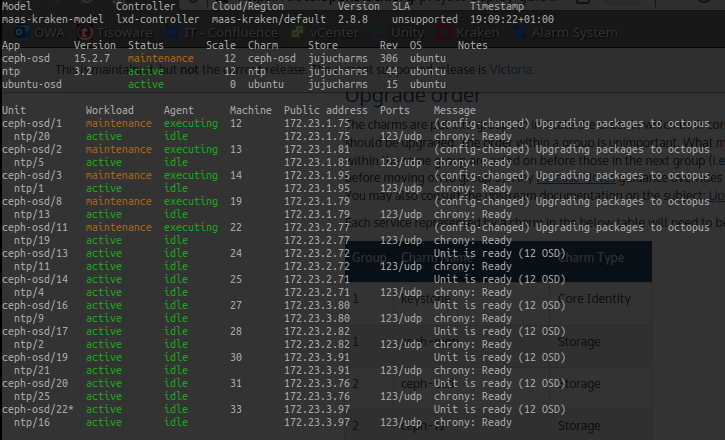
Sorry if this is the wrong forum, and advice on where to go with this.
I think I have located where I am stuck in the code, on my system it is here:
/var/lib/juju/agents/unit-ceph-osd-11/charm/lib/charms_ceph/utils.py
As shown above, I’m stuck in the config-changed hook, here is the process:
root 179235 3.7 0.0 145876 38204 ? S 16:29 7:07 python3 /var/lib/juju/agents/unit-ceph-osd-11/charm/hooks/config-changed
In the function get_all_osd_states(), the call to get_local_osd_ids() creates a list of the local OSDs:
def get_all_osd_states(osd_goal_states=None):
"""Get all OSD states or loop until all OSD states match OSD goal states.
If osd_goal_states is None, just return a dictionary of current OSD states.
If osd_goal_states is not None, loop until the current OSD states match
the OSD goal states.
:param osd_goal_states: (Optional) dict indicating states to wait for
Defaults to None
:returns: Returns a dictionary of current OSD states.
:rtype: dict
"""
osd_states = {}
for osd_num in get_local_osd_ids():
if not osd_goal_states:
osd_states[osd_num] = get_osd_state(osd_num)
else:
osd_states[osd_num] = get_osd_state(
osd_num,
osd_goal_state=osd_goal_states[osd_num])
return osd_states
Note the comment there, “loop until the current OSD states matches the OSD goal state”.
Then I found that get_local_osd_ids() producese a list of local OSDs by looking at the contents of /var/lib/ceph/osd/*:
def get_local_osd_ids():
"""This will list the /var/lib/ceph/osd/* directories and try
to split the ID off of the directory name and return it in
a list.
:returns: list. A list of osd identifiers
:raises: OSError if something goes wrong with listing the directory.
"""
osd_ids = []
osd_path = os.path.join(os.sep, 'var', 'lib', 'ceph', 'osd')
if os.path.exists(osd_path):
try:
dirs = os.listdir(osd_path)
for osd_dir in dirs:
osd_id = osd_dir.split('-')[1]
if _is_int(osd_id):
osd_ids.append(osd_id)
except OSError:
raise
return osd_ids
The problem is, that empty directories of previously purged & zapped OSDs exist on some of my ceph-osd units. On my example unit ceph-osd/11, the empty directories from July 20 2020 does not exist anymore:
root@osd11:/var/lib/ceph/osd# ls -lart
total 48
-rw------- 1 ceph ceph 69 Jul 20 2020 ceph.client.osd-upgrade.keyring
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-86
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-110
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-136
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-158
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-184
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-210
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-233
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-258
drwxr-xr-x 2 ceph ceph 4096 Jul 20 2020 ceph-280
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:48 ceph-7
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:48 ceph-34
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:48 ceph-61
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:48 ceph-72
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:49 ceph-73
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:49 ceph-74
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:49 ceph-77
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:50 ceph-78
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:50 ceph-79
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:50 ceph-80
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:50 ceph-81
drwxr-xr-x 23 ceph ceph 4096 Feb 10 00:50 .
drwxrwxrwt 2 ceph ceph 340 Feb 10 00:51 ceph-82
drwxr-x--- 15 ceph ceph 4096 Feb 10 16:37 ..
Due to this, I get stuck in an endless loop in the get_osd_state() function as I have no socket /var/run/ceph/ceph-osd.233.asok for ceph-233 for example. I seem to be stuck here in an endless loop:
def get_osd_state(osd_num, osd_goal_state=None):
"""Get OSD state or loop until OSD state matches OSD goal state.
If osd_goal_state is None, just return the current OSD state.
If osd_goal_state is not None, loop until the current OSD state matches
the OSD goal state.
:param osd_num: the osd id to get state for
:param osd_goal_state: (Optional) string indicating state to wait for
Defaults to None
:returns: Returns a str, the OSD state.
:rtype: str
"""
while True:
asok = "/var/run/ceph/ceph-osd.{}.asok".format(osd_num)
cmd = [
'ceph',
'daemon',
asok,
'status'
]
try:
result = json.loads(str(subprocess
.check_output(cmd)
.decode('UTF-8')))
except (subprocess.CalledProcessError, ValueError) as e:
log("{}".format(e), level=DEBUG)
continue
osd_state = result['state']
log("OSD {} state: {}, goal state: {}".format(
osd_num, osd_state, osd_goal_state), level=DEBUG)
if not osd_goal_state:
return osd_state
if osd_state == osd_goal_state:
return osd_state
time.sleep(3)
The first three loops in the particular unit ceph-osd/11 had success with three OSDs before getting stuck on OSD 233:
unit-ceph-osd-11-2021-02-10T17-41-05.303.log.gz:2021-02-10 16:36:53 DEBUG config-changed Reading state information...
unit-ceph-osd-11-2021-02-10T17-41-05.303.log.gz:2021-02-10 16:37:01 DEBUG config-changed Reading state information...
unit-ceph-osd-11-2021-02-10T17-41-05.303.log.gz:2021-02-10 16:37:41 DEBUG juju-log OSD 78 state: active, goal state: None
unit-ceph-osd-11-2021-02-10T17-41-05.303.log.gz:2021-02-10 16:37:41 DEBUG juju-log OSD 73 state: active, goal state: None
unit-ceph-osd-11-2021-02-10T17-41-05.303.log.gz:2021-02-10 16:37:41 DEBUG juju-log OSD 72 state: active, goal state: None
The directory /var/run/ceph only has the 12 valid sockets:
root@osd11:/var/run/ceph# ls -la
total 0
drwxrwx--- 2 ceph ceph 280 Feb 10 00:51 .
drwxr-xr-x 30 root root 1000 Feb 10 19:07 ..
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:48 ceph-osd.34.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:48 ceph-osd.61.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:48 ceph-osd.7.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:48 ceph-osd.72.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:49 ceph-osd.73.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:49 ceph-osd.74.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:49 ceph-osd.77.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:49 ceph-osd.78.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:50 ceph-osd.79.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:50 ceph-osd.80.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:50 ceph-osd.81.asok
srwxr-xr-x 1 ceph ceph 0 Feb 10 00:51 ceph-osd.82.asok
I have figured out that I can’t run juju actions (like osd-out) on the problematic nodes, the config-changed hook blocks that, although I maybe could do it manually?
Since this is “just” the config-changed hook that has been stuck during the upgrade, maybe this process can be killed?
root 179235 3.7 0.0 145876 38204 ? S 16:29 7:51 python3 /var/lib/juju/agents/unit-ceph-osd-11/charm/hooks/config-changed
The status is that the ceph packages have been upgraded, but the 12 ceph-osd processes haven’t been reloaded yet:
root@osd11:/var/run/ceph# ps auxwww | grep -i ceph
root 2244 0.0 0.0 40584 11772 ? Ss 00:43 0:00 /usr/bin/python3 /usr/bin/ceph-crash
ceph 7978 9.0 0.9 4654580 3904056 ? Ssl 00:48 103:40 /usr/bin/ceph-osd -f --cluster ceph --id 7 --setuser ceph --setgroup ceph
ceph 8775 9.4 1.0 4894340 4144852 ? Ssl 00:48 109:13 /usr/bin/ceph-osd -f --cluster ceph --id 34 --setuser ceph --setgroup ceph
ceph 9573 9.3 1.0 4921552 4170208 ? Ssl 00:48 107:12 /usr/bin/ceph-osd -f --cluster ceph --id 61 --setuser ceph --setgroup ceph
ceph 10350 9.1 0.9 4665432 3914972 ? Ssl 00:48 105:08 /usr/bin/ceph-osd -f --cluster ceph --id 72 --setuser ceph --setgroup ceph
ceph 11113 8.1 0.9 4358148 3606248 ? Ssl 00:49 93:06 /usr/bin/ceph-osd -f --cluster ceph --id 73 --setuser ceph --setgroup ceph
ceph 11857 9.5 1.0 4901808 4152348 ? Ssl 00:49 109:56 /usr/bin/ceph-osd -f --cluster ceph --id 74 --setuser ceph --setgroup ceph
ceph 12611 8.7 0.9 4620984 3869780 ? Ssl 00:49 100:16 /usr/bin/ceph-osd -f --cluster ceph --id 77 --setuser ceph --setgroup ceph
ceph 13360 8.7 1.0 4731300 3980628 ? Ssl 00:49 100:41 /usr/bin/ceph-osd -f --cluster ceph --id 78 --setuser ceph --setgroup ceph
ceph 14078 8.4 0.9 4531084 3779904 ? Ssl 00:50 97:32 /usr/bin/ceph-osd -f --cluster ceph --id 79 --setuser ceph --setgroup ceph
ceph 14815 9.2 0.9 4659480 3908848 ? Ssl 00:50 105:54 /usr/bin/ceph-osd -f --cluster ceph --id 80 --setuser ceph --setgroup ceph
ceph 15529 9.0 0.9 4669668 3918880 ? Ssl 00:50 104:11 /usr/bin/ceph-osd -f --cluster ceph --id 81 --setuser ceph --setgroup ceph
ceph 16257 8.9 0.9 4548732 3797292 ? Ssl 00:51 102:38 /usr/bin/ceph-osd -f --cluster ceph --id 82 --setuser ceph --setgroup ceph
root 126062 0.0 0.0 21776 3508 ? Ss 11:27 0:00 bash /etc/systemd/system/jujud-unit-ceph-osd-11-exec-start.sh
root 126084 0.5 0.0 835820 91400 ? Sl 11:27 2:57 /var/lib/juju/tools/unit-ceph-osd-11/jujud unit --data-dir /var/lib/juju --unit-name ceph
-osd/11 --debug
root 179235 3.7 0.0 145876 38204 ? S 16:29 7:51 python3 /var/lib/juju/agents/unit-ceph-osd-11/charm/hooks/config-changed
root 852063 0.0 0.0 14864 2680 pts/0 S+ 19:58 0:00 grep --color=auto -i ceph