
Instead of “move fast and break things”, the Charm Tech team focuses on considered design and stability. That doesn’t mean we don’t make improvements, but when we do, we’re careful to do so in a way that doesn’t break our existing users. We aim to be boring technology.
A large part of this is ensuring that when Ops (and Jubilant and other tools) get new functionality, we add it in a backwards compatible way. We also think a lot about how we might make future changes when designing APIs (and CLIs and other interfaces). As a simple example, positional-only and keyword-only arguments in a Python API make it easier to modify the signature in the future.
However, no matter how much care is taken, eventually you hit Hyrum’s Law:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.

No-one is suggesting that we shouldn’t fix bugs, but most bug fixes are, technically, backwards incompatible changes. There are also mistakes that we’d like to fix, where relying on the mistake would itself be considered a mistake, but fixing them would be a backwards incompatible change. Consider this code in Ops’s model.py:
from .jujuversion import JujuVersion
# JujuVersion is not used in this file, but there are charms that are importing JujuVersion
# from ops.model, so we keep it here.
_ = JujuVersion
Exposing this object in the ops.model namespace was unintentional. A user should import JujuVersion from ops, but due to how Python handles module namespaces, they can currently import it from ops.model, which means changing this line of code to make it clearly private use could break someone’s charm.
One solution is to publish a beta or other pre-release version of the tools, or to make changes opt-in (such as with a feature flag). Charm Tech doesn’t typically do this, as we’ve found adoption to be too low to be useful.
This leaves us with the problem that we want to be confident, prior to release, that we understand the impact of changes in Ops. Mostly, we avoid breakage, but in some cases, we’ll find a small number of charms that do need changes, and decide that we’ll go ahead with the fix anyway, opening a PR ahead of time for those charms.
So, how did we solve this problem? Our first step was to find a corpus of charms that we could validate our changes against. Happily, most charms are open-source, and most of them can be found by searching code hosting platforms like GitHub. A couple of years ago, we collated a list of charms from within Canonical, and have added charms as new ones are produced.
This means that we can clone the charm source, change the dependencies so that rather than using a released version of Ops the charm uses a version from a branch, and then run the charm’s tests to validate that nothing breaks.
Doing this manually would be tedious, so we’ve automated this process in a tool that we currently call super-tox. We use this to run the lint and unit checks that the charm defines, and investigate any differences between the unmodified charm and the charm using the proposed Ops branch. It takes about 5-10 minutes to run against around 100 charms. Not something to be done with every commit, but it’s lightweight enough to do for any PR where we’re concerned about changes, or when doing exploratory work.
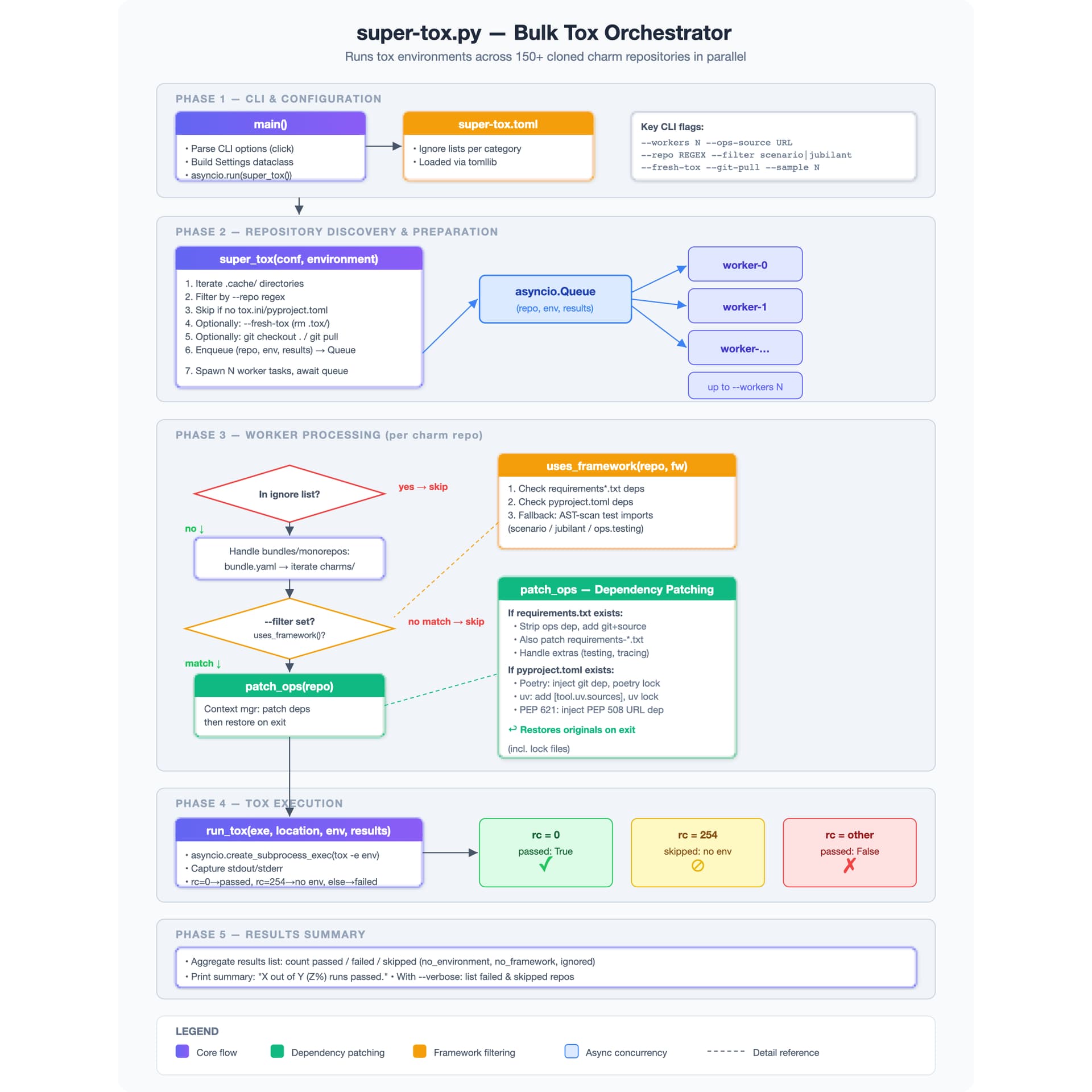
(No AI was used in creating super-tox, but it certainly was in creating the above diagram…)
We named it “super-tox” because it runs tox -e unit (or similar). That obviously isn’t going to work if the charm’s unit tests are run with run_unit_tests.sh or some other custom tooling. Realistically, we need charms to offer a consistent mechanism for running tests to do this in bulk. That’s one of the reasons why we ask that charms use only tox, just, or make and have lint and unit targets that do particular sets of checks (for example, type checking should be included in lint).
Two recent examples of where we’ve used this are:
- Changing the type annotation and coercion of machine_id from int to str. The machine ID is typically an int, but it’s actually a string in Juju and sometimes looks like unit-cinder-powermax1646-2.
- Improving the performance of running state transition tests by reducing the times we load and dump to YAML. At the moment, we don’t see significant improvements, so we’re holding off on making changes that don’t have a clear payoff. This is an example of how we look for performance regressions as well as functional ones.
This isn’t a new practice in Charm Tech. Way back in September 2021, we added CI to test changes against some observability charms. In 2022, we added the postgresql and mysql charms as well, and we still do all of that today. “super-tox” simply scaled this up to “all the charms we know about”.
One of the advantages of our testing against the observability and data platform charms is that it’s done automatically with CI. We don’t want to have CI testing privately listed charms, perhaps still in early stages of development. However, testing against all the discoverable charms in CI both gives us more confidence on a regular basis, and also adds an additional benefit to being publicly listed.
Our “broad charm compatibility” workflow currently runs just before our regular release so that we can investigate any new failures before releasing. Not every charm currently passes; however, we look into each of these failures to ensure that it’s not the result of a change we’ve made, and we’re working on getting to a 100% pass rate, while expanding the set of charms that are tested.
Not long ago, more than half of the charms failed, because the current version of Ops requires Python 3.10 or newer, but many charms explicitly support Python 3.8. We added in patching of the minimum Python version as well, to cover that case, and are nearly at 100% now.
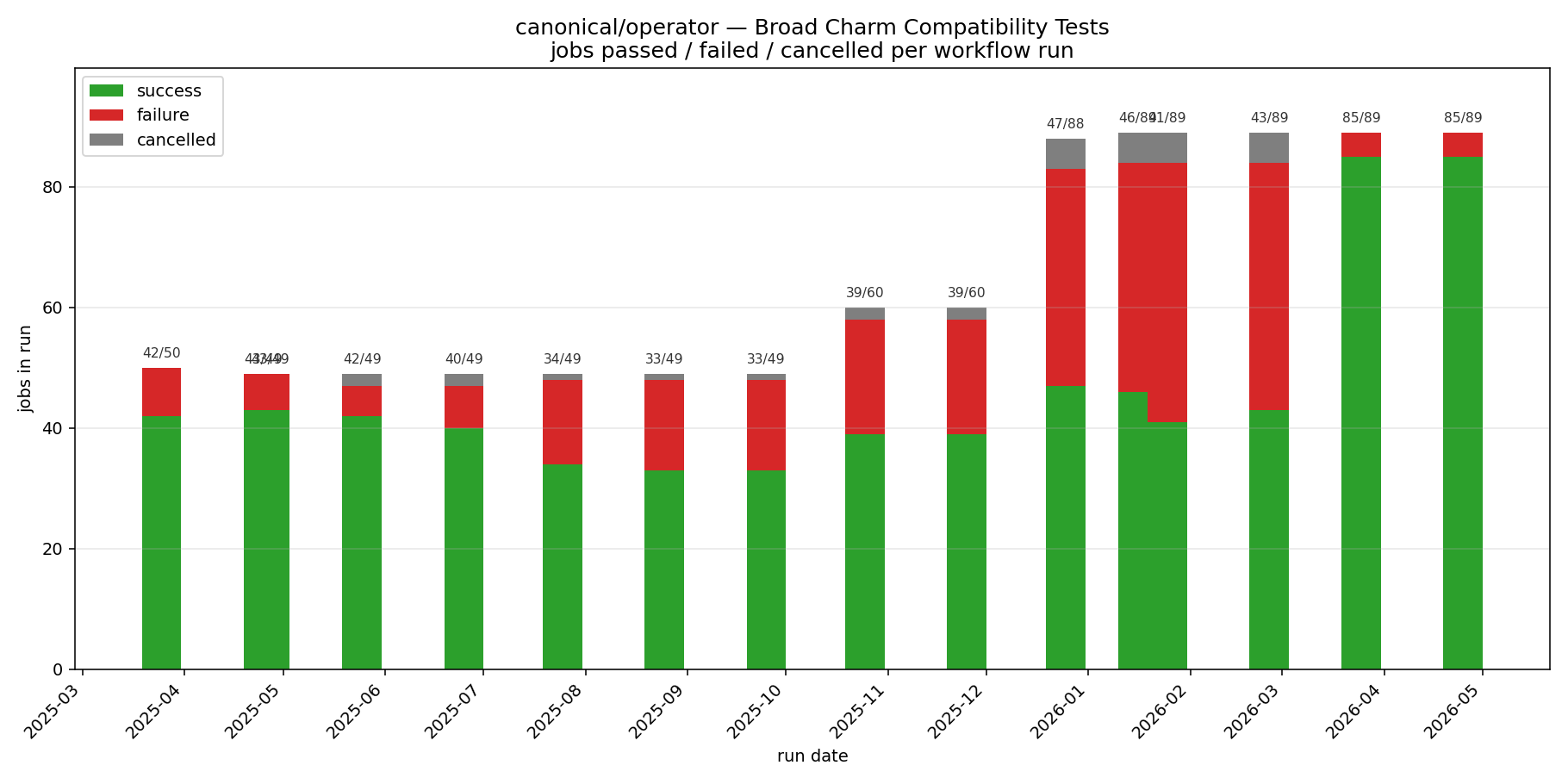
(TIL sidenote: did you know that whoever last modified the schedule is the one user that gets notified if a GitHub workflow fails?)
In the 26.10 cycle, we’re planning to make some improvements to this tooling:
- It would be great to test not only
lintandunitbut also integration tests – particularly because some charmers prefer to have extensive integration tests and few unit tests, and Charm Tech considers this reasonable practice. Integration tests come with new challenges around resources and safety (particularly executed outside of an ephemeral CI runner), but most significantly there is a lot of variation in how charm integration tests are currently run, with quite complex CI in many cases. We’d like to get some more simplification and standardisation in that area so that we can add in integration testing in the future. - We generally only handle
toxright now, but our general charming guidance is thatjustandmakeare acceptable choices. If charms are adopting those alternatives, then our tooling will need to handle those as well. - The “published charms” set of charms currently only includes those that are hosted on GitHub, are within specific organisations (such as
canonical), and where thecharmcraft.yamlprovides a source location (or one that we can figure out based on other contact details). We’d like to expand this to include charms hosted on Launchpad and perhaps elsewhere, and to see whether we can figure out the source for more of the charms. - We intend to move super-tox to a Canonical repository, improve the documentation, make it easier to get started and to compare results across runs, and other similar polishing improvements.
- Super-tox currently swaps out
ops(and extras) but there isn’t much that’s specific aboutopsin that process. We’d like to extend the tool so that we can swap out PyPI-hosted charm libraries as well, so that we can (for example) check that a new release of pathops isn’t going to break any of the charms we know.
If you’d like to try super-tox, or have any feedback about our approach, please get in touch!