I have a very old machine (dual core intel i7 4th gen, 8GB RAM) … running Kubuntu 22.04 LTS
I’ve installed latest LXD, Juju
Added a controller in LXD, added AWS credentials, added models added spaces
All is working until … I juju deploy ubuntu --base=ubuntu@22.04 --constraints instance-type=t3.nano
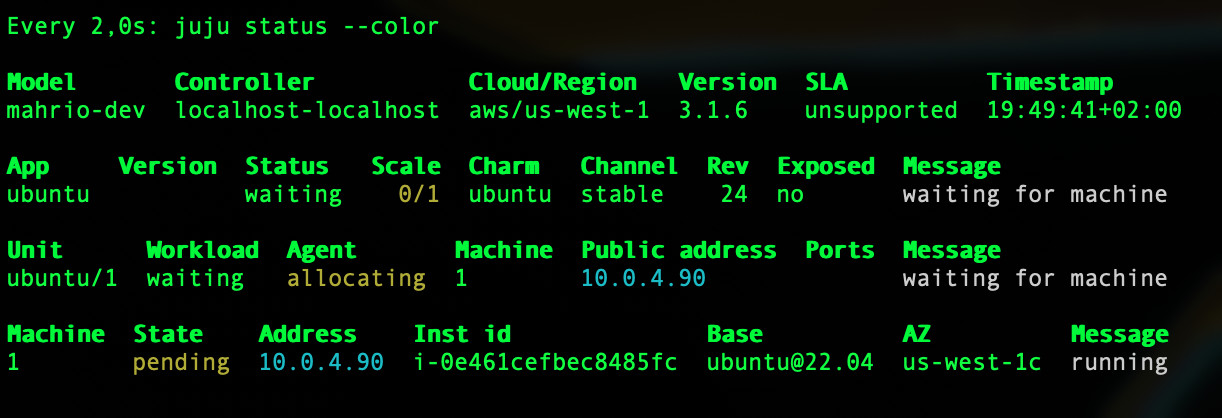
As a test I had used another blank model in the default vpc… and things seemed slow but working… but I can tell things are timing out and as I look at juju status it is stuck in
and yet in AWS everythings allocated… everything seems green for launch
any clue why? is my little controller machine too slow or…? I waited a good 6-10 minutes and nothing…
EDIT: tried with a new model in same VPC… no spaces settings… same problem… resources allocate fine in AWS side… but the controller is perpetually in waiting for machine
this same setup works well with JAAS’s jimm controller … so am a bit wondering how to fix it…
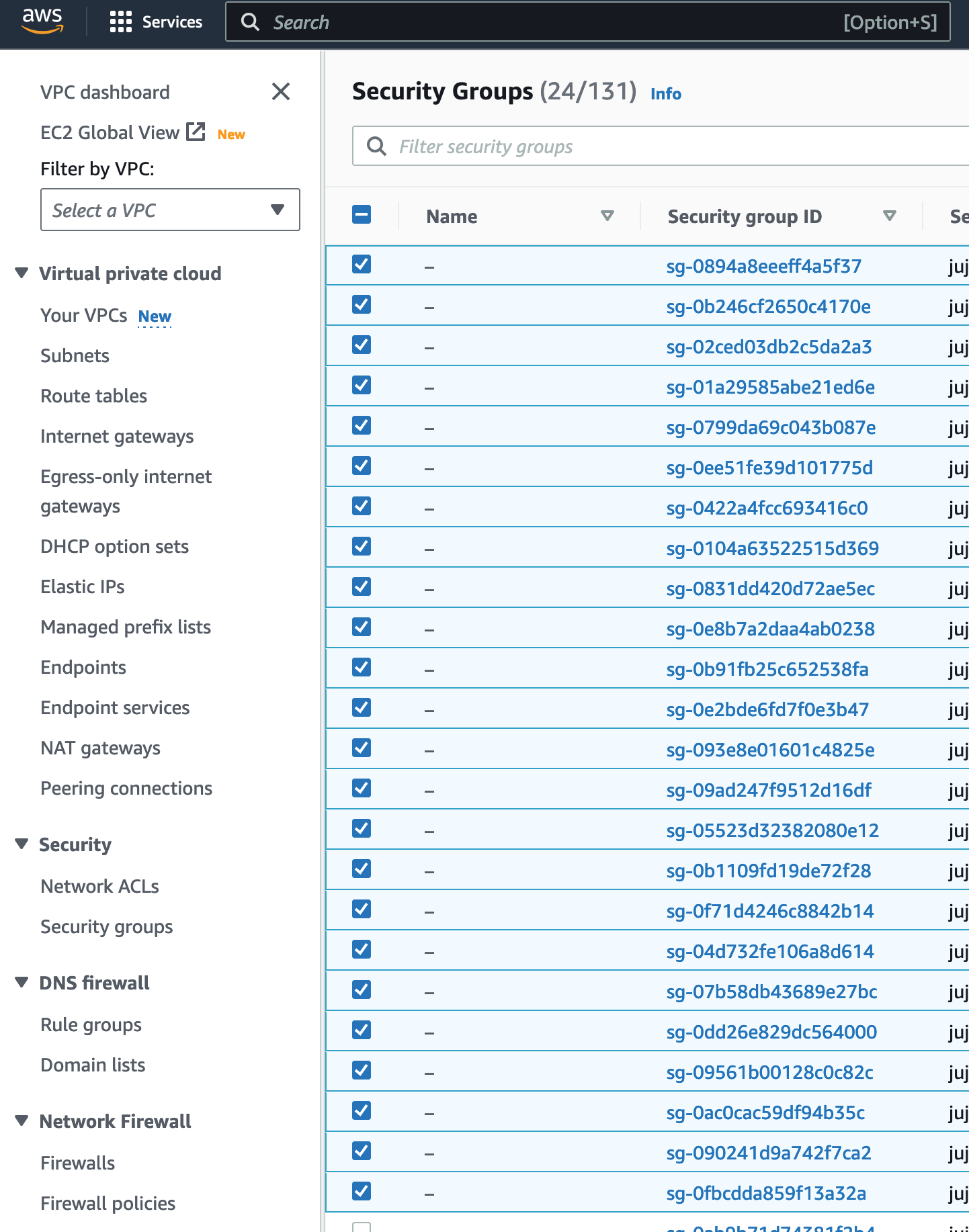
with 8 days to go before jimm shutsdown , im pretty motivated to get Juju Controller on LXD working pointed towards AWS… my next instinct is that … while juju is working with AWS just fine… the Security Groups that Juju is possibly automatically creating are not opening up the traffic enough for the controller to hear back from the ubuntu ec2 node… going to proceed to cleanup production and sort of ensure I have a good understanding of what’s different between the JIMM deployment and my private controller deployment
in Juju 3.x I wonder if theres a easier way to clean up remnant Sec Groups … but for now it is manageable
EDIT:
Upon cleanup and inspection… the JIMM controller is working fine… getting messages… however the rules look very very different now in Juju 3.x spec controllers (seems to be more IPV6 related)… but I still am worried something isn’t quite right. From the controller I can curl my jimm deployed webapp successfully… but attempting to ping or curl an ubuntu image doesn’t really make sense … pinging the public ip allocated times out right now… probably not in the default rules
my gut says that the JIMM controller was setup in AWS … and hence “just worked” … but now with my own controller I need to gather a list of port openings required to get clear line of site to my nodes… hence reading up within Juju | How to manage a controller
EDIT2: as a test i simply punched a hole to my public ip … no change in behavior from the ec2 instance in terms of reaching my LXD controller… and now I am sort of stumped… just seems like it’s in a pending state forever.
Pinging does work, once I opened up the entire network stack towards my public IP … but that IP is dynamic so… this is not ideal… might be time to setup site-to-site VPN or tailscale …
sort of dreading the possible requirement that the Controller sit with AWS EC2 credentials up in AWS itself… in order for Juju to truly work well .
Were you using the default LXD bridge when you bootstrapped the LXD controller?
With the correct AWS credentials, you will be able to set-up a mutli-cloud controller and models, but when you deploy a machine, the agent on it needs to contact the controller. If the controller’s container has no ingress, then what you observed is expected - the machine is provisioned, but its agent can’t tell Juju that it’s up.

 or tailscale …
or tailscale …