I would like to add some heat if possible to the aws security group cleanup issue that has been plaguing us for years now.
With a quick glance I can find multiple bugs for this issue stemming back to the early juju 2.x days. I’m hoping to bring this bug out front before it sneaks its way into 3.x.
Here are three bugs that seem to all be for this same issue:
The issue manifests as failed deployments with a user facing error that indicates a security group quota has been hit.
juju status shows:
Model Controller Cloud/Region Version SLA Timestamp
02a3164-centos7 osl-aws aws/us-west-2 2.8.6 unsupported 12:09:28-07:00
App Version Status Scale Charm Store Rev OS Notes
percona-cluster waiting 0/1 percona-cluster jujucharms 293 ubuntu
slurm-configurator waiting 0/1 slurm-configurator local 0 centos
slurmctld waiting 0/1 slurmctld local 0 centos
slurmd waiting 0/1 slurmd local 0 centos
slurmdbd waiting 0/1 slurmdbd local 0 centos
slurmrestd waiting 0/1 slurmrestd local 0 centos
Unit Workload Agent Machine Public address Ports Message
percona-cluster/0 waiting allocating 0 waiting for machine
slurm-configurator/0 waiting allocating 1 waiting for machine
slurmctld/0 waiting allocating 2 waiting for machine
slurmd/0 waiting allocating 3 waiting for machine
slurmdbd/0 waiting allocating 4 waiting for machine
slurmrestd/0 waiting allocating 5 waiting for machine
Machine State DNS Inst id Series AZ Message
0 pending pending bionic failed to start machine 0 (cannot set up groups: creating security group "juju-dad7c9ed-e8a5-49e9-82ce-fe6cd7a3043c": The maximum number of security groups has been reached. (SecurityGroupLimitExceeded)), retrying in 10s (5 more attempts)
1 pending pending centos7
2 pending pending centos7
3 pending pending centos7
4 pending pending centos7
5 pending pending centos7
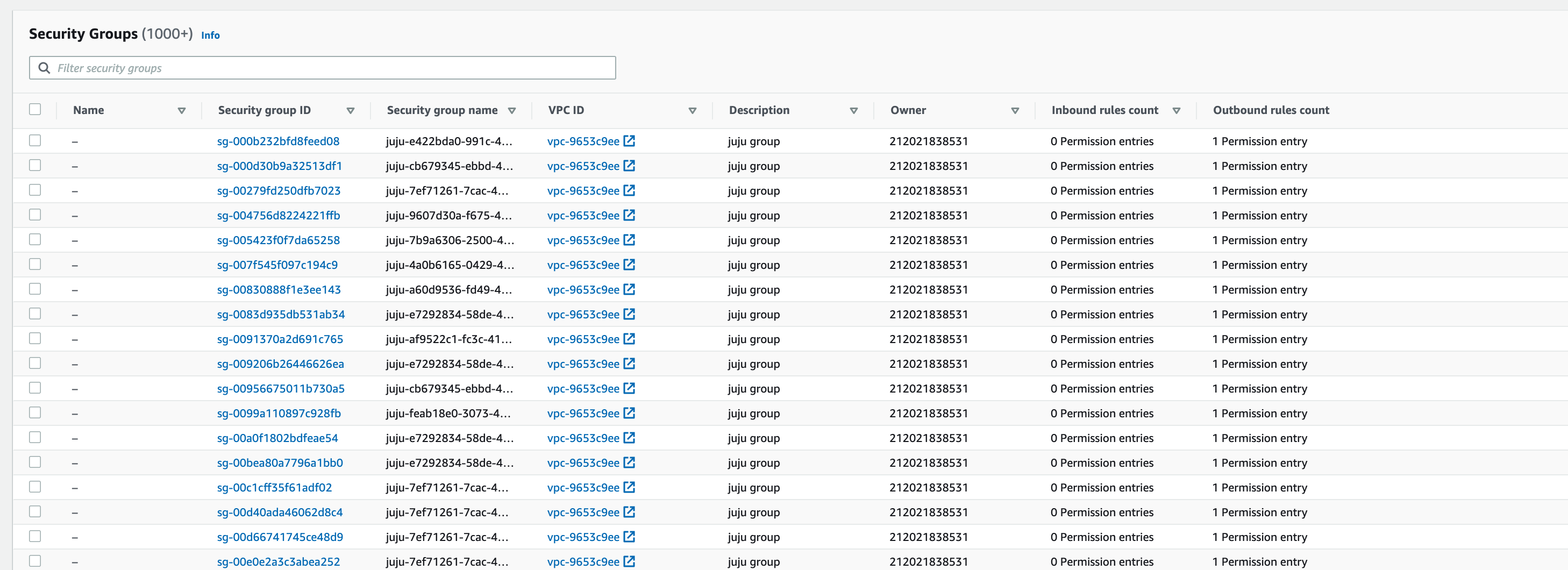
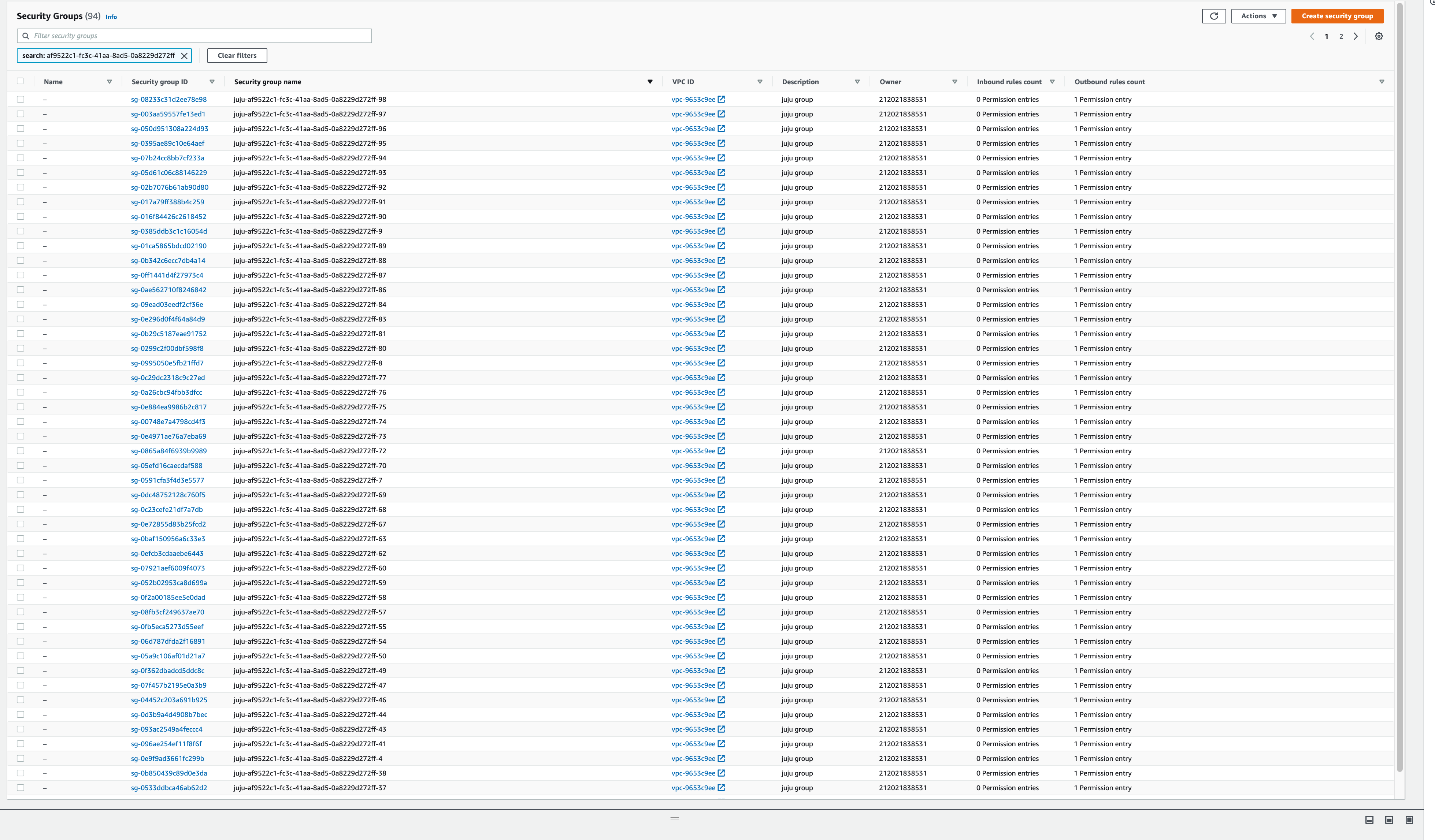
Looking at the aws console I see that I have 1000s of security groups that juju has created but has not cleaned up.
Possibly the instance is in the stopped state when then juju attempts to delete the security groups, which is why they don’t get picked up/deleted, because the instance is not yet in one of the two states; terminated, shutting-down.
Per the issue in the comments a few lines below what you have linked - possibly it is worth revisiting how security groups are cleaned up now that security groups support tagging.
I’ve marked 2 of the bugs as duplicates (essentially the same issue) and added the bug to the 2.9.1 milestone - we’re hoping to go to final 2.9 RC ASAP so it’s unlikely we’ll get a fix in 2.9.0. Hopefully we can get something done for the .1 release.
I’ve left some comments on the Launchpad bug #1720571. There’s specifically code to delete a machine’s security group when the instance is terminated, and also the model’s security group when the model is destroyed. Certainly, I was unable to reproduce the issue - I could remove machines and destroy models and verified that the security groups also were deleted.
It’s hard to tell from the screenshot what the security groups are - model or machine. The machine ones have the machine id appended at the end. The UUID in the sg name is the model UUID.
Are those groups from recent models/machines? Or are they really stale from previously?
@wallyworld +1 to doing a final swoop on the security groups when the model is deleted.
These all appear to be machine sg’s.
Lets look at a model that we have been beating on over the last few days:
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
heitor-testing osl-aws aws/us-west-2 2.8.6 unsupported 06:05:51-07:00
App Version Status Scale Charm Store Rev OS Notes
percona-cluster 5.7.20 active 1 percona-cluster jujucharms 293 ubuntu
slurm-configurator 20.11.3 active 1 slurm-configurator local 10 ubuntu
slurmctld 20.11.3 active 1 slurmctld local 8 ubuntu
slurmd 20.11.3 active 2 slurmd local 7 ubuntu
slurmdbd 20.11.3 active 1 slurmdbd local 7 ubuntu
slurmrestd 20.11.3 active 1 slurmrestd local 7 ubuntu exposed
Unit Workload Agent Machine Public address Ports Message
percona-cluster/6* active idle 131 172.31.80.140 3306/tcp Unit is ready
slurm-configurator/9* active idle 132 172.31.81.80 slurm-configurator available
slurmctld/7* active idle 133 172.31.82.149 slurmctld available
slurmd/76* active idle 134 172.31.80.8 slurmd available
slurmd/77 active idle 137 172.31.81.18 slurmd available
slurmdbd/7* active idle 135 172.31.83.34 slurmdbd available
slurmrestd/7* active idle 136 172.31.81.187 6820/tcp slurmrestd available
Machine State DNS Inst id Series AZ Message
131 started 172.31.80.140 i-00fbb042f69cf3f0a bionic us-west-2a running
132 started 172.31.81.80 i-0ee87007c9a20e401 focal us-west-2b running
133 started 172.31.82.149 i-0106ec501b722dc2f focal us-west-2c running
134 started 172.31.80.8 i-067c8cda50c8b4596 focal us-west-2a running
135 started 172.31.83.34 i-0d45f4afa74ab64f1 focal us-west-2d running
136 started 172.31.81.187 i-04820c7827657bc62 focal us-west-2b running
137 started 172.31.81.18 i-01ab82d80b9b5ba4b focal us-west-2b running
When an instance is deleted, the last thing it does is delete the associated security group.
The only thing I can think of that would prevent this is if the instance does not immediately transition to “shutting-down” state when it is terminated (it is supposed to IIANM).
In 2.8 and 2.9 edge snaps, there’s a warning logged if the instance state is not as expected after completing the request to terminate. So it would be good to know if you see such warnings. Or maybe there’s an error in your logs able not being able to delete the security group.
I haven’t been able to reproduce the issue, so any extra logging to help identify the cause would be good to have.
The code which does the instance termination in the cloud runs in the controller model. The controller logs as attached don’t show much so getting DEBUG or TRACE logging there would be good.
Was this done with the latest 2.8 or 2.9 edge snap? If so, there’s no WARNING about a terminated instance having an unexpected state so there’s no obvious reason why the security group would no have been removed.
Are the machine security groups modified in any way after Juju creates them?
I think I was mistaken about which logs were best to have. I can see in the model logs
controller-0: 06:53:48 INFO juju.worker.provisioner stopping known instances [i-0b7d25752d887d052 i-0eb35568c7d2049de i-02ad7604c89496314]
controller-0: 06:53:49 INFO juju.worker.provisioner removing dead machine "30"
controller-0: 06:53:49 INFO juju.worker.provisioner removing dead machine "28"
controller-0: 06:53:49 INFO juju.worker.provisioner removing dead machine "32"
controller-0: 06:53:49 INFO juju.worker.provisioner removing dead machine "29"
That stopping known instances line happens when “terminate” is called via the EC2 API. Juju will then ask EC2 for the security groups belonging to these terminated instances and will delete the groups. There will be a DEBUG line like this:
instance "i-0b7d25752d887d052" has security groups [<blah>]
No such line is emitted, which means that no instance security groups are found. The query is set up to use the “DescribeInstances” API call to get the instances and then read the security groups attribute, filtering on instances which are in state “shutting-down” or “terminated”. Because “terminate” was called previously, the instance should at least be “shutting-down”. The 2.8 and 2.9 edge snap emits a WARNING if the instance is not in this state… this is the only way I can see why we would not get the security groups to remove.
I can see no such warning in the logs. Can you verify that the latest 2.8 / 2.9 edge snap was used to test, or try again with the 2.8 / 2.9 edge snap. Because I can’t reproduce, we’ll need to try and get that extra logging to try and pin point why the query to get the security groups to delete is failing.
juju 2.9-rc6 will log a WARNING if the terminating instance is not in the expected state (either “shutting-down” or “terminated”) when the security groups are queried. This is the only reason I can see off hand why removing the security group would be skipped. You don’t need TRACE; the WARNING should just be logged in the model logs.
If there’s nothing there, the instance security group should be found and removed; if the removal fails, the logs should contain an error.
I’ll try again to reproduce, but so far no luck getting it to misbehave. Every time I try both the instance and security group are deleted as expected.