Is anyone able to confirm if Charmed Kubeflow will be updated to 1.6.1?
There are major bugs in 1.6.0 which make it unusable in a production environment.
The notebook culling operation is causing huge issues for us which has been patched in 1.6.1. When notebooks are culled or stopped they are unable to be relaunched again.
Sorry for the delays, but we’re in the final stages of testing. We have what we think is a complete 1.6.1 now in the 1.6/edge channel (eg: juju deploy kubeflow --channel 1.6/edge --trust). I have an instance running right now, but I’m waiting for it to snooze my notebook so I can confirm the fixes are working correctly. A colleague of mine is testing the upgrade path (1.6 -> 1.6.1) right now as well.
You’re welcome to try it out from 1.6/edge or wait till hopefully Monday for us to push everything to 1.6/stable.
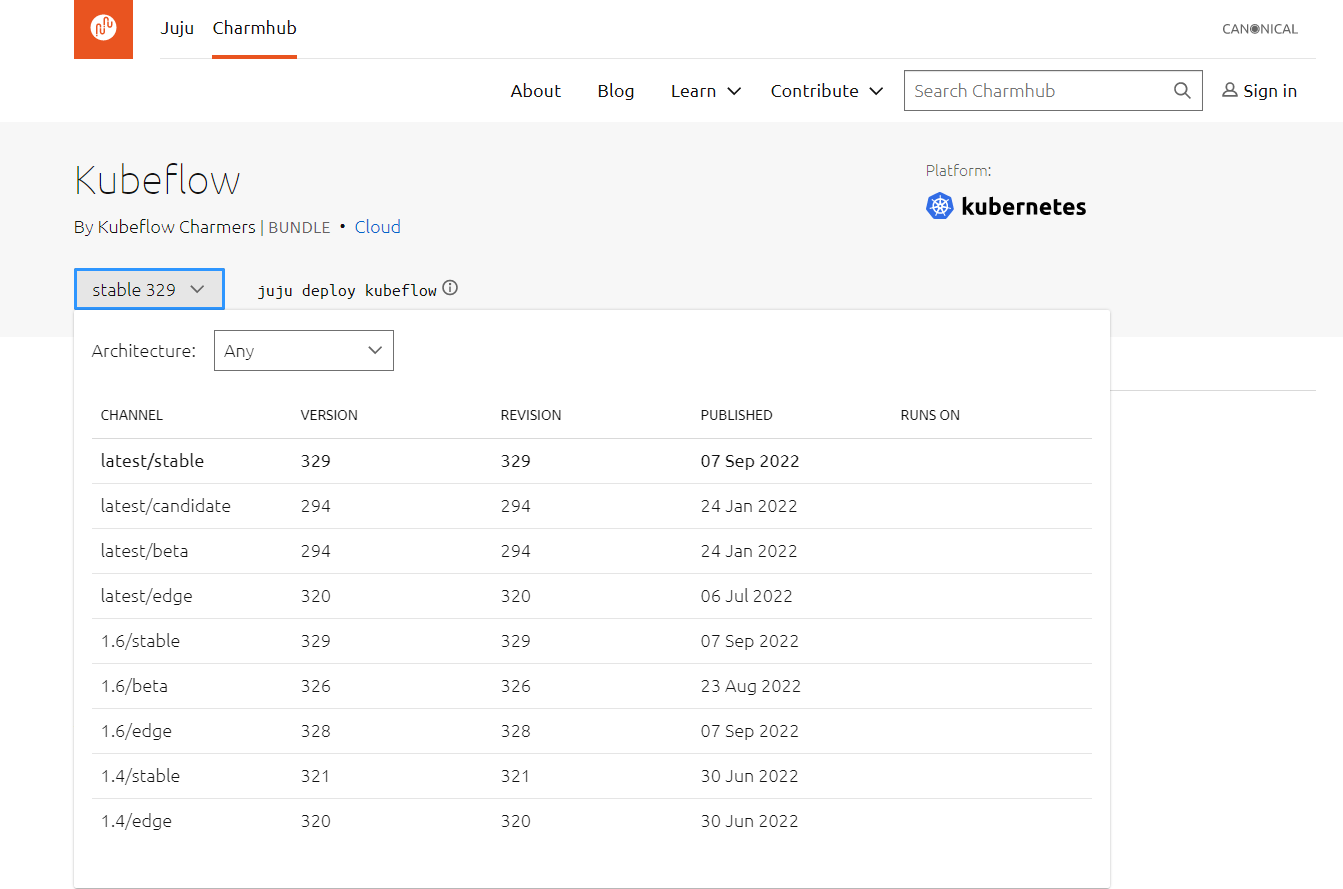
Ah sorry, this is a confusing bookkeeping thing with bundles and charm channels.
Our bundles pin to charm channels (eg: kubeflow:1.6/stable pins to kubeflow-profiles:1.6/stable), so today when we pushed updates to all the charms changed in 1.6.1, the bundle implicitly got those updates too. But because we did not change the bundle file itself, the charmhub page for the bundle shows no changes to the bundle’s definition.
@ollienuk sorry not sure what is going on here. Can you provide:
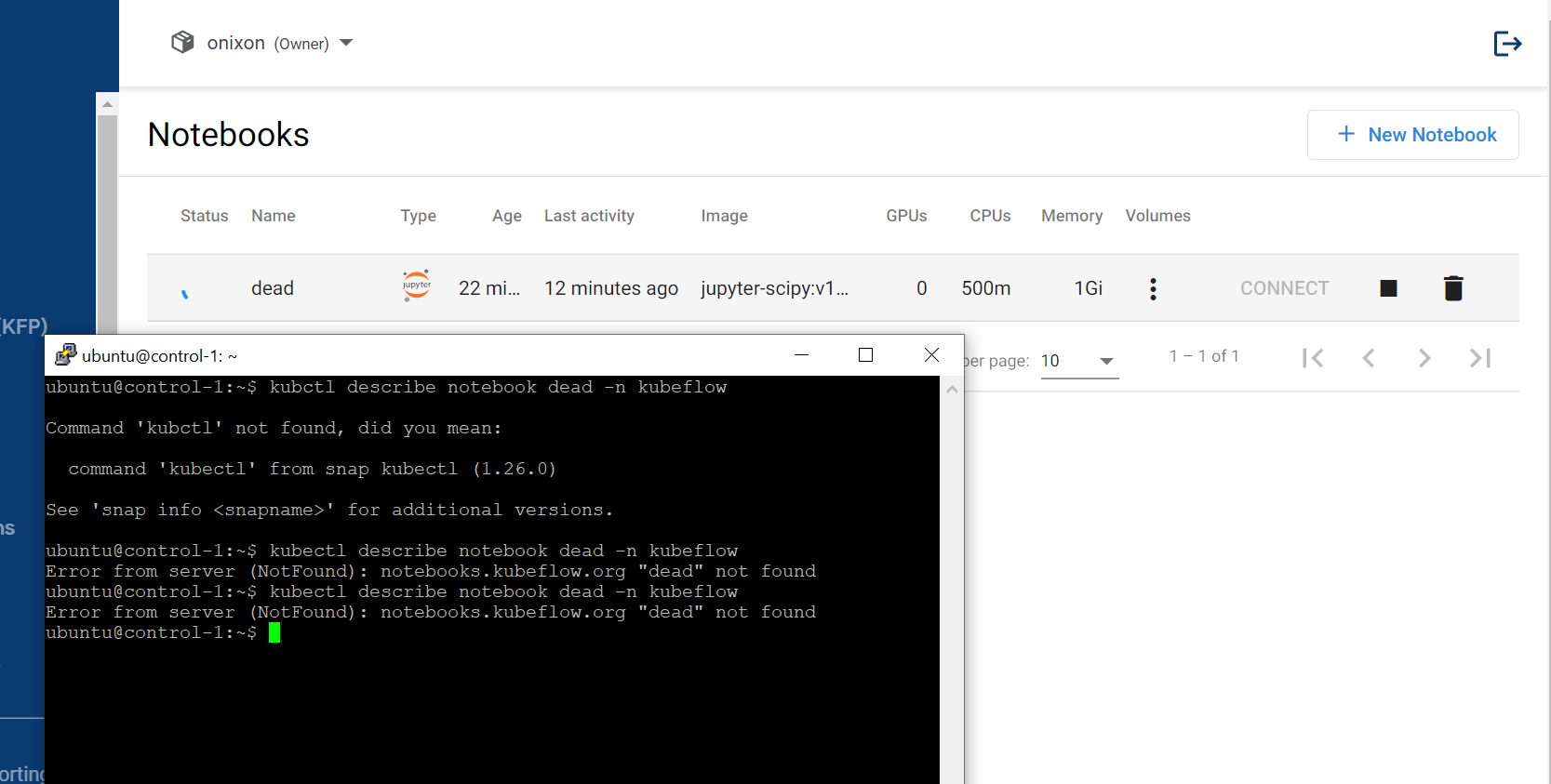
kubectl describe notebook dead
kubectl describe pod (pod-of-dead)
kubectl get events
and maybe the logs from the notebook controller (can’t remember what the pod name would be, but it should be visible in kubectl get pods -n kubeflow. If you see multiple, one will be for the charm and one the actual controller, we want the latter but feel free to post both
Oh I think the issue here is that the notebook object (and pods for the notebook) would not be in kubeflow (eg: the control plane of kubeflow) but in the namespace of the user who owns that notebook
The notebook controller would be in -n kubeflow, and the logs of that might be helpful to understand why the notebook pod is not coming back online
ubuntu@control-1:~$ kubectl get pods -n onixon
NAME READY STATUS RESTARTS AGE
ml-pipeline-ui-artifact-5cfb68f5b7-d6ll2 2/2 Running 4 (6d17h ago) 53d
ml-pipeline-visualizationserver-665bb6b8fc-qmsxb 2/2 Terminating 2 (53d ago) 53d
ml-pipeline-visualizationserver-665bb6b8fc-nrr76 2/2 Running 0 6d17h
The kubectl get events only returns events about pvcs not being deleted in other namespaces by other users:
Warning VolumeFailedDelete persistentvolume/pvc-2b59a481-c08a-469f-8bf7-be9a0ed3f238 rpc error: code = DeadlineExceeded desc = context deadline exceeded
I’m not sure what is going on atm. What do the notebook controller logs say (kubectl logs (notebook-controller-pod) -n kubeflow)?
That there are no pods for dead could make sense. I should have asked for any statefulset or deployment for that (I think it should exist and be scaled down to 0). The describe for that parent object might help us
I had a separate permissions issue with our NFS storage class which was also preventing the restart. I’ve changed our configuration and it’s all good now.