
When migrating over from ubuntu 18.04 series, to 20.04, it was time to migrate the first etcd unit in my small kubernetes cluster.
However I’m stuck with the following:
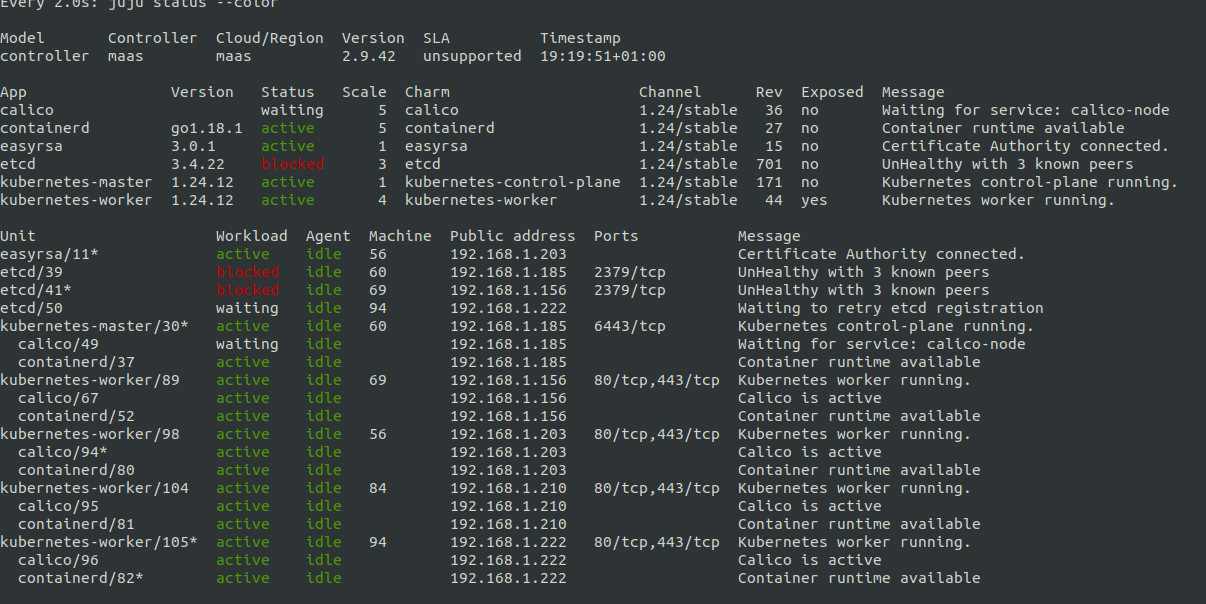
Note the “waiting to retry etcd registration”.
The debug-log of that unit says:
unit-etcd-50: 19:15:57 INFO unit.etcd/50.juju-log Reactive main running for hook update-status
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Initializing Leadership Layer (is follower)
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Initializing Snap Layer
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:18:store_ca
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:44:store_server
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:71:store_client
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:143:set_app_version
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:157:prepare_tls_certificates
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:282:set_db_ingress_address
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:289:send_cluster_connection_details
unit-etcd-50: 19:15:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:435:register_node_with_leader
unit-etcd-50: 19:15:58 ERROR unit.etcd/50.juju-log ['/snap/bin/etcd.etcdctl', '--endpoint', 'https://192.168.1.222:2379', 'member', 'list']
unit-etcd-50: 19:15:59 ERROR unit.etcd/50.juju-log {'ETCDCTL_API': '2', 'ETCDCTL_CA_FILE': '/var/snap/etcd/common/ca.crt', 'ETCDCTL_CERT_FILE': '/var/snap/etcd/common/server.crt', 'ETCDCTL_KEY_FILE': '/var/snap/etcd/common/server.key'}
unit-etcd-50: 19:15:59 ERROR unit.etcd/50.juju-log b'Error: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.1.222:2379: connect: connection refused\n\nerror #0: dial tcp 192.168.1.222:2379: connect: connection refused\n\n'
unit-etcd-50: 19:15:59 ERROR unit.etcd/50.juju-log None
unit-etcd-50: 19:15:59 INFO unit.etcd/50.juju-log etcdctl.register failed, will retry
unit-etcd-50: 19:15:59 INFO unit.etcd/50.juju-log Invoking reactive handler: hooks/relations/tls-certificates/requires.py:79:joined:certificates
unit-etcd-50: 19:15:59 INFO unit.etcd/50.juju-log status-set: waiting: Waiting to retry etcd registration
unit-etcd-50: 19:15:59 INFO juju.worker.uniter.operation ran "update-status" hook (via explicit, bespoke hook script)
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Reactive main running for hook update-status
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Initializing Leadership Layer (is follower)
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Initializing Snap Layer
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:18:store_ca
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:44:store_server
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/tls_client.py:71:store_client
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:143:set_app_version
unit-etcd-50: 19:21:57 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:157:prepare_tls_certificates
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:282:set_db_ingress_address
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:289:send_cluster_connection_details
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log Invoking reactive handler: reactive/etcd.py:435:register_node_with_leader
unit-etcd-50: 19:21:58 ERROR unit.etcd/50.juju-log ['/snap/bin/etcd.etcdctl', '--endpoint', 'https://192.168.1.222:2379', 'member', 'list']
unit-etcd-50: 19:21:58 ERROR unit.etcd/50.juju-log {'ETCDCTL_API': '2', 'ETCDCTL_CA_FILE': '/var/snap/etcd/common/ca.crt', 'ETCDCTL_CERT_FILE': '/var/snap/etcd/common/server.crt', 'ETCDCTL_KEY_FILE': '/var/snap/etcd/common/server.key'}
unit-etcd-50: 19:21:58 ERROR unit.etcd/50.juju-log b'Error: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.1.222:2379: connect: connection refused\n\nerror #0: dial tcp 192.168.1.222:2379: connect: connection refused\n\n'
unit-etcd-50: 19:21:58 ERROR unit.etcd/50.juju-log None
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log etcdctl.register failed, will retry
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log Invoking reactive handler: hooks/relations/tls-certificates/requires.py:79:joined:certificates
unit-etcd-50: 19:21:58 INFO unit.etcd/50.juju-log status-set: waiting: Waiting to retry etcd registration
unit-etcd-50: 19:21:58 INFO juju.worker.uniter.operation ran "update-status" hook (via explicit, bespoke hook script)
The etcd logs on the machine itself with journalctl:
Mar 23 18:26:35 node1 systemd[1]: snap.etcd.etcd.service: Scheduled restart job, restart counter is at 1397.
Mar 23 18:26:35 node1 systemd[1]: Stopped Service for snap application etcd.etcd.
Mar 23 18:26:35 node1 systemd[1]: Started Service for snap application etcd.etcd.
Mar 23 18:26:36 node1 etcd.etcd[2702955]: Running as system with data in /var/snap/etcd/233
Mar 23 18:26:36 node1 etcd.etcd[2702955]: Configuration from /var/snap/etcd/common/etcd.conf.yml
Mar 23 18:26:36 node1 etcd.etcd[2702955]: [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead
Mar 23 18:26:36 node1 etcd[2702955]: Loading server configuration from "/var/snap/etcd/common/etcd.conf.yml". Other configuration command line flags and environment variables will be ignored if provided.
Mar 23 18:26:36 node1 etcd[2702955]: etcd Version: 3.4.22
Mar 23 18:26:36 node1 etcd[2702955]: Git SHA: Not provided (use ./build instead of go build)
Mar 23 18:26:36 node1 etcd.etcd[2702955]: [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead
Mar 23 18:26:36 node1 etcd[2702955]: Go Version: go1.19.4
Mar 23 18:26:36 node1 etcd[2702955]: Go OS/Arch: linux/amd64
Mar 23 18:26:36 node1 etcd[2702955]: setting maximum number of CPUs to 4, total number of available CPUs is 4
Mar 23 18:26:36 node1 etcd[2702955]: the server is already initialized as member before, starting as etcd member...
Mar 23 18:26:36 node1 etcd[2702955]: peerTLS: cert = /var/snap/etcd/common/server.crt, key = /var/snap/etcd/common/server.key, trusted-ca = /var/snap/etcd/common/ca.crt, client-cert-auth = true, crl-file =
Mar 23 18:26:36 node1 etcd[2702955]: The scheme of client url http://127.0.0.1:4001 is HTTP while peer key/cert files are presented. Ignored key/cert files.
Mar 23 18:26:36 node1 etcd[2702955]: The scheme of client url http://127.0.0.1:4001 is HTTP while client cert auth (--client-cert-auth) is enabled. Ignored client cert auth for this url.
Mar 23 18:26:36 node1 etcd[2702955]: name = etcd50
Mar 23 18:26:36 node1 etcd[2702955]: data dir = /var/snap/etcd/current
Mar 23 18:26:36 node1 etcd[2702955]: member dir = /var/snap/etcd/current/member
Mar 23 18:26:36 node1 etcd[2702955]: heartbeat = 100ms
Mar 23 18:26:36 node1 etcd[2702955]: election = 1000ms
Mar 23 18:26:36 node1 etcd[2702955]: snapshot count = 10000
Mar 23 18:26:36 node1 etcd[2702955]: advertise client URLs = https://192.168.1.222:2379
Mar 23 18:26:36 node1 etcd[2702955]: cannot fetch cluster info from peer urls: could not retrieve cluster information from the given URLs
Mar 23 18:26:36 node1 systemd[1]: snap.etcd.etcd.service: Main process exited, code=exited, status=1/FAILURE
Mar 23 18:26:36 node1 systemd[1]: snap.etcd.etcd.service: Failed with result 'exit-code'.
I am at my wit’s end. Any pointers? When/how should a newly added etcd unit know about its peers?
