
This post will demonstrate how to get Spark on K8S up and running on AWS and On-Prem using the S3A protocol to access AWS S3 and Ceph S3 respectively.
Spark on Kubernetes in AWS
1) Bootstrap a Juju controller in AWS
For me, creating a controller named “k8s-spark-demo-controller” looks something like:
juju bootstrap aws/us-west-2 k8s-spark-demo-controller \
--credential jamesbeedy-pdl --to subnet=subnet-1de11955
2) Deploy K8S in AWS
Once the Juju controller is bootstrapped, let’s get k8s deployed.
Add the model that will house Kubernetes:
juju add-model k8s-core-demo-model
Added 'k8s-core-demo-model' model on aws/us-west-2 with credential 'jamesbeedy-pdl' for user 'admin'
Add the spaces you want to use in the model:
$ juju add-space nat 172.31.102.0/24 172.31.103.0/24 172.31.104.0/24 172.31.105.0/24
added space "nat" with subnets 172.31.102.0/24, 172.31.103.0/24, 172.31.104.0/24, 172.31.105.0/24
$ juju add-space igw 172.31.98.0/24 172.31.99.0/24 172.31.100.0/24
added space "igw" with subnets 172.31.100.0/24, 172.31.98.0/24, 172.31.99.0/24
juju status should now show an empty model, and juju spaces should show our subnets/spaces.
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
k8s-core-demo-model k8s-spark-demo-controller aws/us-west-2 2.7-rc3 unsupported 22:14:36Z
Model "admin/k8s-core-demo-model" is empty.
$ juju spaces
Space Name Subnets
0 alpha 172.31.0.0/20
172.31.101.0/24
172.31.16.0/20
172.31.240.0/24
172.31.241.0/24
172.31.242.0/24
172.31.32.0/20
172.31.97.0/24
252.0.0.0/12
252.101.0.0/16
252.16.0.0/12
252.240.0.0/16
252.241.0.0/16
252.242.0.0/16
252.32.0.0/12
252.97.0.0/16
2 igw 172.31.100.0/24
172.31.98.0/24
172.31.99.0/24
252.100.0.0/16
252.98.0.0/16
252.99.0.0/16
1 nat 172.31.102.0/24
172.31.103.0/24
172.31.104.0/24
172.31.105.0/24
252.102.0.0/16
252.103.0.0/16
252.104.0.0/16
252.105.0.0/16
Use juju deploy to add the Kubernetes infrastructure to the model.
$ juju deploy cs:~omnivector/bundle/kubernetes-core-aws --trust
Located bundle "cs:~omnivector/bundle/kubernetes-core-aws-4"
Resolving charm: cs:~containers/aws-integrator-10
Resolving charm: cs:~containers/containerd-33
Resolving charm: cs:~containers/easyrsa-278
Resolving charm: cs:~containers/etcd-460
Resolving charm: cs:~containers/flannel-450
Resolving charm: cs:~containers/kubernetes-master-754
Resolving charm: cs:~containers/kubernetes-worker-590
Executing changes:
- upload charm cs:~containers/aws-integrator-10 for series bionic
- deploy application aws-integrator on bionic using cs:~containers/aws-integrator-10
added resource aws-cli
- set annotations for aws-integrator
- upload charm cs:~containers/containerd-33 for series bionic
- deploy application containerd on bionic using cs:~containers/containerd-33
- set annotations for containerd
- upload charm cs:~containers/easyrsa-278 for series bionic
- deploy application easyrsa on bionic using cs:~containers/easyrsa-278
added resource easyrsa
- set annotations for easyrsa
- upload charm cs:~containers/etcd-460 for series bionic
- deploy application etcd on bionic using cs:~containers/etcd-460
added resource core
added resource etcd
added resource snapshot
- set annotations for etcd
- upload charm cs:~containers/flannel-450 for series bionic
- deploy application flannel on bionic using cs:~containers/flannel-450
added resource flannel-amd64
added resource flannel-arm64
added resource flannel-s390x
- set annotations for flannel
- upload charm cs:~containers/kubernetes-master-754 for series bionic
- deploy application kubernetes-master on bionic using cs:~containers/kubernetes-master-754
added resource cdk-addons
added resource core
added resource kube-apiserver
added resource kube-controller-manager
added resource kube-proxy
added resource kube-scheduler
added resource kubectl
- expose kubernetes-master
- set annotations for kubernetes-master
- upload charm cs:~containers/kubernetes-worker-590 for series bionic
- deploy application kubernetes-worker on bionic using cs:~containers/kubernetes-worker-590
added resource cni-amd64
added resource cni-arm64
added resource cni-s390x
added resource core
added resource kube-proxy
added resource kubectl
added resource kubelet
- expose kubernetes-worker
- set annotations for kubernetes-worker
- add relation kubernetes-master:kube-api-endpoint - kubernetes-worker:kube-api-endpoint
- add relation kubernetes-master:kube-control - kubernetes-worker:kube-control
- add relation kubernetes-master:certificates - easyrsa:client
- add relation kubernetes-master:etcd - etcd:db
- add relation kubernetes-worker:certificates - easyrsa:client
- add relation etcd:certificates - easyrsa:client
- add relation flannel:etcd - etcd:db
- add relation flannel:cni - kubernetes-master:cni
- add relation flannel:cni - kubernetes-worker:cni
- add relation containerd:containerd - kubernetes-worker:container-runtime
- add relation containerd:containerd - kubernetes-master:container-runtime
- add relation aws-integrator:aws - kubernetes-master:aws
- add relation aws-integrator:aws - kubernetes-worker:aws
- add unit aws-integrator/0 to new machine 0
- add unit kubernetes-master/0 to new machine 1
- add unit kubernetes-worker/0 to new machine 2
- add unit kubernetes-worker/1 to new machine 3
- add unit kubernetes-worker/2 to new machine 4
- add unit kubernetes-worker/3 to new machine 5
- add unit kubernetes-worker/4 to new machine 6
- add unit kubernetes-worker/5 to new machine 7
- add lxd container 1/lxd/0 on new machine 1
- add unit easyrsa/0 to 1/lxd/0 to satisfy [lxd:kubernetes-master/0]
- add unit etcd/0 to new machine 1 to satisfy [kubernetes-master/0]
Deploy of bundle completed.
Wait a few moments for the deploy to settle and for Kubernetes to become available.
juju status should resemble the following:
$ juju status -m k8s-core-demo-model
Model Controller Cloud/Region Version SLA Timestamp
k8s-core-demo-model k8s-spark-demo-controller aws/us-west-2 2.7-rc3 unsupported 23:11:09Z
App Version Status Scale Charm Store Rev OS Notes
aws-integrator 1.16.266 active 1 aws-integrator jujucharms 10 ubuntu
containerd active 7 containerd jujucharms 33 ubuntu
easyrsa 3.0.1 active 1 easyrsa jujucharms 278 ubuntu
etcd 3.2.10 active 1 etcd jujucharms 460 ubuntu
flannel 0.11.0 active 7 flannel jujucharms 450 ubuntu
kubernetes-master 1.16.2 active 1 kubernetes-master jujucharms 754 ubuntu exposed
kubernetes-worker 1.16.2 active 6 kubernetes-worker jujucharms 590 ubuntu exposed
Unit Workload Agent Machine Public address Ports Message
aws-integrator/0* active idle 0 172.31.104.99 Ready
easyrsa/0* active idle 1/lxd/0 252.98.207.133 Certificate Authority connected.
etcd/0* active idle 1 52.88.117.155 2379/tcp Healthy with 1 known peer
kubernetes-master/0* active idle 1 52.88.117.155 6443/tcp Kubernetes master running.
containerd/5 active idle 52.88.117.155 Container runtime available
flannel/5 active idle 52.88.117.155 Flannel subnet 10.1.24.1/24
kubernetes-worker/0* active idle 2 52.88.118.248 80/tcp,443/tcp Kubernetes worker running.
containerd/0* active idle 52.88.118.248 Container runtime available
flannel/0* active idle 52.88.118.248 Flannel subnet 10.1.98.1/24
kubernetes-worker/1 active idle 3 54.186.170.234 80/tcp,443/tcp Kubernetes worker running.
containerd/6 active idle 54.186.170.234 Container runtime available
flannel/6 active idle 54.186.170.234 Flannel subnet 10.1.21.1/24
kubernetes-worker/2 active idle 4 54.148.85.62 80/tcp,443/tcp Kubernetes worker running.
containerd/4 active idle 54.148.85.62 Container runtime available
flannel/4 active idle 54.148.85.62 Flannel subnet 10.1.88.1/24
kubernetes-worker/3 active idle 5 52.39.49.102 80/tcp,443/tcp Kubernetes worker running.
containerd/3 active idle 52.39.49.102 Container runtime available
flannel/3 active idle 52.39.49.102 Flannel subnet 10.1.68.1/24
kubernetes-worker/4 active idle 6 54.191.117.56 80/tcp,443/tcp Kubernetes worker running.
containerd/2 active idle 54.191.117.56 Container runtime available
flannel/2 active idle 54.191.117.56 Flannel subnet 10.1.26.1/24
kubernetes-worker/5 active idle 7 18.236.232.236 80/tcp,443/tcp Kubernetes worker running.
containerd/1 active idle 18.236.232.236 Container runtime available
flannel/1 active idle 18.236.232.236 Flannel subnet 10.1.84.1/24
Machine State DNS Inst id Series AZ Message
0 started 172.31.104.99 i-0dfcaedf7640e9880 bionic us-west-2c running
1 started 52.88.117.155 i-0f8aedeae90e65b67 bionic us-west-2c running
1/lxd/0 started 252.98.207.133 juju-30cf80-1-lxd-0 bionic us-west-2c Container started
2 started 52.88.118.248 i-0227f55c35dd14d2d bionic us-west-2b running
3 started 54.186.170.234 i-039fd2917095b7ede bionic us-west-2c running
4 started 54.148.85.62 i-09e317b362ffbf0e2 bionic us-west-2c running
5 started 52.39.49.102 i-096c1449c8fd1d232 bionic us-west-2b running
6 started 54.191.117.56 i-0646a1dbe0ddd7fd3 bionic us-west-2a running
7 started 18.236.232.236 i-0b12a0d885d41d67a bionic us-west-2c running
3) Add the Kubernetes you just deployed to your Juju controller and prepare for use with Juju.
Scp the KUBECONFIG to your local box.
mkdir ~/.spark_aws_kube
juju scp kubernetes-master/0:config ~/.spark_aws_kube
export KUBECONFIG=~/.spark_aws_kube/config
Create a ebs-aws storage class to use using the ebs-provisioner
$ kubectl create -f - <<EOY
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-1
provisioner: kubernetes.io/aws-ebs
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp2
EOY
Add the Kubernetes cloud definition to your Juju controller.
$ juju add-k8s k8s-spark-demo-cloud --controller k8s-spark-demo-controller
k8s substrate added as cloud "k8s-spark-demo-cloud" with storage provisioned
by the existing "ebs-1" storage class.
Add a Juju model to your controller in the “k8s-spark-demo-cloud”.
juju add-model jupyter-spark-demo-model k8s-spark-demo-cloud
Added 'jupyter-spark-demo-model' model on k8s-spark-demo-cloud/default with credential 'k8s-spark-demo-cloud' for user 'admin'
At this point you should have an empty Juju Kubernetes model to which can deploy a Juju Kubernetes Charm.
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
jupyter-spark-demo-model k8s-spark-demo-controller k8s-spark-demo-cloud/default 2.7-rc3 unsupported 22:50:57Z
Model "admin/jupyter-spark-demo-model" is empty.
4) Deploy the Jupyter application to Kubernetes and Login to the GUI
juju deploy cs:~omnivector/jupyter-k8s
Set an external hostname (if you don’t plan on using dns this can be a dummy value), and expose the service.
$ juju config jupyter-k8s juju-external-hostname=jupyter.example.com
$ juju expose jupyter-k8s
Following a few moments time your Juju status should settle and resemble:
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
jupyter-spark-demo-model k8s-spark-demo-controller k8s-spark-demo-cloud/default 2.7-rc3 unsupported 22:57:11Z
App Version Status Scale Charm Store Rev OS Address Notes
jupyter-k8s active 1 jupyter-k8s jujucharms 13 kubernetes exposed
Unit Workload Agent Address Ports Message
jupyter-k8s/0* active idle 10.1.26.3 9999/TCP
Use kubectl to get the service endpoint.
$ kubectl get services -n jupyter-spark-demo-model
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
jupyter-k8s LoadBalancer 10.152.183.241 ab5611313da664be0b75d8016bbb6302-892692105.us-west-2.elb.amazonaws.com 9999:31885/TCP 3s
jupyter-k8s-endpoints ClusterIP None <none> <none> 3s
jupyter-k8s-operator ClusterIP 10.152.183.71 <none> 30666/TCP 55s
Accessing ab5611313da664be0b75d8016bbb6302-892692105.us-west-2.elb.amazonaws.com:9999 in the browser gives:
Retrieve the password from the charm config and login to the Jupyter gui.
$ juju config jupyter-k8s jupyter-password
Upon logging in you will find a notebook with 2 predefined pyspark example cells. The first will run the computation using spark local deploy-mode, the second cell uses the Kubernetes backend.
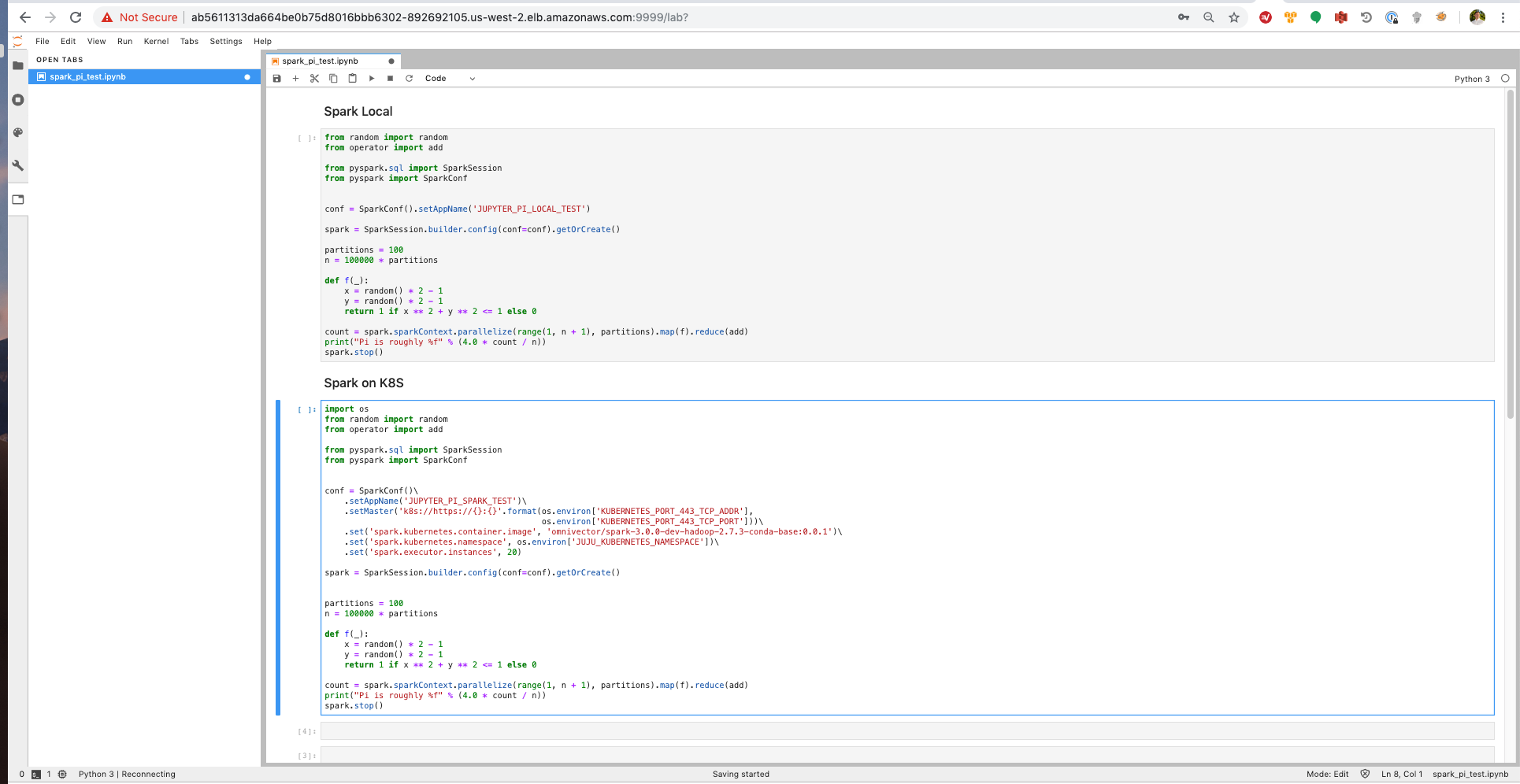
Go ahead and execute the cell underneath the “Spark on K8S” header, and view the pods that launch in the namespace of your model to see the spark executor containers at work.
$ kubectl get pods -n jupyter-spark-demo-model
NAME READY STATUS RESTARTS AGE
jupyter-k8s-0 1/1 Running 0 14m
jupyter-k8s-operator-0 1/1 Running 0 14m
jupyterpisparktest-1a396c6e5799dd2a-exec-6 1/1 Running 0 26s
jupyterpisparktest-233e9d6e579a2fb4-exec-20 1/1 Running 0 4s
jupyterpisparktest-3189746e5799de90-exec-10 1/1 Running 0 25s
jupyterpisparktest-3de89f6e579a25c7-exec-14 1/1 Running 0 7s
jupyterpisparktest-459f916e579a2df6-exec-16 1/1 Running 0 5s
jupyterpisparktest-54f1546e5799d429-exec-1 1/1 Running 0 28s
jupyterpisparktest-55a6006e5799d52d-exec-5 1/1 Running 0 28s
jupyterpisparktest-646a546e579a25f3-exec-15 1/1 Running 0 7s
jupyterpisparktest-baa76a6e579a2f30-exec-19 1/1 Running 0 5s
jupyterpisparktest-c27db76e5799dd81-exec-7 1/1 Running 0 26s
jupyterpisparktest-e05fae6e5799ddc9-exec-8 1/1 Running 0 26s
jupyterpisparktest-e280f16e5799d4fa-exec-4 1/1 Running 0 28s
jupyterpisparktest-e78ac16e579a2ebb-exec-18 1/1 Running 0 5s
jupyterpisparktest-e8199d6e579a2e3e-exec-17 1/1 Running 0 5s
jupyterpisparktest-ec86796e579a2567-exec-12 1/1 Running 0 7s
jupyterpisparktest-ee6ecc6e5799d4cc-exec-3 1/1 Running 0 28s
jupyterpisparktest-f1d6af6e579a2532-exec-11 1/1 Running 0 7s
jupyterpisparktest-f7c3646e579a2594-exec-13 1/1 Running 0 7s
jupyterpisparktest-f823996e5799d491-exec-2 1/1 Running 0 28s
jupyterpisparktest-f8b3d86e5799de2a-exec-9 1/1 Running 0 25s
This verifies the core functionality of using Spark with Kubernetes in client mode via a Jupyter notebook driver.
5) Verify S3 Access from Spark
Now that we have verified the general functionality works, lets verify our S3 backend works too.
Modifying the Kubernetes Spark example cell in the notebook:
import os
from pyspark.sql import SparkSession
from pyspark import SparkConf
os.environ['AWS_REGION'] = "omitted"
os.environ['AWS_ACCESS_KEY_ID'] = "omitted"
os.environ['AWS_SECRET_ACCESS_KEY'] = "omitted"
os.environ['S3A_ENDPOINT'] = "s3.{}.amazonaws.com".format(os.environ['AWS_REGION'])
def configure_s3a(sc, aws_access_key_id, aws_secret_access_key, s3a_endpoint):
hadoop_c = sc._jsc.hadoopConfiguration()
hadoop_c.set("fs.s3a.endpoint", s3a_endpoint)
hadoop_c.set("fs.s3a.access.key", aws_access_key_id)
hadoop_c.set("fs.s3a.secret.key", aws_secret_access_key)
hadoop_c.set("fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
conf = SparkConf()\
.setAppName('JUPYTER_PI_SPARK_TEST')\
.setMaster('k8s://https://{}:{}'.format(os.environ['KUBERNETES_PORT_443_TCP_ADDR'],
os.environ['KUBERNETES_PORT_443_TCP_PORT']))\
.set('spark.kubernetes.container.image', 'omnivector/spark-3.0.0-dev-hadoop-2.7.3-conda-base:0.0.1')\
.set('spark.kubernetes.namespace', os.environ['JUJU_KUBERNETES_NAMESPACE'])\
.set('spark.executor.instances', 20)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
configure_s3a(
sc,
os.environ['AWS_ACCESS_KEY_ID'],
os.environ['AWS_SECRET_ACCESS_KEY'],
os.environ['S3A_ENDPOINT'],
)
# Repartition the 27G company dataset to a gzip compressed multipart format
companies_json = sc.textFile("s3a://james-stuff/company-v7.0-public/singleton/0.json")
companies_json.repartition(1000)
companies_json.saveAsTextFile(
"s3a://james-stuff/company-v7.0-public/partitions/",
compressionCodecClass="org.apache.hadoop.io.compress.GzipCodec"
)
spark.stop()
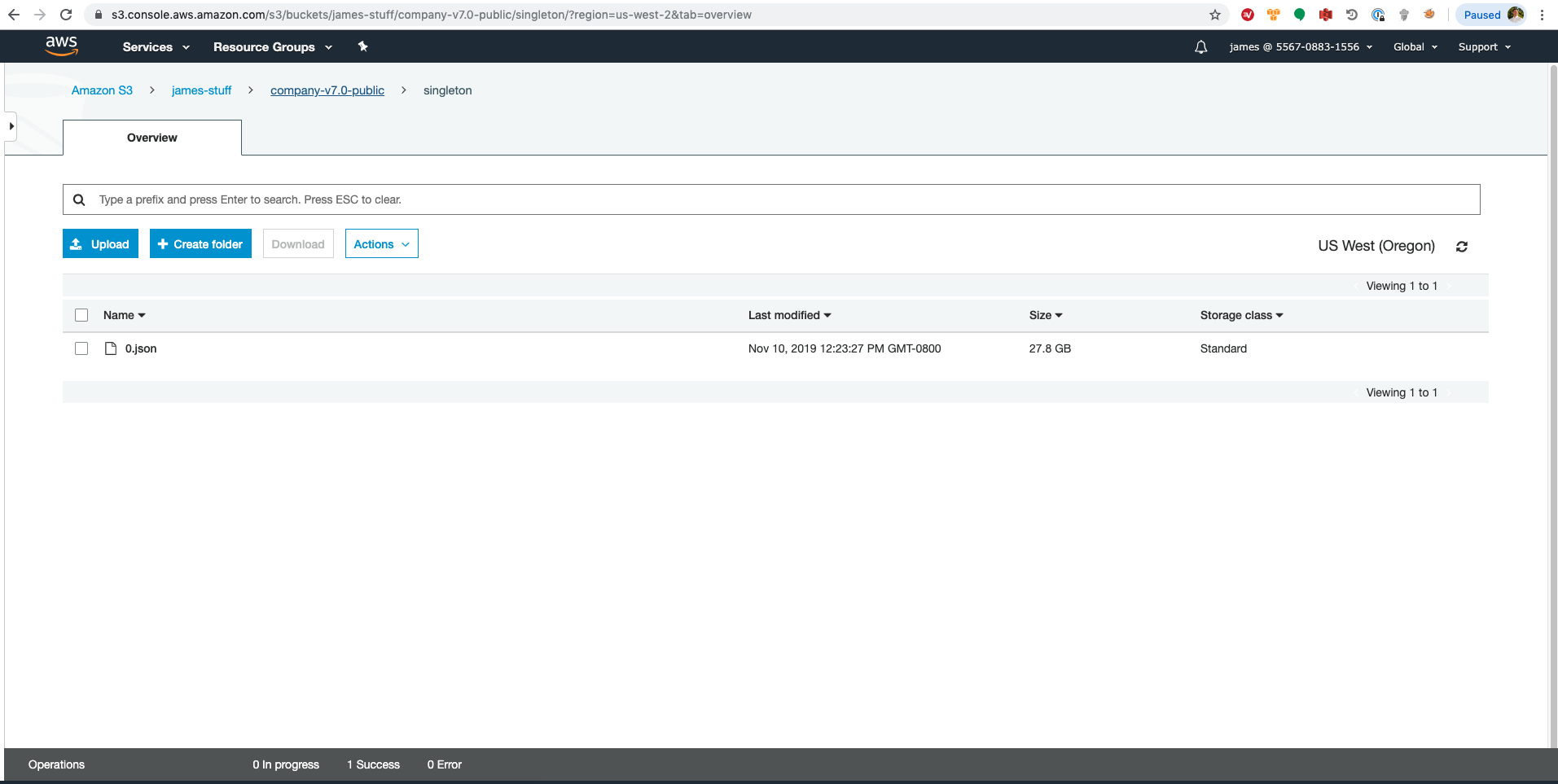
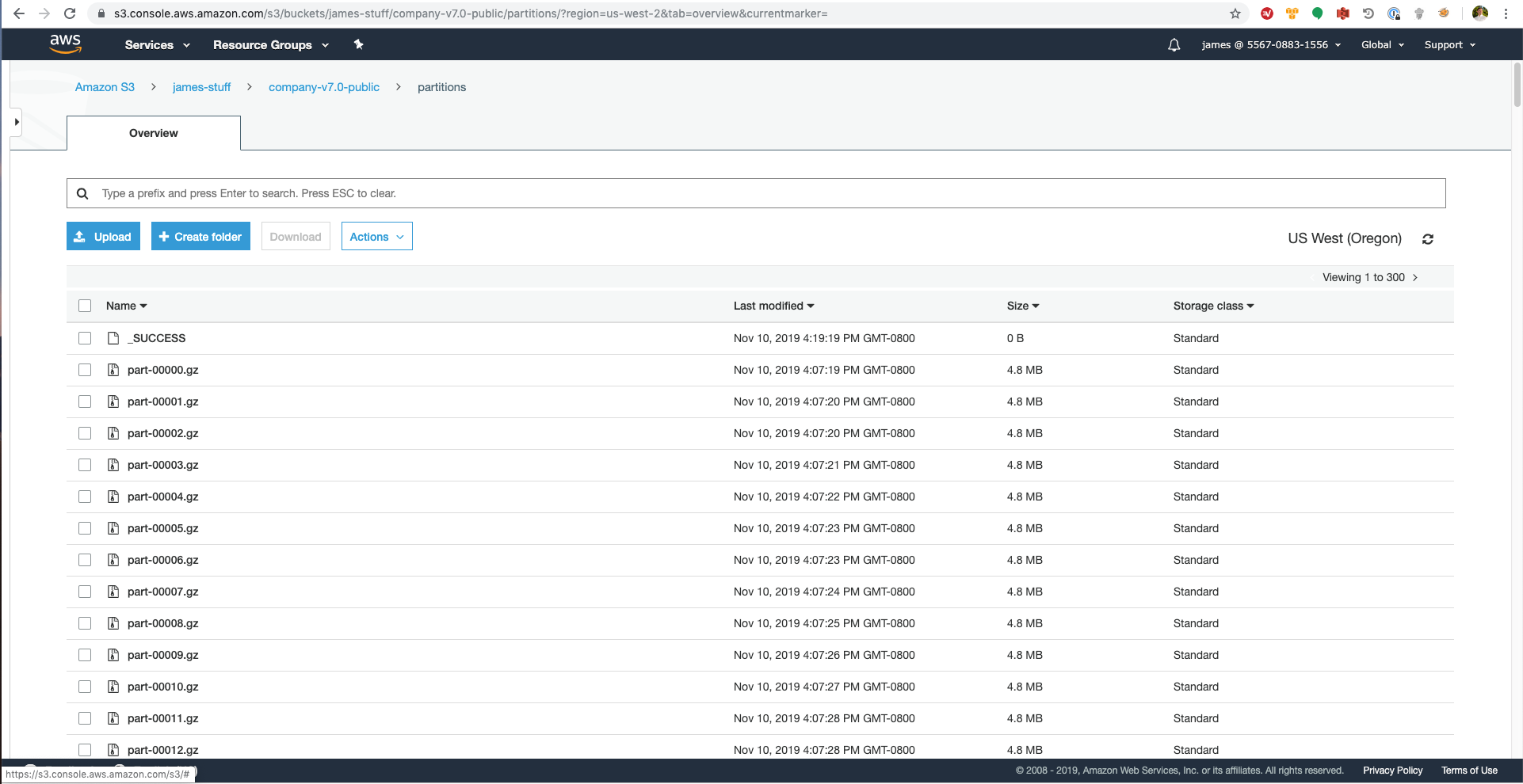
The code above takes a 27.8 GB uncompressed json file and repartitions the data to 1000 x gzip’d newline json files.
Here is the input file:
After running the above code, we can see the result is the multi-part, compressed, repartitioned data:
This simple example shows how you can use Kubernetes and S3 as an alternative to Yarn + HDFS.
Spark on Kubernetes On-Premise
1) Add a Juju model and deploy Ceph + RADOSGW
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
ceph-storage juju_controller_dc_00 pdl-maas-cloud 2.6.9 unsupported 00:09:40Z
SAAS Status Store URL
graylog active juju_controller rredman/utilities.graylog
nagios active juju_controller rredman/utilities.nagios
prometheus active juju_controller rredman/utilities.prometheus
App Version Status Scale Charm Store Rev OS Notes
ceph-fs 13.2.4+dfsg1 active 3 ceph-fs jujucharms 56 ubuntu
ceph-mon 13.2.4+dfsg1 active 3 ceph-mon jujucharms 395 ubuntu
ceph-osd 13.2.4+dfsg1 active 3 ceph-osd jujucharms 421 ubuntu
ceph-radosgw 13.2.4+dfsg1 active 1 ceph-radosgw jujucharms 343 ubuntu
filebeat 6.8.3 active 7 filebeat jujucharms 25 ubuntu
nrpe active 7 nrpe jujucharms 59 ubuntu
prometheus-ceph-exporter active 1 prometheus-ceph-exporter jujucharms 5 ubuntu
telegraf active 7 telegraf jujucharms 29 ubuntu
Unit Workload Agent Machine Public address Ports Message
ceph-fs/0 active idle 0/lxd/0 10.30.62.126 Unit is ready (1 MDS)
ceph-fs/1* active idle 1/lxd/0 10.30.62.125 Unit is ready (1 MDS)
ceph-fs/2 active idle 2/lxd/0 10.30.62.127 Unit is ready (1 MDS)
ceph-mon/0 active idle 0 10.30.62.116 Unit is ready and clustered
filebeat/4 active idle 10.30.62.116 Filebeat ready.
nrpe/1* active idle 10.30.62.116 icmp,5666/tcp ready
telegraf/4 active idle 10.30.62.116 9103/tcp Monitoring ceph-mon/0
ceph-mon/1* active idle 1 10.30.62.117 Unit is ready and clustered
filebeat/0* active idle 10.30.62.117 Filebeat ready.
nrpe/0 active idle 10.30.62.117 icmp,5666/tcp ready
telegraf/3 active idle 10.30.62.117 9103/tcp Monitoring ceph-mon/1
ceph-mon/2 active idle 2 10.30.61.175 Unit is ready and clustered
filebeat/3 active idle 10.30.61.175 Filebeat ready.
nrpe/2 active idle 10.30.61.175 icmp,5666/tcp ready
telegraf/5* active idle 10.30.61.175 9103/tcp Monitoring ceph-mon/2
ceph-osd/0 active idle 4 10.30.62.121 Unit is ready (34 OSD)
filebeat/5 active idle 10.30.62.121 Filebeat ready.
nrpe/3 active idle 10.30.62.121 icmp,5666/tcp ready
telegraf/1 active idle 10.30.62.121 9103/tcp Monitoring ceph-osd/0
ceph-osd/1 active idle 5 10.30.62.123 Unit is ready (34 OSD)
filebeat/2 active idle 10.30.62.123 Filebeat ready.
nrpe/5 active idle 10.30.62.123 icmp,5666/tcp ready
telegraf/2 active idle 10.30.62.123 9103/tcp Monitoring ceph-osd/1
ceph-osd/2* active idle 6 10.30.62.119 Unit is ready (34 OSD)
filebeat/1 active idle 10.30.62.119 Filebeat ready.
nrpe/4 active idle 10.30.62.119 icmp,5666/tcp ready
telegraf/0 active idle 10.30.62.119 9103/tcp Monitoring ceph-osd/2
ceph-radosgw/0* active idle 3 10.30.62.118 80/tcp Unit is ready
filebeat/6 active idle 10.30.62.118 Filebeat ready.
nrpe/6 active idle 10.30.62.118 icmp,5666/tcp ready
telegraf/6 active idle 10.30.62.118 9103/tcp Monitoring ceph-radosgw/0
prometheus-ceph-exporter/3* active idle 0/lxd/3 10.30.62.162 9128/tcp Running
Machine State DNS Inst id Series AZ Message
0 started 10.30.62.116 d9-smblade1-b bionic default Deployed
0/lxd/0 started 10.30.62.126 juju-3ce434-0-lxd-0 bionic default Container started
0/lxd/3 started 10.30.62.162 juju-3ce434-0-lxd-3 bionic default Container started
1 started 10.30.62.117 d10-smblade1-b bionic default Deployed
1/lxd/0 started 10.30.62.125 juju-3ce434-1-lxd-0 bionic default Container started
2 started 10.30.61.175 d11-smblade1-b bionic default Deployed
2/lxd/0 started 10.30.62.127 juju-3ce434-2-lxd-0 bionic default Container started
3 started 10.30.62.118 d9-smblade2-a bionic default Deployed
4 started 10.30.62.121 d10-sm4u-00 bionic default Deployed
5 started 10.30.62.123 d11-sm4u-00 bionic default Deployed
6 started 10.30.62.119 d9-sm4u-00 bionic default Deployed
Offer Application Charm Rev Connected Endpoint Interface Role
ceph-mon ceph-mon ceph-mon 395 1/1 admin ceph-admin provider
2) Create RADOS User for Spark
$ juju ssh ceph-mon/0 \
'sudo radosgw-admin user create --uid="spark" --display-name="Spark Ceph"'
{
"user_id": "spark",
"display_name": "Spark Ceph",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "spark",
"access_key": "U5VIAHU1DHWOS4NOWVS3",
"secret_key": "VGLB2MF75cPTVY0NzYBDXr12Z2NMu8vIMp76jcaf"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
Note the access_key and secret_key. These will be used later when we configure our Spark application.
3) Deploy Kubernetes with Canal
juju deploy cs:~omnivector/bundle/kubernetes-core-canal
At this point we should have a Juju model that resembles the following:
$ juju status
Model Controller Cloud/Region Version SLA Timestamp
k8s-test juju_controller_dc_00 dcmaas/default 2.6.9 unsupported 03:05:10Z
App Version Status Scale Charm Store Rev OS Notes
canal 0.10.0/3.6.1 active 3 canal jujucharms 668 ubuntu
containerd active 3 containerd jujucharms 33 ubuntu
easyrsa 3.0.1 active 1 easyrsa jujucharms 278 ubuntu
etcd 3.2.10 active 1 etcd jujucharms 460 ubuntu
kubernetes-master 1.16.2 active 1 kubernetes-master jujucharms 754 ubuntu exposed
kubernetes-worker 1.16.2 active 2 kubernetes-worker jujucharms 590 ubuntu exposed
Unit Workload Agent Machine Public address Ports Message
easyrsa/0* active idle 0/lxd/0 10.30.64.60 Certificate Authority connected.
etcd/0* active idle 0 10.30.64.57 2379/tcp Healthy with 1 known peer
kubernetes-master/0* active idle 0 10.30.64.57 6443/tcp Kubernetes master running.
canal/2 active idle 10.30.64.57 Flannel subnet 10.1.8.1/24
containerd/2 active idle 10.30.64.57 Container runtime available
kubernetes-worker/0* active idle 1 10.30.64.58 80/tcp,443/tcp Kubernetes worker running.
canal/0* active idle 10.30.64.58 Flannel subnet 10.1.49.1/24
containerd/0* active idle 10.30.64.58 Container runtime available
kubernetes-worker/1 active idle 2 10.30.64.59 80/tcp,443/tcp Kubernetes worker running.
canal/1 active idle 10.30.64.59 Flannel subnet 10.1.41.1/24
containerd/1 active idle 10.30.64.59 Container runtime available
Machine State DNS Inst id Series AZ Message
0 started 10.30.64.57 d9-smblade2-d bionic default Deployed
0/lxd/0 started 10.30.64.60 juju-5f6350-0-lxd-0 bionic default Container started
1 started 10.30.64.58 d10-smblade3-b bionic default Deployed
2 started 10.30.64.59 d10-smblade3-c bionic default Deployed
juju scp kubernetes-master/0:config ~/.kube/config
4) Extra Ops
Preform the steps outlined here to make Ceph provide rbd root volumes to your containers.
And the steps outlined here to get metallb working as an ingress loadbalancer.
Following this you should be ready to add the Kubernetes cloud to your Juju controller similarly to how we did above in the AWS example.
Add a model and deploy the Jupyter K8S charm (cs:~omnivector/jupyter-k8s).
You should now be able to run Spark jobs on the Kubernetes cluster using the Ceph S3 as a distributed object storage backend similarly to how we did in AWS using AWS S3.
5) Up and running
Some example code to get you started (remember to replace the unique configs with those of your own):
s3a_test.py
#!/usr/bin/env python3
from pyspark.sql import SparkSession
from pyspark import SparkConf
def configure_s3a(sc, aws_access_key_id, aws_secret_access_key, s3a_endpoint):
hadoop_c = sc._jsc.hadoopConfiguration()
hadoop_c.set("fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
hadoop_c.set("fs.s3a.endpoint", s3a_endpoint)
hadoop_c.set("fs.s3a.access.key", aws_access_key_id)
hadoop_c.set("fs.s3a.secret.key", aws_secret_access_key)
if __name__ == "__main__":
# Define vars
access_key_id = "U5VIAHU1DHWOS4NOWVS3"
secret_access_key = "VGLB2MF75cPTVY0NzYBDXr12Z2NMu8vIMp76jcaf"
k8s_master = "k8s://https://10.30.64.57:6443"
s3a_endpoint = "http://10.30.62.118"
spark_kubernetes_container_image = \
"omnivector/spark-3.0.0-dev-hadoop-2.7.3-conda-base:0.0.1"
spark_kubernetes_namespace = "default"
spark_executor_instances = 50
# Create spark conf, session, context
conf = SparkConf().setAppName("Spark S3A Demo").\
.setMaster(k8s_master)\
.set('spark.kubernetes.container.image', spark_kubernetes_container_image)\
.set('spark.kubernetes.namespace', spark_kubernetes_namespace)\
.set('spark.executor.instances', spark_executor_instances)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
configure_s3a(sc, access_key_id, secret_access_key, s3a_endpoint)
# At this point we should be ready to talk to our ceph cluster.
Hopefully this gives a semi-sweet, well rounded glimpse into how S3 backed Spark workloads can be provisioned on Kubernetes using Juju, on-prem and in the cloud.
Thanks!