
As an identity team our official goal is to:
Provide a solution to cover all the company needs in the identity and access management (IAM) and authorization space
Our solution is designed to be highly modular, secure and scalable…..and…..here comes the part of the problem.
The tl:dr is that we are in charge of a bunch of components, all [un]happily interacting with each other but also with third parties and, cherry on top, having separate lifecycles ![]() .
.
To be fully confident that a feature actually works as expected, testing in isolation is not really bulletproof and we spend quite a lot of time greasing out the integrations between our different codebases, be that the standard service to service or, our favourite, backend to frontend.
We came up with an not-so-revolutionary idea: using our Prodstack as a test bed for our different environments and exploit one of our coolest products to deploy our stuff as soon as it gets released via our CI workflows.
All great so far, but, managing internal developer tooling requires balancing operational flexibility with centralized governance, we had a need to move fast and try things on the bleeding edge to be able to achieve what we needed so we went the whole hog and decided to give JIMM a crack back in Nov 2024 and since then we never looked back.
The way we manage our own internal deployment setup is by combining OpenStack and Juju Terraform Providers, we structured our setups in a multi-layered deployment (fine, let’s call it sequential steps) where we use:
-
openstack to deal with all things that are machine based, so for example our k8s and etcd clusters
-
juju (and JIMM) to manage all things k8s
The core of our infrastructure foundation is a Juju machine model kindly provided by IS, backed as usual by an openstack subnet, with a /24 CIDR range.
Inside this we manage 5 Canonical k8s clusters and 2 etcd clusters, hosted over 50 VMs, which are sealed from the outside world if not only for giving HTTPS inbound access.
Control Plane & Core Services
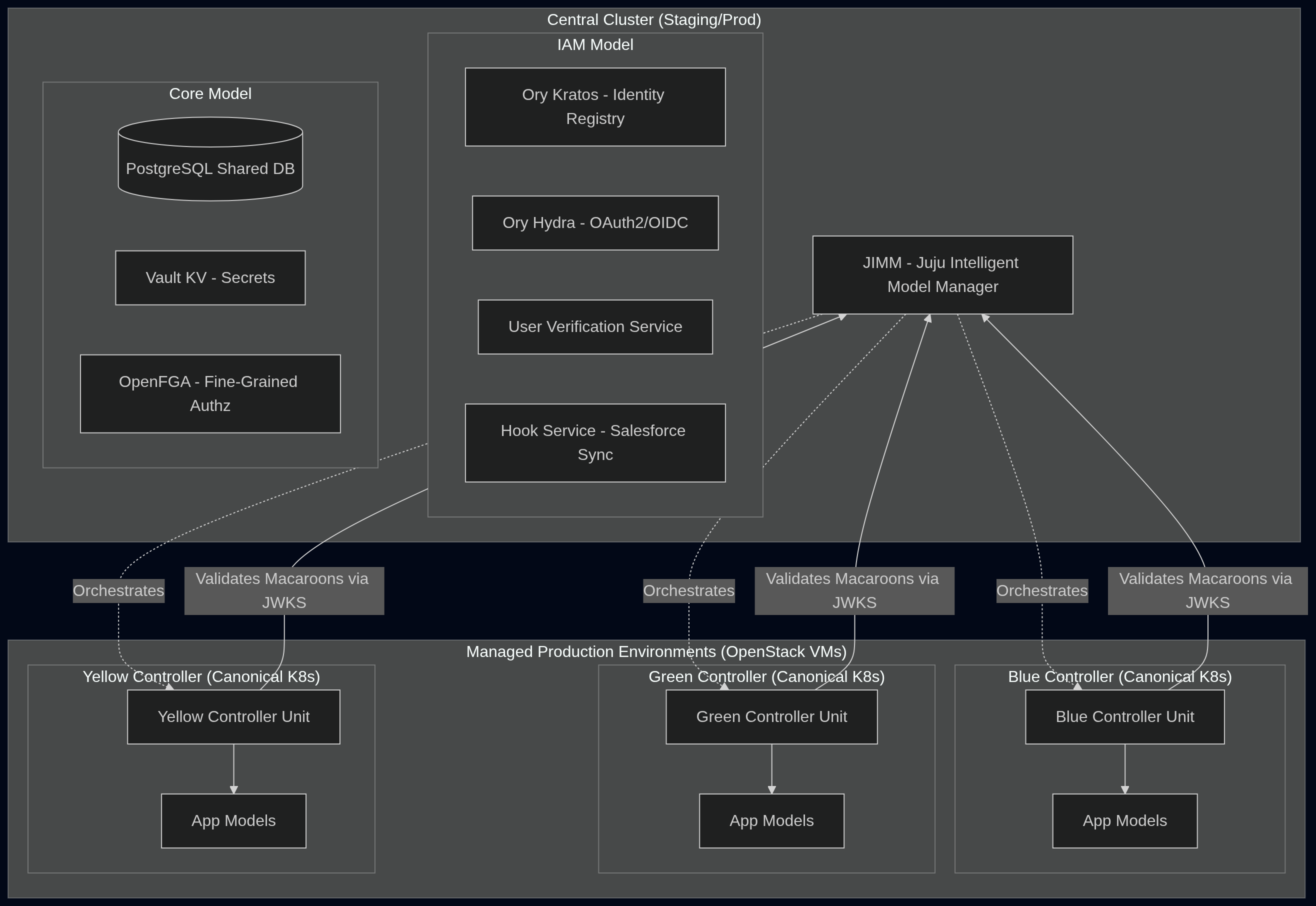
At the center of our cloud is a dedicated Canonical Kubernetes cluster named cd (Continuous Delivery), reserved for the JIMM control plane and related IAM deployment.
In this we deploy:
-
JIMM (Juju Intelligent Model Manager): The centralized gateway through which all client connections (CLI commands, Terraform scripts, dashboard requests) pass. JIMM acts as a smart proxy, routing requests to the target controller while enforcing fine-grained access control. Integrating JIMM alongside the IAM stack ensures that these two core control plane components work seamlessly together at any given time. Furthermore, JIMM gives us the flexibility to spin up new environments with minimal effort, making the recycling of a cluster a trivial “lift and shift” operation within the same Juju and network boundaries.
-
Login UI, Ory Kratos & Ory Hydra: Handle user identity registration and OAuth2/OIDC token flows. This links our central corporate identity provider (e.g., Google or Salesforce) to JIMM.
-
OpenFGA (Fine-Grained Authorization): Implements relationship-based access control (ReBAC). It maintains the graph of who has access to which models, clouds, or controllers.
-
Vault & PostgreSQL: Provide secure storage for cryptographic keys, admin credentials, and transaction histories.
-
Traefik: providing ingress capabilities to the charms that need a public access
The cd cluster is our special environment, the one that enabled us to provide the capabilities for the continuous deployment operation we were after.
Once setup, JIMM is able to govern independent controllers (see Blue, Green, Yellow) without requiring users to maintain individual credentials, during the k8s clusters’ controller bootstrap, we set login-token-refresh-url to point to the central JIMM JWKS endpoint https://jimm.iam.prod.canonical.com/cd-jimm-jimm/.well-known/jwks.json and let the magic happen.
When a team member needs to access any of the controlled environments, after enrolling into the JIMM setup, they will be able to use the company’s credentials to authenticate. This gives us a way to access remote controllers and deploy without jumping through bastions, but also it allows us to test the oauth integration between the IAM platform and JIMM

-–
How do we do this: Infrastructure as Code
Our codebase is split into reusable modules and environment instantiations to silo responsibilities between components but also to limit "blast radius” when things go south.
We follow some internal convention, where everything starts from the k8s cluster module name, a colour (red, blue, teal, purple, you pick), and once that is up, we create related juju environment modules that have that as prefix, for example green-core or blue-iam As said, our modules are more like blueprints, there is genuinely no difference between a green-* and a yellow-* if not for just the charm versions.
Disparate environments are wired together using Terraform Remote State exposing juju offers
cd-identity-core-infrastructure/
├── modules/ # Reusable Terraform Blueprints
│ ├── k8s/ # OpenStack Compute + Cloud-Init + Canonical K8s Setup
│ │ ├── cloudinit.tf # Render user-data scripts for node installation
│ │ ├── compute.tf # Provision VMs (leader and worker units)
│ │ ├── networks.tf # Networking, routers, and security groups
│ │ ├── provisioning.tf # MicroK8s/Canonical K8s join and Juju bootstrap
│ │ └── variables.tf # Resource sizing and configurations
│ ├── core/ # Core backing services (Postgres, Vault, OpenFGA)
│ ├── iam/ # Identity charms (Kratos, Hydra, OAuth Integrator)
│ ├── jimm/ # JIMM gateway charm and integrations
│ └── cos-integration/ # COS cross-model relations module
│
└── environments/ # Target Environment Instantiations
├── k8s/ # Cluster Provisioning Workspaces
│ └── prodstack/
│ └── 6/
│ ├── staging/ # Staging K8s clusters (cd, dev, playground)
│ └── production/ # Production K8s clusters (blue, green, yellow)
└── juju/ # Juju Application Workspaces
└── prodstack/
└── 6/
├── staging/ # Deployments inside the cd cluster (cd-core, cd-iam, cd-jimm)
└── production/ # Production workload models (blue-core, green-core)
Below there is an example of a a generic JIMM-managed cluster, with the separate models

CI/CD & Automation
Beyond manual infrastructure management, the architecture is designed to support automated lifecycle operations at scale.
Our JIMM-based architecture is integrated into our continuous deployment (CD) pipeline in Github, allowing us to automate and run concurrent deployments of charms without collision.
GitHub Actions Workflow Integration
When a developer pushes changes to a charm repository (e.g., [kratos-operator](GitHub - canonical/kratos-operator: A Charmed Operator for running Ory Kratos on Kubernetes · GitHub)), a release workflow publishes the updated charm to Charmhub and automatically triggers a deploy job (see [.github/workflows/publish.yaml](kratos-operator/.github/workflows/publish.yaml at main · canonical/kratos-operator · GitHub)).
This workflow delegates the deployment to a reusable CD runner defined in the identity team’s centralized repository ([charm-deploy.yaml](identity-team/.github/workflows/charm-deploy.yaml at main · canonical/identity-team · GitHub)). The workflow authenticates directly against our central JIMM endpoint using a dedicated client ID and client secret, then targets a specific model:
uses: canonical/identity-team/.github/workflows/charm-deploy.yaml@v1
with:
model: blue-iam
revision: ${{ needs.revision.outputs.revision }}
channel: ${{ needs.publish.outputs.channel }}
application: kratos
tf-application-resource: module.application.juju_application.application
secrets:
CLIENT_ID: ${{ secrets.ORANGE_CLIENT_ID }}
CLIENT_SECRET: ${{ secrets.ORANGE_CLIENT_SECRET }}
JIMM_URL: ${{ secrets.JIMM_URL }}
MODEL_UUID: ${{ secrets.ORANGE_MODEL_UUID }}
Enabling Concurrent Deployments via `juju_application` Data Sources
We are usually in active development across multiple microservices and operator charms (e.g., Kratos, Hydra, Login UI) are being updated concurrently in their respective repositories. If each charm’s repository had a monolithic Terraform workspace that managed the entire, let’s say, `blue-iam` model, they would lock each other’s states or overwrite configurations, preventing parallel CI/CD runs.
To support safe concurrent deployments, we decouple our workspaces, where each operator repository maintains its own isolated Terraform deployment with its own ephemeral state (using the terraform import directive, see [kratos-operator/deployment](kratos-operator/deployment at main · canonical/kratos-operator · GitHub)), managing **only** its own application resource.
To link with other existing services in the model, which together with core services is managed centrally, we exploit the Juju application data source (`data “juju_application”`) rather than resources:
data "juju_application" "hydra" {
count = var.enable_hydra ? 1 : 0
name = "hydra"
model_uuid = var.model
}
data "juju_offer" "traefik_route" {
url = var.traefik_route_offer_url
}
# Integrate using the retrieved database data source name:
resource "juju_integration" "hydra_public_route" {
count = var.enable_hydra ? 1 : 0
application {
offer_url = data.juju_offer.traefik_route.url
}
application {
name = data.juju_application.hydra[0].name
endpoint = "public-route"
}
model_uuid = var.model
}
Because the state file of the kratos-operator repository only tracks the kratos application resource and its specific integrations, it is completely independent of other applications. A parallel workflow running for the hydra-operator will have its own state tracking only hydra, querying JIMM using the same juju_application data source. This allows multiple GitHub actions to run and update charms concurrently in the same Juju model without locking states or causing drift on other resources.
This identical pattern of state isolation and data source dependency lookup applies to all other components in our stack, such as login-ui, hook-service and future operator additions. In this pipeline, the deployment target environment is dynamically defined by the risk channel used during release. At the moment, the blue environment tracks the bleeding-edge edge channel, while green acts as the stable environment tracking the stable channel.
> [!NOTE]
> A special shoutout to the JAAS Team for their effort in designing and delivering the juju_application data source, alongside critical features like Juju storage pool support in the Juju Terraform Provider. These integrations are the cornerstone of making Juju and Terraform play nice in enterprise CI/CD environments.
Testing & Feature Validation
Complementing the CD pipeline is a multi-tiered environment strategy that provides high-fidelity testing grounds for new features.
As previously mentioned, when running a moderately complex setup, testing features under isolation before rolling them out globally is quite paramount.
While keeping these independent environments running and continually monitored introduces obvious operational overhead, it gives us unmatched flexibility to isolate and test high-risk features.
Each environment is configured to serve a different purpose and runs its own instance of Login UI, Ory Kratos and Ory Hydra, exposing separate OIDC endpoints:
-
blue (Bleeding Edge): Used for verifying standard daily commits and integration workflows (exposed via https://iam.blue.canonical.com/.well-known/openid-configuration).
-
green (Identifier-First): Specifically dedicated to developing and testing the “identifier-first” login flow before it is promoted to production (exposed via https://iam.green.canonical.com/.well-known/openid-configuration).
-
yellow (Multi-Tenancy): Used to isolate and evaluate complex multi-tenant access models and OpenFGA relationships under load (exposed via https://iam.yellow.canonical.com/.well-known/openid-configuration).
-
red (Juju 4 Compatibility): Reserved for verifying backward compatibility and lifecycle operations under the upcoming Juju 4/stable release boundary (exposed via https://iam.red.canonical.com/.well-known/openid-configuration)
By pointing different QA integrations or test suites to the respective .well-known/openid-configuration endpoints, our engineers can validate feature functionality concurrently without the risk of contaminating the staging environment.
Conclusions
Managing our own infrastructure is no small task, but the effort has paid off significantly. We’ve enhanced our operational expertise and Terraform module design, gaining confidence that our setup is robust—not just regarding charm lifecycle management, but as a complete infrastructure solution.
Moving forward, this infrastructure serves as the blueprint for future services. By standardizing our deployment patterns, we are reducing the barrier to entry for new team members and accelerating our feature delivery cycle.
Ultimately, this investment in our platform engineering capabilities ensures we can adapt to evolving IAM requirements with agility and precision, keeping our tech stack lean, modular, and—most importantly—sustainable in the long run. Building a developer cloud with Terraform and JAAS Building a developer cloud with Terraform and JAAS