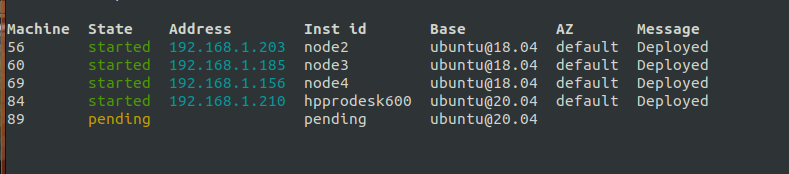
The last machine does not get allocated. I don’t see anything happening in Maas. Where do I start debugging this? I have the feeling I’ve debugged MaaS/Juju more than I actually used it.
This worked fine before, as you can see with the lower machine-ids.
Well this was quite a hunt as well. No feedback what so ever in the logs, just some indication that at startup one of the 2 controllers was trying to install mongo 3.6, yet mongo 3.4 was already installed.
Somehow it got past that but still used 3.4, but the provisioner never actually ran i guess.
Went down the rabbit hole and tried to upgrade to mongo 3.6. Didn’t work, b/c the mongo’s feature level apparently was still 3.2.
Reinstalled 3.4 again and set the feature level of mongo to 3.4 (was 3.2), and then continued to upgrade to mongo 3.6. Restarted the controllers and voila, now it does provision again.
The big problem here is, when stuff like this happens, you’re working blind and have to read tea leaves in the logs.
No, the provisioner has been around since juju 2.0.
Are there any errors reported in the debug log of the controller-model? Check for the same Maas and provisioner errors in the model with the pending machine as well.
hyperconverged being in this case, 2 of the nodes are also controllers in a single model.
I can no longer reproduce this since I upgraded to mongo 3.6 which the controllers we’re trying to do since I upgraded to 2.9.x. Please that ‘adventure’ 2 posts up.
You can consider this ‘solved’, though the feedback you get from the logs is minimal. All logs were in DEBUG already.