
The following document exposes high level information about the Canonical MLOps portfolio and the components that make up each of the products. The goal is to provide information about the solutions that the Analytics team provides so that ML engineers, and Architects can see how these support their different use cases.
Canonical MLOps portfolio
Canonical MLOps portfolio is an end-to-end solution of open-source tools that enables the development and deployment of ML models in a secure and scalable manner. It is a modular architecture that can be adjusted depending on the use case and consists of a growing set of cloud-native applications.
The solution offers up to ten years of software maintenance break-fix support on selected releases and managed services.
Charmed Kubeflow (CKF) is the foundation of the portfolio, packaged, secured and maintained by Canonical. It runs on Kubernetes and provides ML complete workflows, including training, tuning, and shipping of ML models. It closely follows the upstream project.
Charmed Kubeflow integrates with leading open source tooling such as Charmed MLflow, Charmed Spark and Canonical Observability Stack (COS).
Canonical MLOps solutions within the Juju ecosystem
In the Juju ecosystem, Charmed Kubeflow is integrated with different charms that provide core and extra functionality to the project.
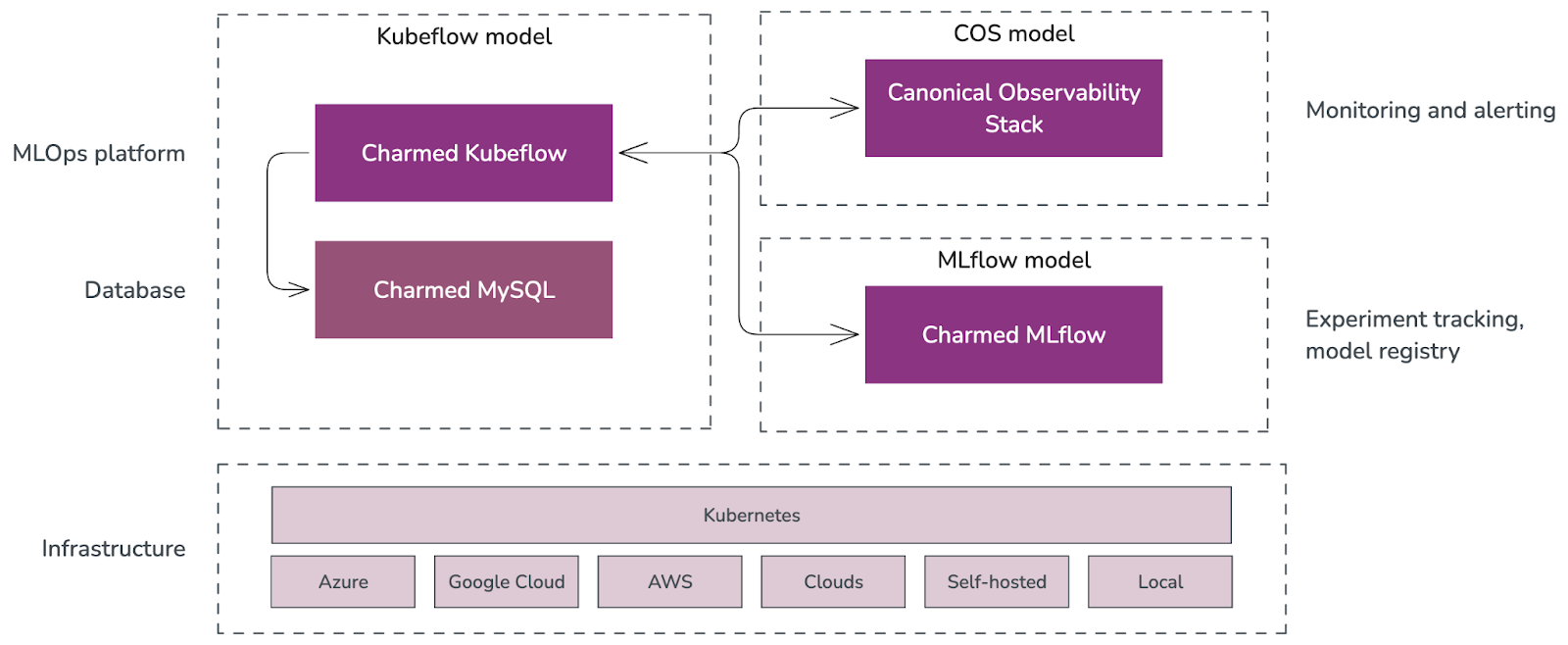
Fig 1. Charmed Kubeflow in the Juju ecosystem
From the diagram above:
- Each solution is deployed on its own Juju model, which is an abstraction that holds applications and their supporting components, such as databases, and network relations.
- Charmed MySQL provides the database support for Charmed Kubeflow and Charmed MLflow applications that require to load and store data, such as logs, resource definitions, and statuses. Charmed MySQL comes pre-bundled in the Charmed Kubeflow and Charmed MLflow bundles.
- Canonical Observability Stack gathers, processes, visualises, and alerts based on telemetry signals generated by the components that comprise Charmed Kubeflow.
- Charmed Kubeflow provides integration with Charmed MLflow capabilities like experiment tracking and model registry.
Charmed Kubeflow
Charmed Kubeflow is Canonical’s official distribution of Kubeflow.
It is an open-source, production-ready MLOps platform built on top of cloud-native technologies to develop and deploy ML applications.
CKF runs on any CNCF-compliant Kubernetes (K8s). The solution is validated on different environments, including public and private clouds, air-gapped or behind a proxy setups. See CKF official documentation for more details.
Minimum system requirements
Charmed Kubeflow is expected to be deployed in a CNCF compliant Kubernetes with these minimum requirements in the underlying infrastructure:
| Resource | Dimension |
|---|---|
| Memory (GB) | 16 |
| Storage (GB) | 50 |
| CPU processor | 4-core |
Charmed Kubeflow also works in GPU-accelerated environments. There are no minimum requirements for the number of GPUs as this will depend on the use case. For more information please refer to our various guides:
Charmed Kubeflow overview system architecture
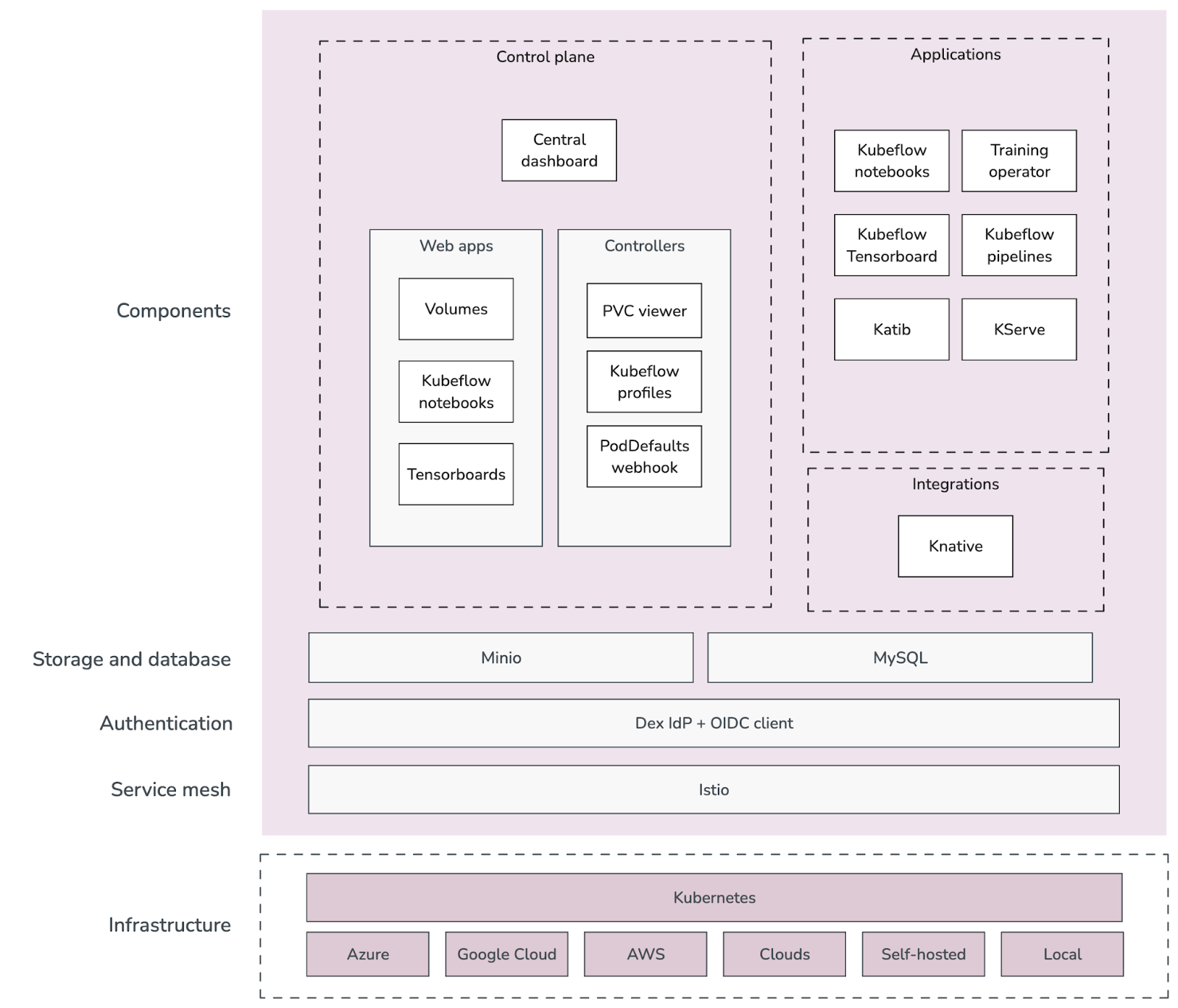
Fig 2. Charmed Kubeflow overview system architecture
Charmed Kubeflow is a cloud native application that integrates several components for developing and deploying ML workflows:
- At the infrastructure level, it can be deployed on any Cloud Native Computing Foundation (CNCF) certified Kubernetes on machines ranging from local to public clouds.
- The service mesh component is Istio used for traffic management (ingress) and access control. It is part of the Charmed Kubeflow bundle
- The authentication layer is done in conjunction with Dex IdP and an OIDC Client (usually OIDC Authservice or oauth2 proxy). It is part of the Charmed Kubeflow bundle
- The storage and database comprises MySQL and Minio, they are used as the main storage and s3 storage solutions respectively. They are commonly used for storing logs, artefacts, and workload definitions. It is part of the Charmed Kubeflow bundle.
The main components of Charmed Kubeflow can be divided into:
- Control plane - These components are responsible for the core operations of Charmed Kubeflow, such as displaying a user interface, user and authorization management, and volume management. The control plane is comprised of:
- Central dashboard - displays the web applications of different components (e.g. Kubeflow notebooks, Kubeflow pipelines).
- Web applications (web apps) - are the web UI components that provide a point of interaction between the user and their ML workloads.
- Controllers - Are all the controllers that have the business logic to manage different operations, such as profile or volume management.
- Applications - These are the components that enable and manage different user workloads, such as training, experimentation with Notebooks, ML pipelines, and model serving.
- Integrations - Charmed Kubeflow is integrated with components that may not be always enabled in upstream Kubeflow, like Knative for serverless support.
Components
Central dashboard and web apps
The central dashboard provides an authenticated web interface for Charmed Kubeflow components; it acts as a hub for the components and user workloads running in the cluster. The main features of the central dashboard include:
- Authentication and authorization based on Kubeflow profiles.
- Access to user interfaces of Kubeflow components, such as Notebook servers or Katib experiments.
- Ability to customise the links for accessing external applications.
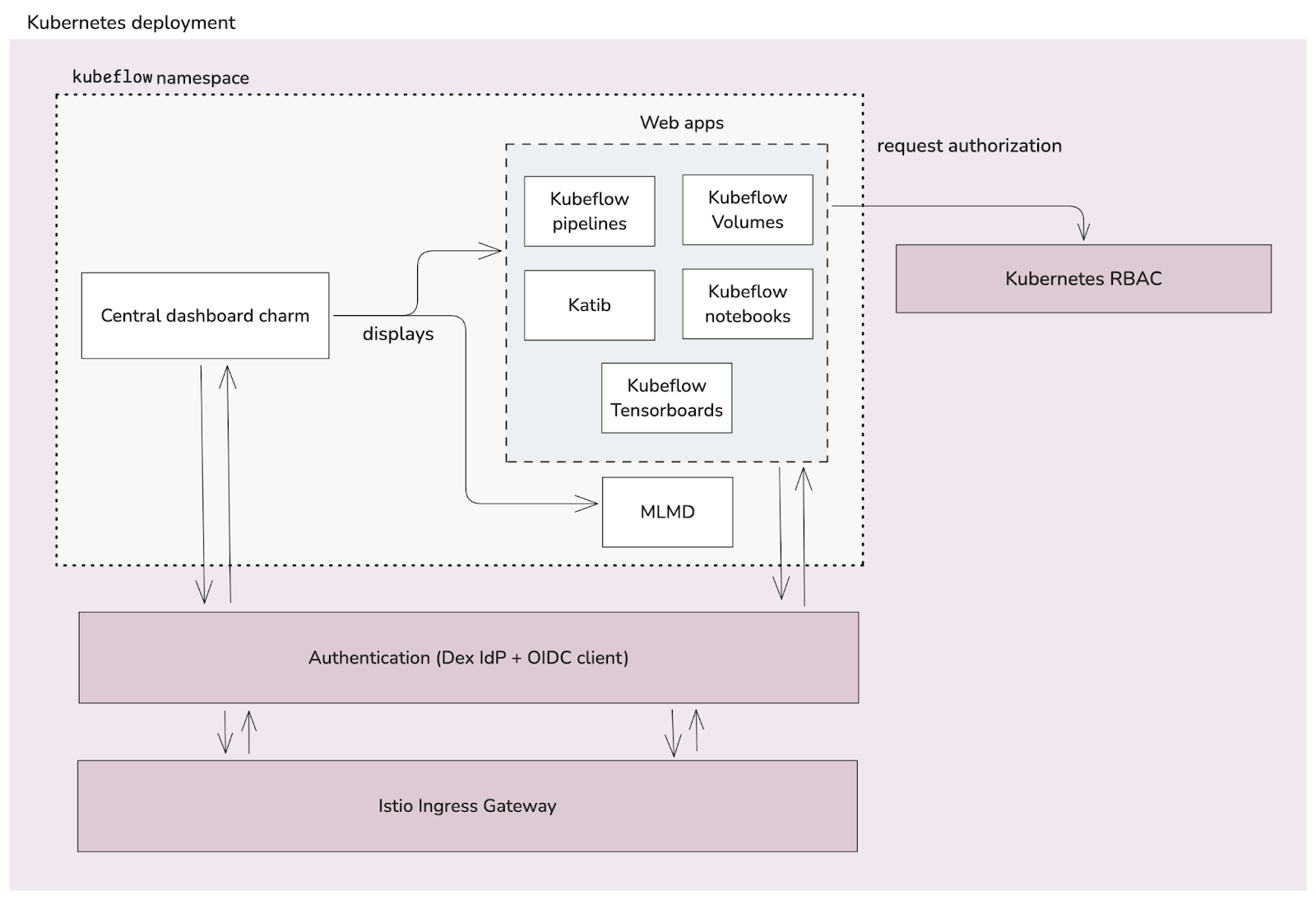
Fig 3. Central dashboard and web apps
The diagram above displays the overall operation of the Kubeflow Dashboard and how it interacts with web and Authentication/Authorisation applications.
From the diagram above:
- The central dashboard is the landing page that displays the web applications. It is integrated with Istio, Dex and the OIDC client to provide an authenticated web interface.
- The web applications give access to the various components of Charmed Kubeflow, and same as the central dashboard, they are integrated with Istio, Dex and the OIDC client to provide authentication.
- The web applications also take an important role in how users interact with the actual resources deployed in the Kubernetes cluster, as they are the ones executing actions (like create, delete, list) based on Kubernetes RBAC.
Profiles
User isolation in Charmed Kubeflow is mainly handled by the Kubeflow profiles component. In the Kubeflow context, a Profile is a Kubernetes Custom Resource Definition (CRD) that wraps a Kubernetes Namespace to add owners and contributors.
A Profile can be created by the deployment administrator via the Central dashboard or by applying a Profile Custom Resource. The deployment administrator can define the owner, contributors, and resource quotas.

Fig 4. Kubeflow profiles, overview of user isolation
From the diagram above:
- Kubeflow profiles is the component responsible for reconciling the Profile Custom Resources (CRs) that should exist in the Kubernetes deployment.
- Each Profile has a one-to-one mapping to a Namespace, which contains:
- User (admin and contributors) workloads, such as Notebooks, Pipelines and Training jobs.
- RoleBindings so users can access resources in their namespaces
- AuthorizationPolicies for access control
- Different actors can access different Profiles depending on their role:
- admins can access their own namespaces and the resources deployed in them; they can also modify contributors.
- contributors have access to the namespaces they have been granted access to, but cannot modify the contributors.
Pipelines
The pipelines component enables the development and deployment of portable and scalable ML workloads.
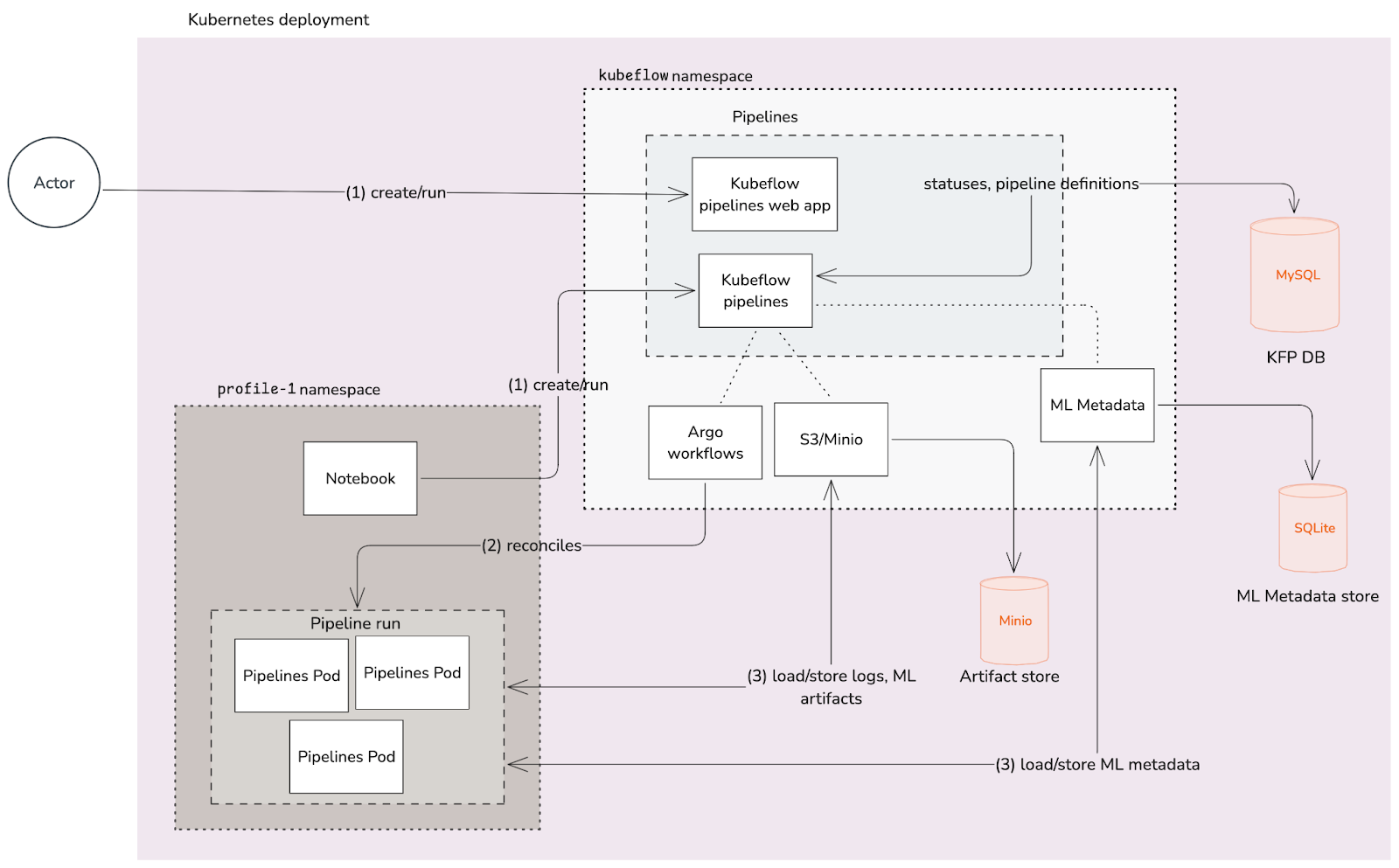
Fig 5. Kubeflow pipelines, interactions with other components and a run lifecycle
From the diagram above:
- The Pipelines web app is the user interface for managing and tracking experiments, jobs, and runs.
- The pipelines component is composed of individual units that together help provide the functionality of pipelines: scheduling workflows, visualisation, multi-user management, and the API server that manages and reconciles the operations.
- Pipelines use Argo for workflow orchestration.
- Pipelines rely on different storage and database solutions for different purposes:
- ML Metadata Store - is used for storing ML metadata, the application that handles it is called ml-metadata
- Artefact store - used for storing logs and ML artefacts resulting from each pipeline run step, the application used for this is MinIO.
- Kubeflow pipelines data base - used for storing statuses, and pipeline definitions; it usually is a MySQL database.
Pipeline runs lifecycle
- A request from the user is received, either via the web app or from a Notebook, to create a new pipeline run.
- The Argo controller will reconcile the argo workflows in the pipeline definition, creating the necessary Pods for running the various steps of the pipeline.
- During the pipeline run, each step may generate logs, ML metadata, and ML artefacts, which will be stored in the various storage solutions integrated with pipelines.
While the run is executing and after completion, users can see the result of the run, and access the logs and artefacts generated by the pipeline.
AutoML
Automated Machine Learning (AutoML) allows users with minimal knowledge of ML to create ML projects leveraging different tools and methods. In Charmed Kubeflow, AutoML is achieved using Katib, for hyperparameter tuning, early stopping, and neural architecture search, and the Training operator, for executing model training jobs.
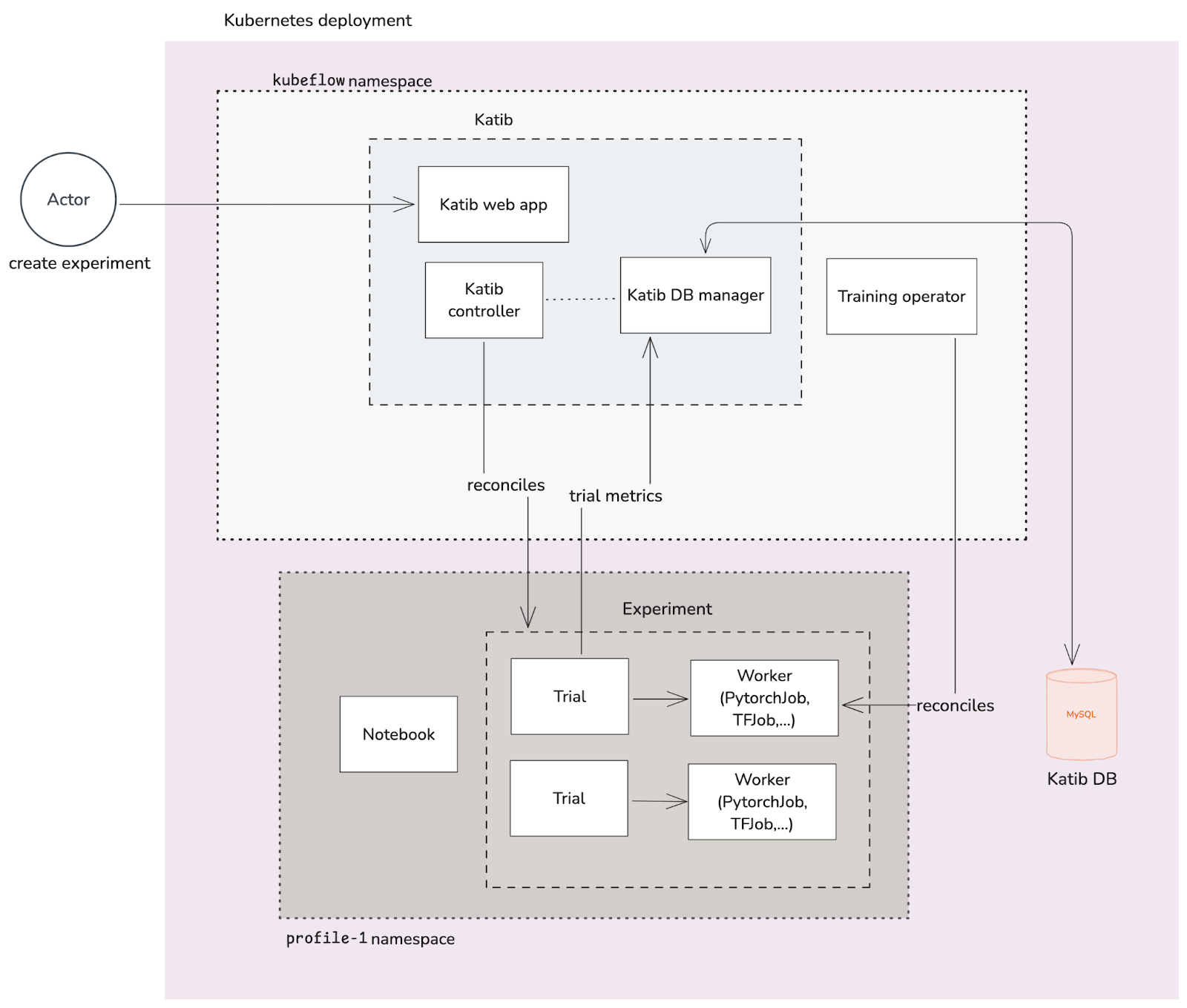
Fig 6. Kubeflow AutoML with Katib and Training Operator
From the diagram above:
- The Katib controller is responsible for reconciling Experiment CRs.
- Each Experiment is comprised of:
- Trials - an iteration of the experiment (e.g. hyperparameter tuning).
- Workers - the actual jobs that train the model, for which the Training operator is responsible for.
- The Katib web app is the main landing page for users to access and manage Experiments.
- The Katib DB manager is responsible for storing/loading the trial metrics.
Notebooks
Kubeflow Notebooks enable users to run web-based development environments. It provides support for JupyterLab, R-Studio, and Visual Studio Code.
With Kubeflow Notebooks, users can create development environments directly in the Kubernetes cluster rather than locally, where they can be shared with multiple users (if allowed).
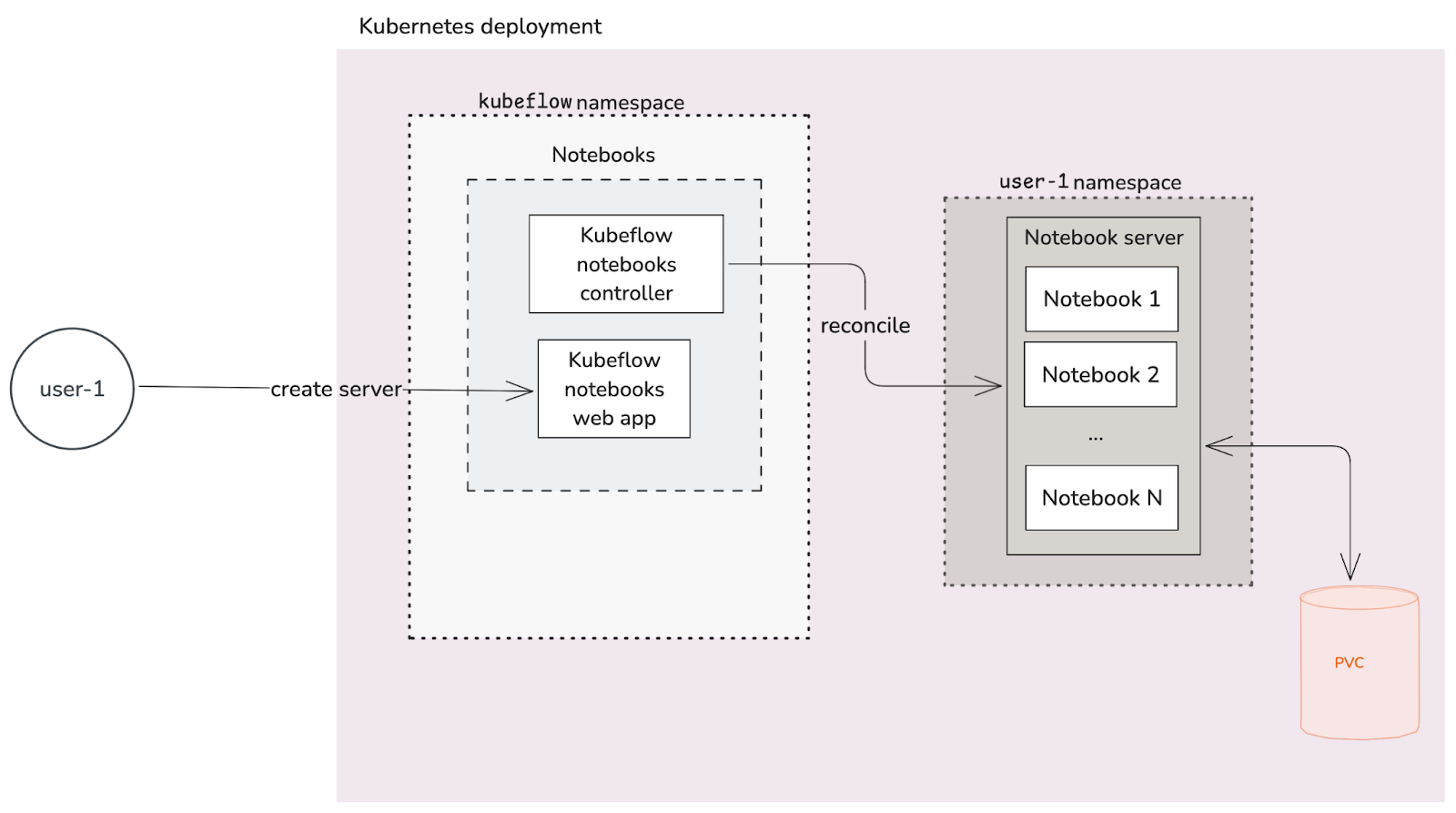
Fig 7. Kubeflow notebooks
From the diagram above:
- The Notebooks controller is responsible for reconciling the Notebook servers that must exist.
- Disambiguation: a Notebook server is the backend that provides the core functionality for running and interacting with the development environments that are Notebooks. For example, a Jupyter notebook server can hold multiple .ipynb Notebooks.
- The Notebooks web app is the landing page for users to manage and interact with the Notebook servers.
- Each Notebook server has a PersistentVolumeClaim (PVC) where the Notebooks data is stored.
KServe
Model server
A model server enables ML engineers to host models and make them accessible over a network. In Charmed Kubeflow, this is done using KServe.

Fig 8. Model server overview
From the diagram above:
- The Kserve controller reconciles the InferenceService (ISVC) CR.
- The ISVC is responsible for creating a Kubernetes Deployment with two Pods:
- Transformer - it is responsible for converting inference requests into data structures that the model can understand. It also transforms back the prediction returned by the model into predictions with labels.
- Predictor - it is responsible for pulling pre-trained models from a model registry, loading them, and returning predictions based on the inference requests.
Serverless model service
When configured in “Serverless mode”, KServe leverages the serverless capabilities of Knative. In this mode, components like Istio are leveraged for traffic management.
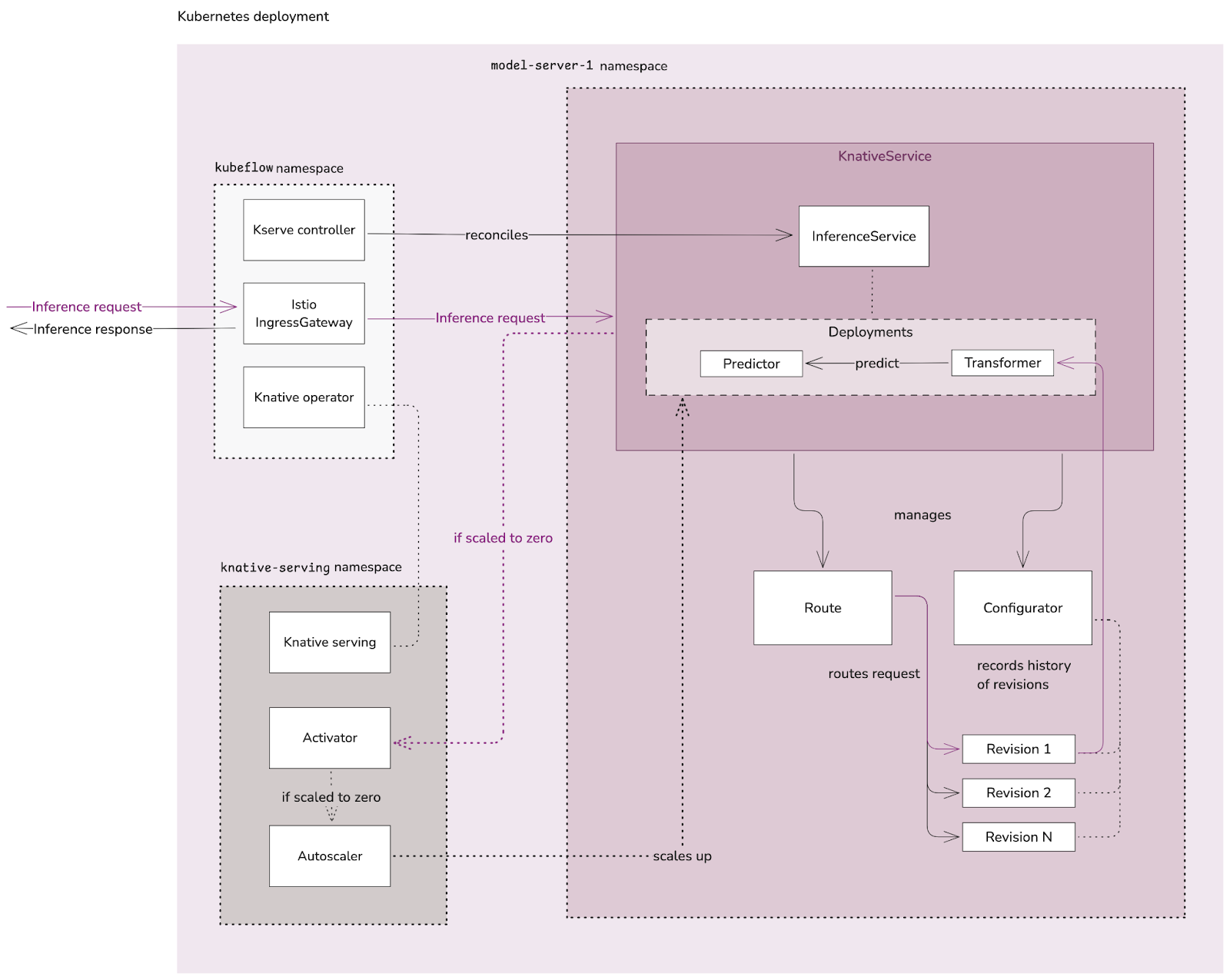
Fig 9. Serverless model server overview
From the diagram above:
- The Istio IngressGateway receives an inference request from the user and it routes it to the KnativeService (KSVC) that corresponds to the InferenceService (model server) provided this resource is exposed outside the cluster.
- The KSVC manages the workload lifecycle, in this case the ISVC. It controls the following:
- Route - routes the requests to the corresponding revision of the workload
- Configurator - records history of the multiple revisions of the workload
- The Knative serving component is responsible for reconciling the KSVCs in the Kubernetes deployment, and it also has the following components:
- Activator - it queues incoming requests and communicates with the Autoscaler to bring scaled-to-zero workloads back up.
- Autoscaler - it scales up/down the workloads.
Inference request flow
-
The Istio IngressGateway receives the inference request and directs it to the KSVC
-
If the ISVC is scaled down to zero, the Activator will request the Autoscaler to scale up the ISVC Pods…
-
Once the request reaches the KSVC, the Router ensures that the request is routed to the correct revision of the ISVC.
-
The ISVC receives the request at the Transformer Pod for request transformation.
-
Inference is performed at the Predictor Pod.
-
The response is then re-routed back to the user.
Integrations
Charmed Kubeflow integrates with various solutions of the Juju ecosystem, and it is always expanding.
Charmed MLflow
The Charmed Kubeflow bundle integrates seamlessly with the Charmed MLflow bundle for experiment tracking and as a model registry.
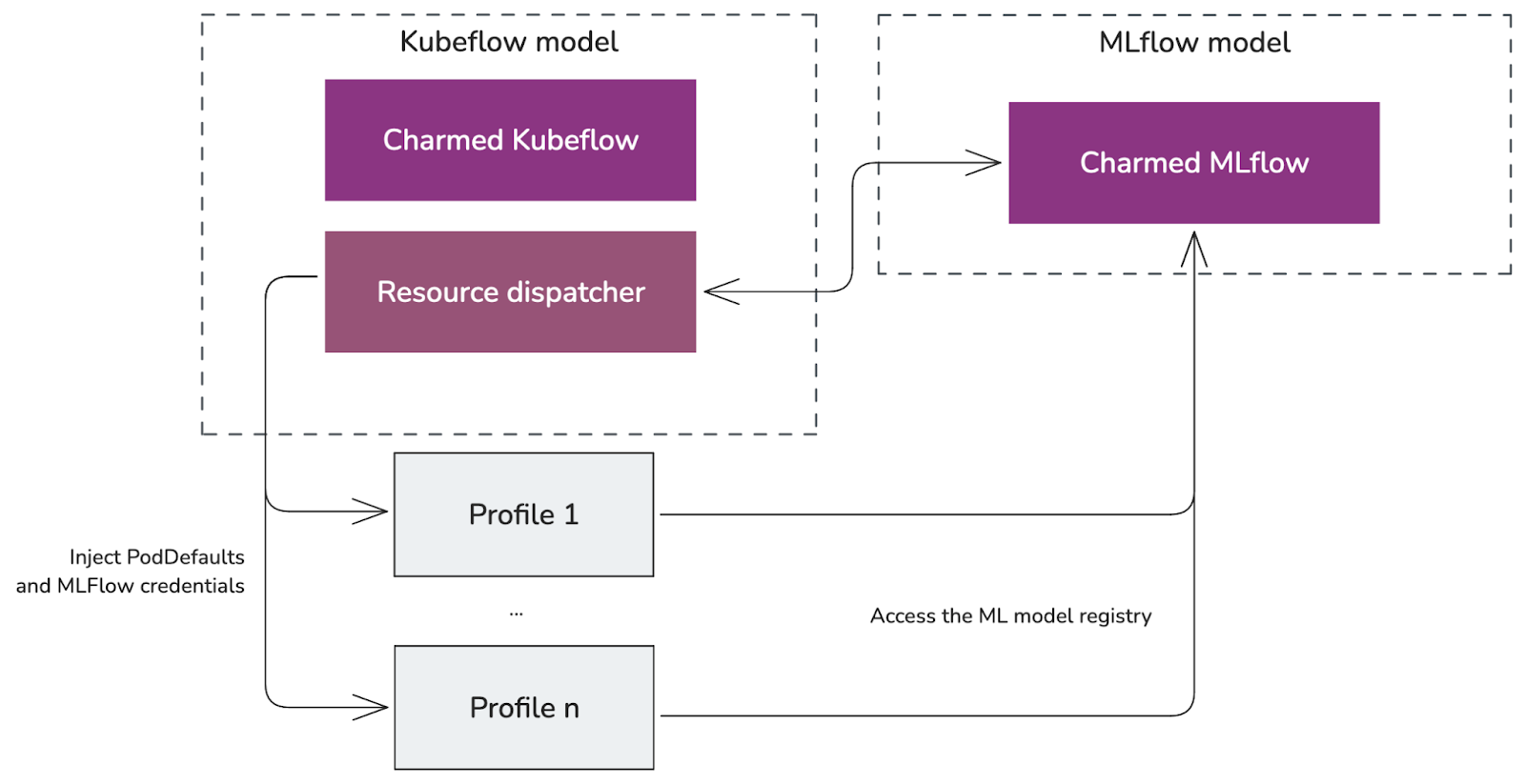
Fig 10. Charmed Kubeflow and Charmed MLflow integration
From the diagram above:
- The resource dispatcher is a component that injects PodDefaults and credentials into each user Profile to be able to access the Charmed MLflow model registry.
- PodDefaults are CRs responsible for ensuring that all Pods in a labelled Namespace get mutated as desired.
- Charmed MLflow integrates with the resource dispatcher to send its credentials and the MLflow server information (server endpoint) and the S3 storage information (Minio endpoint).
- With this integration, users can enable access to Charmed MLflow from their Notebook servers to perform experiment tracking, or access the model registry.
The Charmed MLflow is also integrated with the central dashboard and served behind the Charmed Kubeflow ingress:
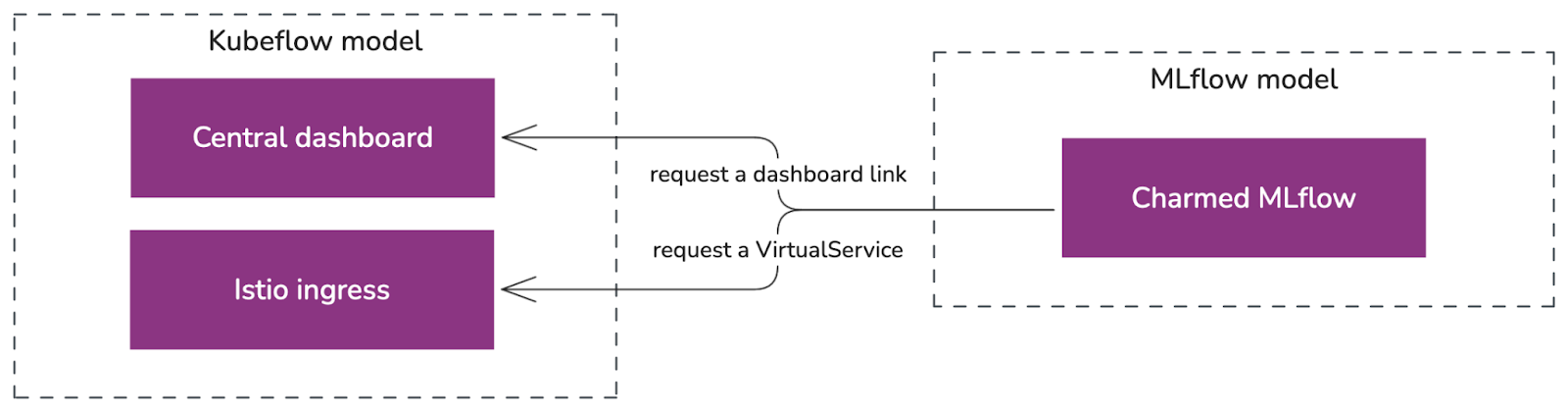
Fig 11. Integrating Charmed MLflow to the central dashboard
With this, the central dashboard will display “MLflow” in the sidebar, which users can click to access MLflow as part of the Kubeflow central dashboard.
Canonical Observability Stack (COS)
To monitor, alert, and visualise failures and metrics, the Charmed Kubeflow components are individually integrated with COS.
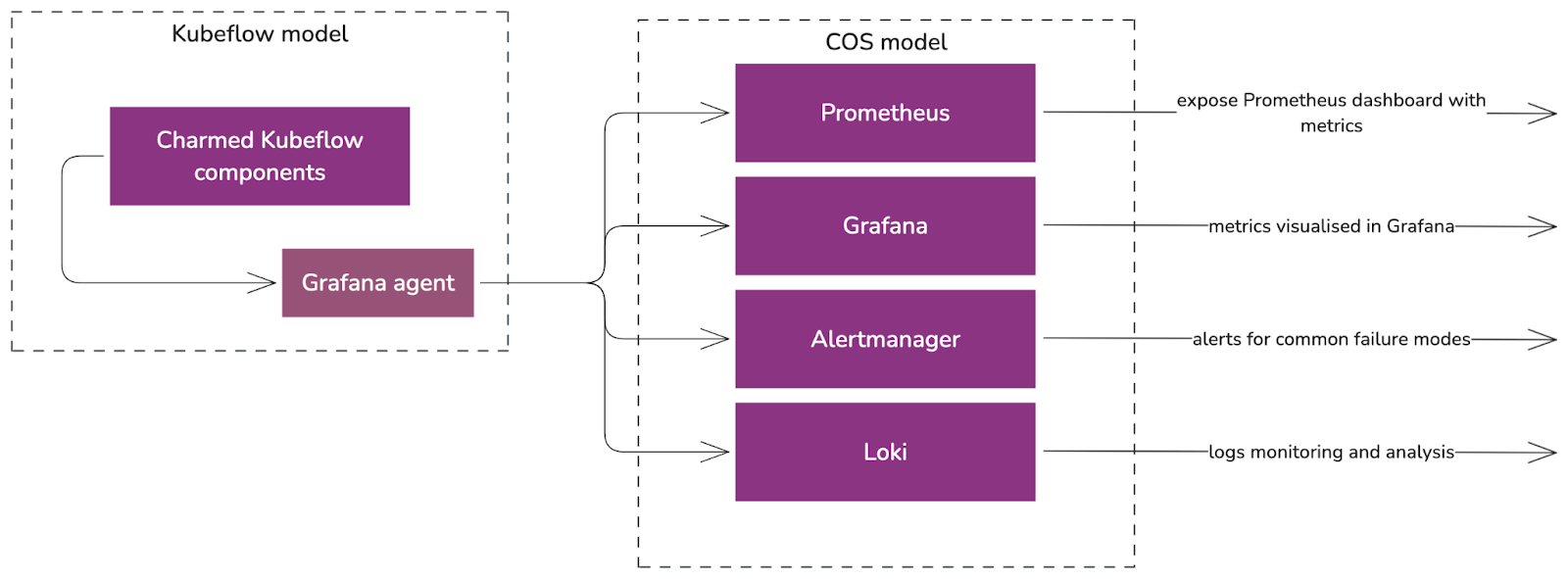
Fig 12. Integration between Charmed Kubeflow and COS
Each component of Charmed Kubeflow:
- Enables a metrics endpoint provider for Prometheus to scrape metrics from
- Has its own Grafana dashboard to visualise relevant metrics
- Has alert rules that help alert users or administrators when a common failure occurs
- Integrates with Loki for log reporting