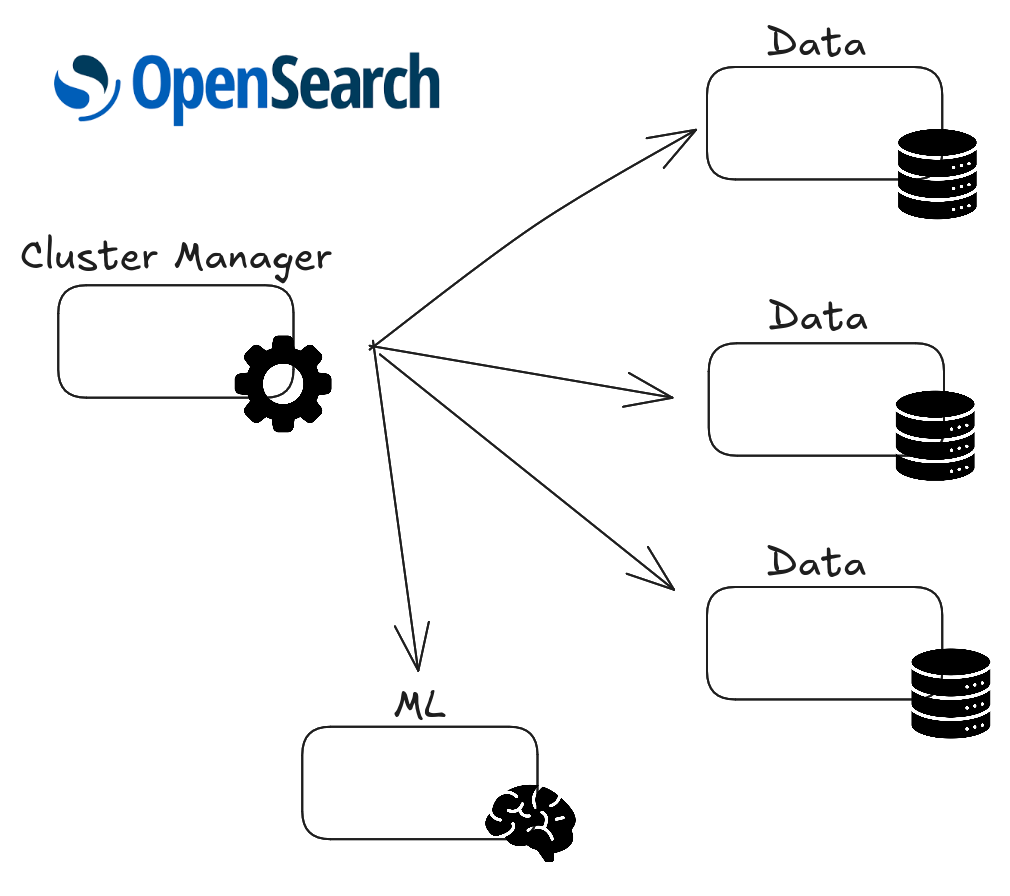
A production OpenSearch cluster isn’t a single homogeneous group of nodes. It’s a composition of specialized node types, each with a distinct responsibility: cluster managers handle routing and cluster state, data nodes take care of storage and search, and ML nodes run machine learning workloads. Running these roles on the same nodes is possible at small scale since OpenSearch support having nodes with multiple roles, but for a high available deployment you want them separated — this is what we call a Large deployment of a Charmed OpenSearch.
That separation is straightforward in principle, but it creates a challenge when deploying on Juju. Juju enforces a single configuration schema across all units within an application — every unit shares the same configuration payload. That’s a deliberate design choice that keeps deployments predictable and consistent, and it works perfectly for most charms. But it makes it hard to deploy a single Juju application and have some units act as cluster managers while others act as data nodes.
The solution is to deploy each role as a separate Juju application and establish relations between them so they can coordinate and form a unified cluster. This isn’t specific to OpenSearch — any charm that needs heterogeneous node roles faces the same constraint. OpenSearch just happens to be a clear case where the need is unavoidable.
The peer-cluster relation
The glue holding a Large deployment together is the peer_cluster interface. Both the provider and requirer endpoints use the same underlying interface peer_cluster but they expose different relation names in metadata.yaml. An OpenSearch charm would have both these defined:
-
Provider relation:
peer-cluster-orchestrator -
Requirer relation:
peer-cluster
Think of it as a handshake protocol: the orchestrator (Main cluster manager) announces “I’m running this cluster,” and the other applications join by establishing a relation to it. One application acts as the orchestrator (the relation provider), and the role-specific applications — data nodes, ML nodes, etc. — connect to it as requirer applications.
One important constraint is that a data or ML application can connect to only two orchestrators — one primary and one failover.
provides:
peer-cluster-orchestrator:
interface: peer_cluster
optional: true
requires:
peer-cluster:
interface: peer_cluster
limit: 2 # (main+failover)_cluster_orchestrator(s)
optional: true
Relation databag permissions and access control
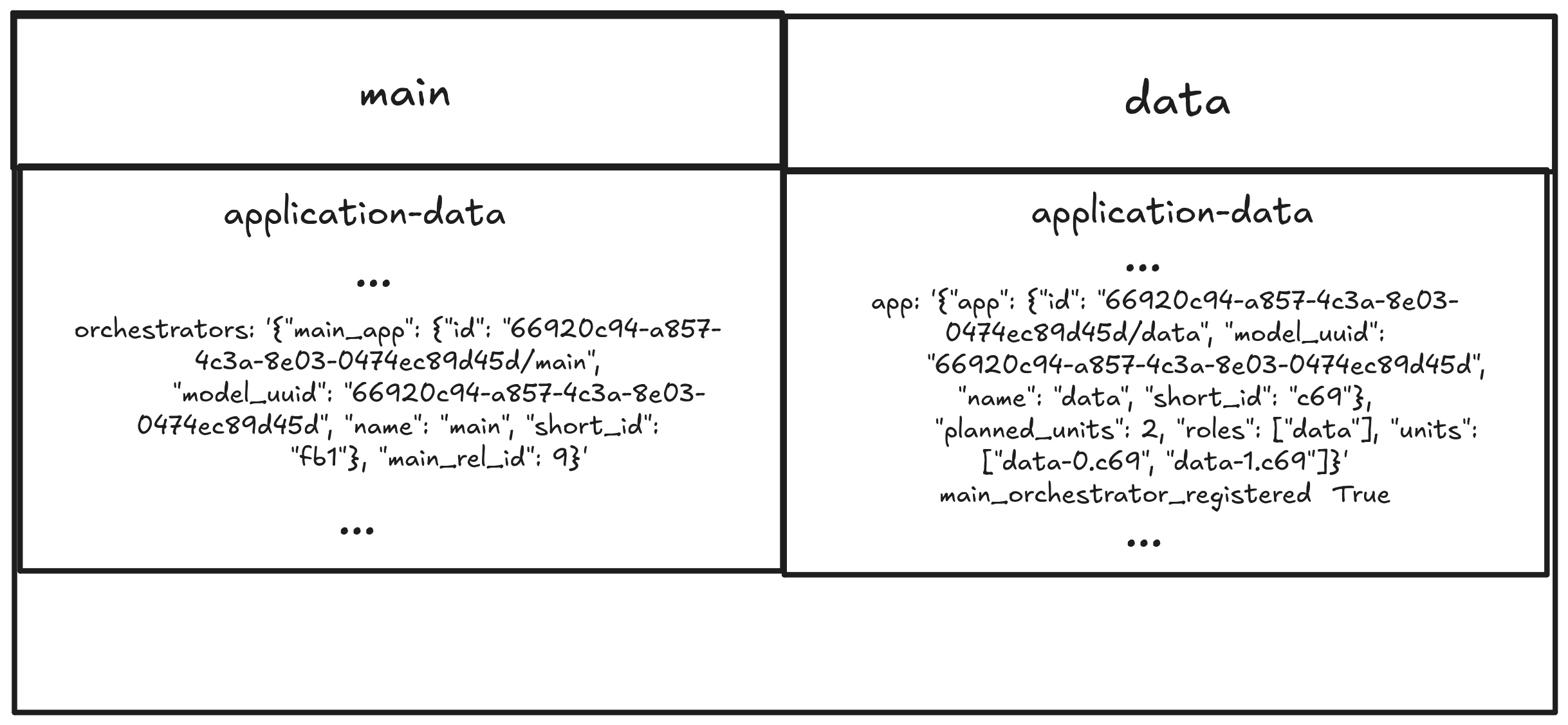
To understand how the orchestration happens when two Juju applications are related, we need to have some background on relations in Juju. When a Juju relation is created, it provisions isolated databags at both the application and unit levels. These are the channels through which apps share information — and they disappear when the relation is removed. The following figure shows two juju applications related through the peer-cluster/peer-cluster-orchestrator relation.
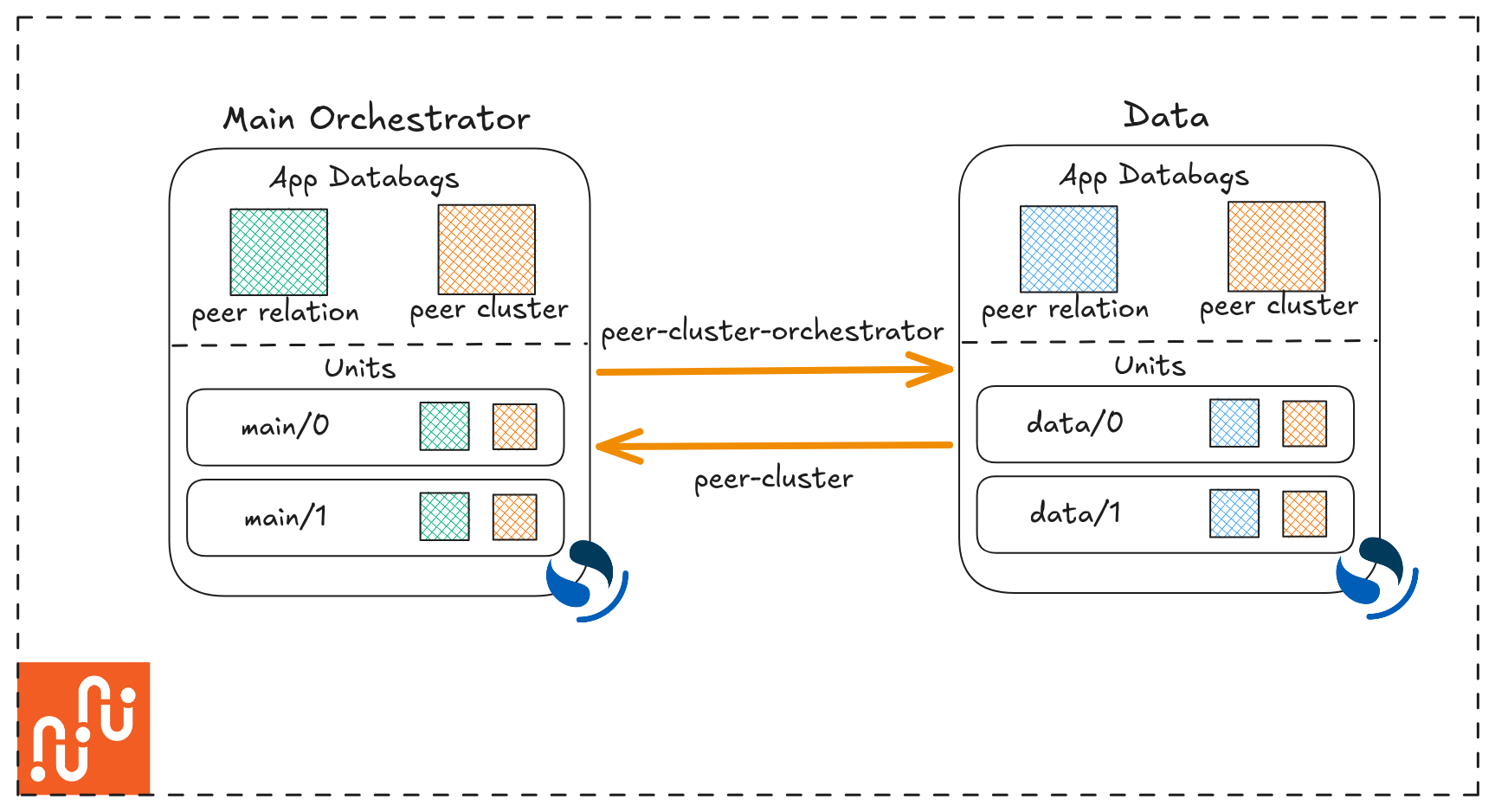
It’s worth noting that there are two types of databags in play here. The peer-relation databag is always present — it’s an application’s relation with itself, used for internal coordination between its own units. The peer-cluster databags is what gets created when two separate applications are related to each other, and it’s what carries information about the peer-clusters information.
Access control across all databags works like this:
-
Non-leader units can read all databags, but can only write to their own unit databag.
-
Leader units have exclusive write access to the application peer-cluster databag.
Now that we have some solid understanding of the `peer_cluster` relation, we can jump straight to the processes that are used to handle orchestration of a Large Deployment in OpenSearch.
Deploying the cluster
Step 1: Deploy the applications
All applications that belong to the same cluster must share an identical cluster_name. if the names don’t match, each application bootstraps its own isolated cluster instead of joining a shared one.
The init_hold="true" flag tells an application to pause startup until a cluster manager is available. The main orchestrator is the only application that runs without this flag — it bootstraps first, then everything else waits for it.
juju deploy opensearch main --channel 2/edge \
--config cluster_name="app" \
--config roles="cluster_manager"
juju deploy opensearch data --channel 2/edge -n 2 \
--config cluster_name="app" \
--config init_hold="true" \
--config roles="data"
juju deploy self-signed-certificates
juju integrate main self-signed-certificates
juju integrate data self-signed-certificates
At this point, both main and data will be in a blocked state — and that’s expected. The main app is waiting for a data node to join (OpenSearch requires at least one), and the data nodes are waiting for a cluster manager. Neither can proceed alone.
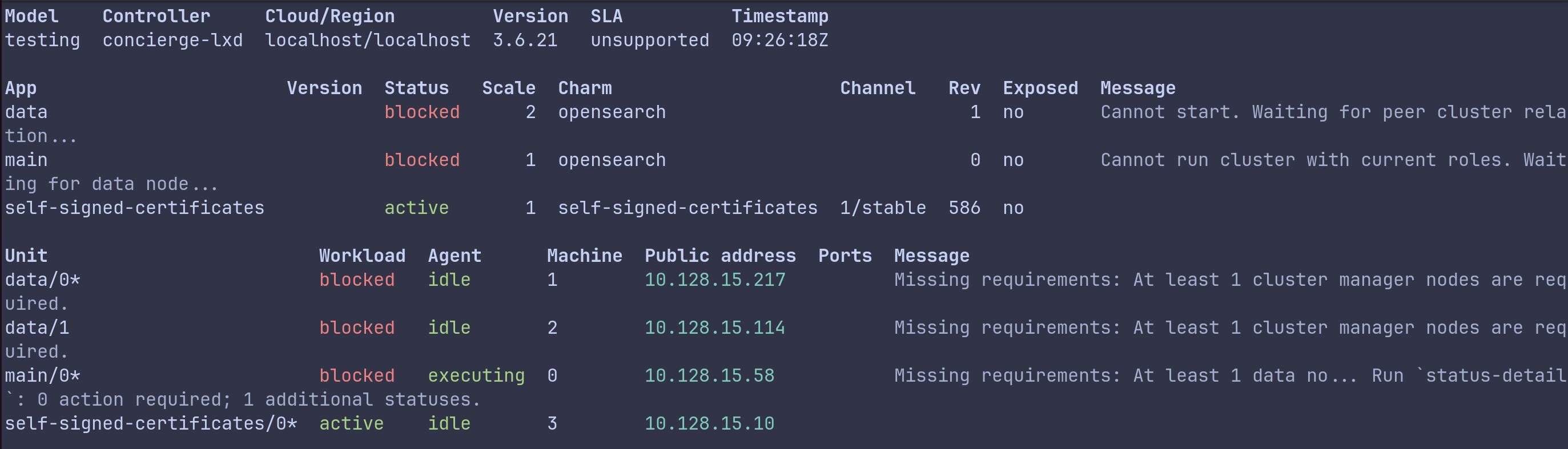
Step 2: Connect the applications
Binding the main orchestrator and the data applications initiates the cluster synchronization process.
juju integrate main:peer-cluster-orchestrator data:peer-cluster
This single command kicks off the synchronization process. The main application writes its updated state to its application databag and broadcasts it to all connected peer-cluster applications. The data nodes receive this, overwrite their local databags to mirror it, and the cluster forms.
Once both sides are active, you should see all units move to an active state.
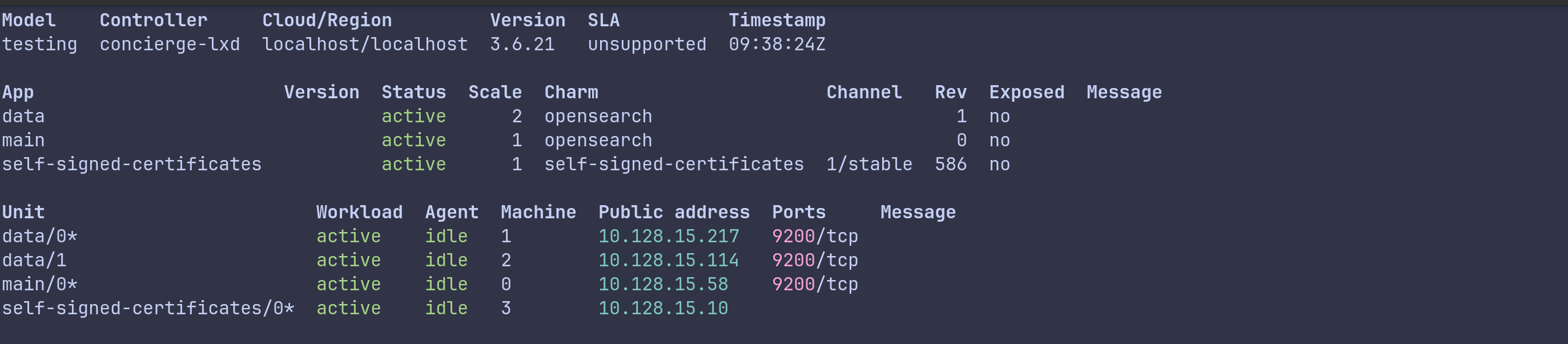
What happens during first startup
Once the relation is established, there’s a carefully coordinated bootstrapping sequence that happens under the hood before the cluster is fully online:
-
The cluster manager initializes the base cluster state, then waits for a data node to join.
-
A data node starts and checks whether it can reach the cluster manager. Once it can, it advertises itself as a candidate
first_data_nodein its peer-cluster relations. -
The main orchestrator reviews all applications advertising themselves as
first_data_nodeand selects one to go first. -
The selected data node runs the security index initialization, which brings the security layer of the cluster online. This is an important step in OpenSearch which will configure the security of the cluster.
-
With the security index in place, the cluster manager completes its startup fully, and the remaining data nodes follow.
This coordination through the first_data_node field ensures that the security index is initialized exactly once, by exactly one node, in a deterministic order. If anything stalls at this stage, this sequence is the first place to look.
Coordination of orchestrators
The `main` application providing the relation mutates its own field and broadcasts this state across the network to all connected applications. The receiving applications parse this payload and overwrite their local databags to mirror the primary state exactly.
High availability and the failover orchestrator
At this point you have a working cluster — but it has a single point of failure. The main orchestrator is the application that holds and broadcasts the cluster’s configuration state. If it goes down or is removed, the remaining applications lose their source of truth and the cluster cannot recover on its own.
This is not an OpenSearch-level concern. OpenSearch itself has no concept of a “main” or “failover” orchestrator — from its perspective, it simply sees a set of cluster manager nodes. The main/failover distinction is purely a Juju coordination layer, designed to ensure that the charm logic always has an authoritative application responsible for managing the peer-cluster state.
The solution is to deploy a failover orchestrator: a second cluster manager application that stays dormant under normal conditions but is ready to take over if the primary fails. This makes the Juju coordination layer itself highly available, independent of whatever OpenSearch is doing internally.
Deploy and connect the failover
juju deploy opensearch failover --channel 2/edge \
--config cluster_name="app" \
--config init_hold="true" \
--config roles="cluster_manager"
juju integrate main:peer-cluster-orchestrator failover:peer-cluster
juju integrate failover:peer-cluster-orchestrator data:peer-cluster
The failover needs two relations: one to the main orchestrator (so it stays in sync) and one to the data nodes (so it can take over as their orchestrator if needed).
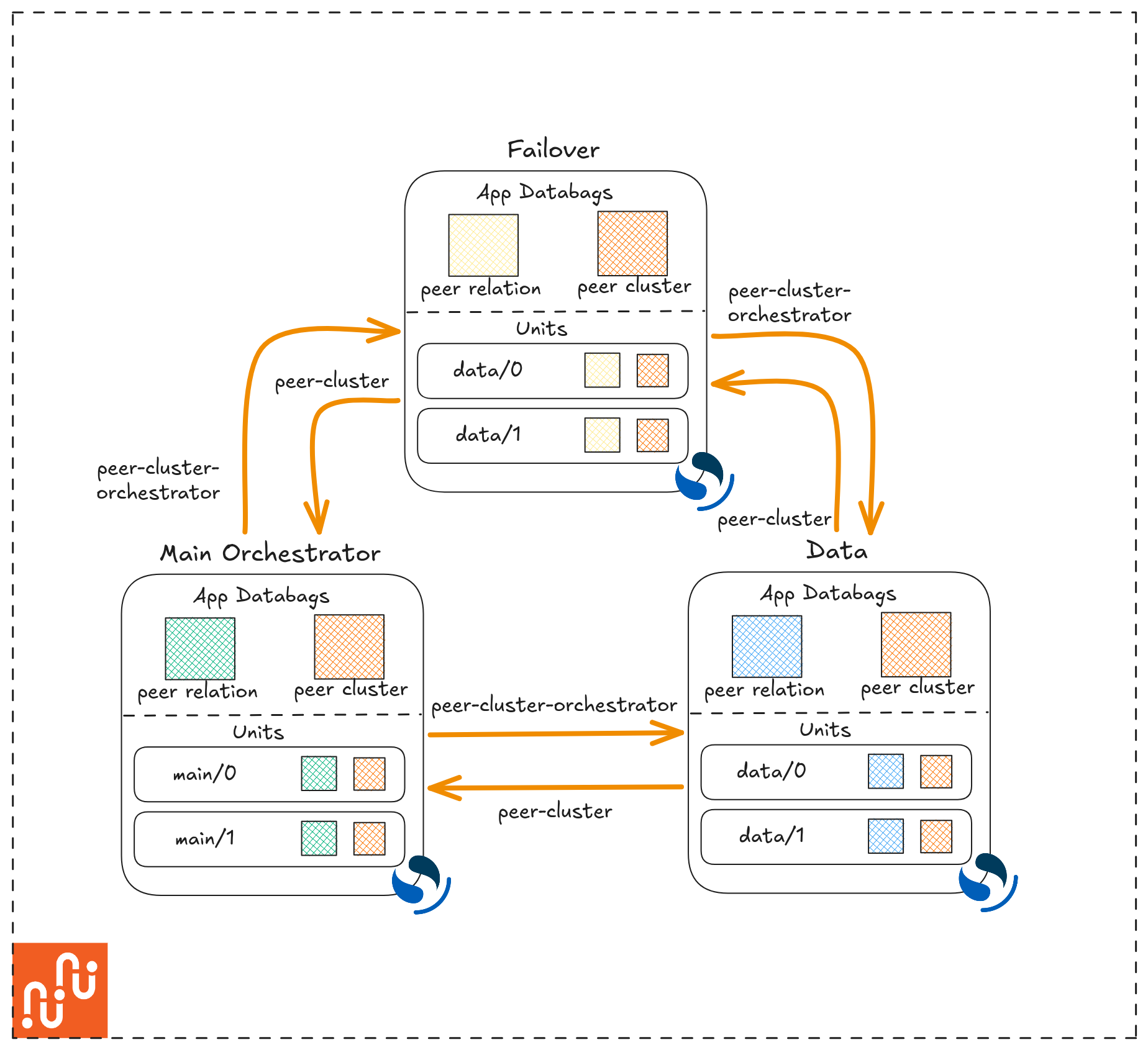
What happens when the main is down/removed
Each non-main orchestrator application — including the failover — continuously writes the value of main_orchestrator_registered to its databags across all of its peer-cluster relations. The failover uses these values to count how many applications still see the primary orchestrator as active.
If the failover determines that the primary has lost a mathematical majority of those registrations — for example, because the main app was removed or scaled to zero — it concludes the primary has failed and promotes itself to the primary role. It then broadcasts its new status to all connected peer-cluster applications, and the entire cluster adopts the updated topology without manual intervention.
Common pitfalls
Mismatched cluster_name: Each application will form its own cluster instead of joining a shared one. Double-check this before deploying.
Forgetting init_hold on non-orchestrator apps: Without this flag, a data node may try to bootstrap its own cluster before a manager is available, leading to a split-brain situation.
Missing TLS integration: OpenSearch requires certificates. Make sure every application is integrated with self-signed-certificates (or your preferred TLS provider) before connecting the peer-cluster relations.
Conclusion
The multi-role deployment pattern is how the OpenSearch charm bridges the gap between Juju’s uniform application model and the reality of running a distributed system that needs heterogeneous nodes. By deploying each role as its own Juju application and wiring them together through the peer_cluster interface, you get a fully operational Large deployment where each node type can be scaled, configured, and managed independently.
Adding a failover orchestrator takes this a step further by making the Juju coordination layer itself resilient — ensuring that the loss of any single application doesn’t bring down the cluster’s ability to manage itself.
From here, you might look at integrating observability tooling with the Grafana agent charm, or configuring index lifecycle policies directly on the data nodes
Further Reading
For more detailed information on OpenSearch architecture and cluster configuration, consult the official documentation, visit the GitHub repository or the full documentation.