
Intro
Building on the previous article in this series. I want to identify some of the flaws in the Spark solution that I described and what the resolutions were as well as discuss some of the other solutions out there.
Was my solution good or bad?
From high up, the solution I came up with accommodated our specific use case really well. Decoupling the storage and ridding HDFS was huge in many ways. The Spark storage bits via Juju storage; accommodated the storage needs of Spark really well. The code deps bit via layer-conda was a huge improvement in how we were managing dependencies. My Spark project had come a long way from where it started, but was no where near finished.
There are a number of reasons why, but in general, in terms of running Spark in conjunction with Hadoop or using Hadoop libraries via Spark, Spark needs to be built for the version of Hadoop that you will be running on.
An example from stack overflow “Because HDFS is not protocol-compatible across versions, if you want to read from HDFS, you’ll need to build Spark against the specific HDFS version in your environment.” This build and runtime dependency alignment across the entire bigtop stack is of critical importance if you intend to run any of the ASF software components in conjunction with any other component of the ASF stack, illuminating the genius, and importance of the build system implemented by the original charmed bigtop stack. This also shed light on reasons why my slimmed down solution wasn’t really full circle.
I realized that if I wanted to make a Spark charm that allowed for Spark and Hadoop builds to be specified as resources to the charm, that I would need a way of building Spark against Hadoop versions reliably, thus increasing the unique cycles needed to facilitate making my solution robust. Without a build system in place, the charms would be locked into a version of Spark and Hadoop until the custom builds were created, tested, and attached to the charms. It was apparent to me that I did not want to create/maintain my own Spark and Hadoop build system.
The Spark standalone charm solution I created works great if you want to run Spark Standalone, but has its snares when it comes to maintainability and compatibility with components of the greater ASF ecosystem. Do the Spark standalone charms have a future? Lets explore some other options before we come to a decision.
EMR
AWS provides an Elastic Map Reduce as a service. You give it a config script(s), and tell it the spark-submit command to run and walaah. Behind the scenes custom EMR AMIs launch and install emr-hadoop, and run your job.
An example of how we started using it:
Define a bootstrap script(s) that each node will run to provision your custom deps:
emr-conda-bootstrap.sh
#!/bin/bash
#
# Install MiniConda and PDL Deps
#
set -eux
branch=$1
sudo yum install git -y
CONDA_DIR="/home/hadoop/conda"
CONDA_VERSION="4.7.10"
CONDA_MD5_CHECKSUM="1c945f2b3335c7b2b15130b1b2dc5cf4"
wget "http://repo.continuum.io/miniconda/Miniconda3-${CONDA_VERSION}-Linux-x86_64.sh" \
-O miniconda.sh
echo "$CONDA_MD5_CHECKSUM miniconda.sh" | md5sum -c
bash miniconda.sh -f -b -p "$CONDA_DIR"
/home/hadoop/conda/bin/conda update --all --yes
/home/hadoop/conda/bin/conda config --set auto_update_conda False
/home/hadoop/conda/bin/conda create \
-n pyspark python=3.7 numpy pandas pip -y
/home/hadoop/conda/envs/pyspark/bin/pip install \
git+https://<mycustompythondeps>@github.com/org/repo.git@$branch
PYSPARK_PYTHON="/home/hadoop/conda/envs/pyspark/bin/python"
PATH="$CONDA_DIR/bin:$PATH"
exit 0
You can optionally define spark-submit steps to run:
steps = [
{
'Name': "My Data Processing EMR Job",
'ActionOnFailure': 'CANCEL_AND_WAIT',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': [
'spark-submit',
'/home/hadoop/mycustomdeps/main.py',
]
}
}
]
Supply the bootstrap script and the spark-submit steps to the run_job_flow function:
def example_run_emr():
...
client = boto3.client('emr')
response = client.run_job_flow(
Name="BDX - EMR RIPPERS",
LogUri='s3://pdl-emr/logs',
ReleaseLabel='emr-5.26.0',
Instances=instances,
Applications=applications,
Configurations=configurations,
BootstrapActions=[
{
'Name': 'Install and configure miniconda and install dependent packages',
'ScriptBootstrapAction': {
'Path': 's3://pdl-emr/bootstrap/emr-conda-bootstrap.sh',
'Args': [bootstrap_deps_git_branch],
},
},
],
Steps=steps,
VisibleToAllUsers=True,
JobFlowRole='PDL_EMR_EC2_DefaultRole',
ServiceRole='PDL_EMR_DefaultRole'
)
...
A useful configuration for run_job_flow() is the KeepJobFlowAliveWhenNoSteps configuration.
Instances={
...
'KeepJobFlowAliveWhenNoSteps': False
...
}
Setting this to False means the EMR cluster will terminate after it completes the defined steps. Which gives you the capability to spin up the resources you need, when you need them, and have them go away when the provided steps have complete. In this way EMR is very ephemeral and only lives for as long as it takes to configure itself and run the steps.
Alternatively, if KeepJobFlowAliveWhenNoSteps == True, the EMR cluster will remain deployed and running even if there are no steps defined for it to run.
This is useful if you want to spin up the EMR cluster and use it remotely, or outside the context of defined steps in the job flow. For example, with KeepJobFlowAliveWhenNoSteps == True, you could deploy the cluster and then configure the Spark context to point at the resource-manager host:port and run jobs on the EMR cluster by executing cells in the jupyter notebook on your local machine.
Using EMR in this way has given us a no-fuss, sturdy interface to running Spark jobs in the cloud. When combined with S3 as a backend, EMR provides a hard to beat scale factor for the number of jobs you can run and amount storage you can use.
Docker
I don’t know how to preface the dockerization of this workflow other then with what I’ve described above. I have faced challenges in the likes of mismatched build and runtime versions and mismatched dependencies. This issue became more prevalent as I tried to package Spark and Hadoop underneath a Jupyter Notebook and point it at an EMR cluster in hopes of getting remote EMR (yarn-client) execution to work. Find emr-hadoop and emr-spark documentation. An emr-5.27.0 cluster is going to run Spark 2.4.4 and Hadoop 2.8.5. This means if you want to execute jupyter-notebook code against the emr cluster, the Spark and Hadoop dependancies that exist where the jupyter notebook is running need to match those provisioned in the emr cluster. Dockerizing Spark<3.0.0 is tedious because of the unsupported alpine image it was built on. Now days, Spark uses a supported openjdk base built on debian-slim, this makes building on top of spark images for more streamline (and work).
My current legacy Juju workflow deploying Jupyter + Spark + Hadoop is a dockerhost backed solution.
Go ahead and try it out:
juju deploy cs:~omnivector/jupyter-docker
You can optionally supply your own/another unique jupyter docker image, find examples here:
juju deploy cs:~omnivector/jupyter-docker \
--config jupyter-image="omnivector/jupyterlab-spark-hadoop-base:0.0.1"
Change the running image post deploy by simply changing the config:
juju config jupyter-docker jupyter-image="omnivector/jupyter-spark-hadoop-base:0.0.1"
Packaging Jupyter in this way allows for robust and dynamic data development workflows due to the charm acting as an ops shim to provide the docker image on demand where ever, when ever. Developers and/or build systems can add custom deps on top of a base Jupyter image and maintain custom images using this same charm to consume them. In this way, we can run Jupyter driven Spark workloads from a docker image deployed via Juju. The only drawback here is that since the Jupyter/Spark run in the container on a host, it makes running anything other than “cluster” or “local” type Spark workloads slightly difficult due to the networking constraints. That said, this is a great tool for Spark application development.
A little background
- Spark’s architecture consists of executor processes and driver processes that work together to run a job, meaning they need to communicate with each other over the network to accomplish the work.
- Spark can run in two primary configurations, independent of the backend; “cluster” or “client”.
- In “cluster” configurations you can run a remote spark driver process that is dynamically deployed alongside the executor processes (keep in mind all of this is separate from where you execute the code, the jupyter notebook).
- In “client” mode, the Spark driver needs to run where you execute the
spark-submitfrom (in this case the Jupyter notebook docker image) and must be reachable/routable from where the Spark executors are running (eg the backend; k8s, mesos, yarn, spark-standalone). - Most client mode Spark configurations execute the code on the same substrate that the executors run (this makes sense, so then the executors can talk to the driver as the driver runs where you execute the code).
All said and done, this simple solution makes a lot of sense for many Jupyter/Spark development use cases.
Kubernetes
The general workflow for how I am using Jupyter + Spark + Hadoop + Ceph on k8s via Juju:
juju bootstrap k8sjuju add-model jupyter-k8s-testingjuju deploy cs:~omnivector/jupyter-k8sjuju config jupyter-k8s juju-external-hostname=somehostnametomakejujuhappy.com-
juju expose jupyter-k8s
At this point you should have a docker image running jupyter in k8s accessible via the loadbalancer fqdn. - Access the elb fqdn in your browser to pull up the jupyter notebook web ui.
- Execute the notebook cells to run the spark-pi example on the container (local) and on the cluster (k8s) respectively.
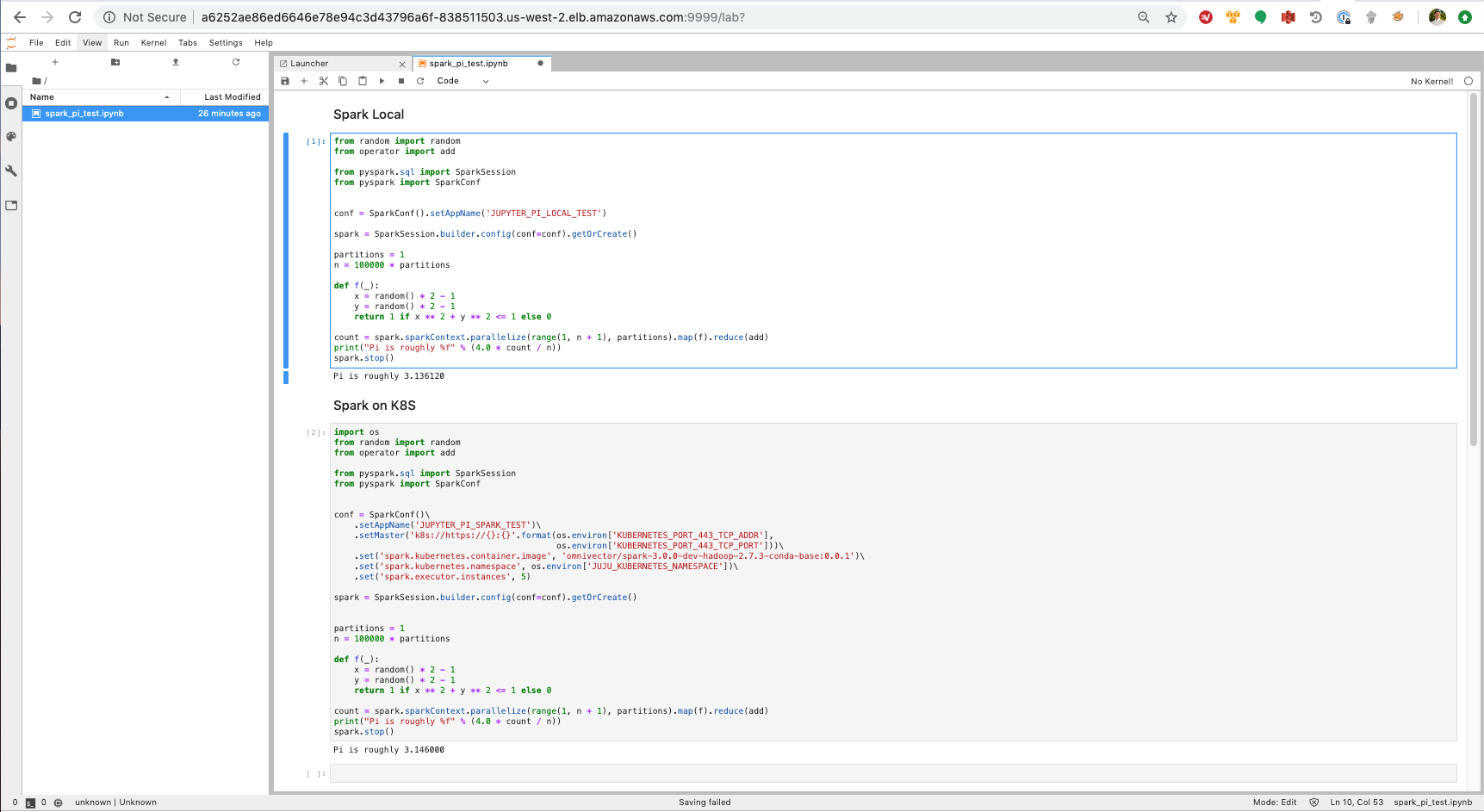
The primary takeaway from the above (hard to read) screen shot is the bit that sets values into the spark config to configure the k8s backend:
conf = SparkConf()\
.setAppName('JUPYTER_PI_SPARK_TEST')\
.setMaster('k8s://https://{}:{}'.format(os.environ['KUBERNETES_PORT_443_TCP_ADDR'],
os.environ['KUBERNETES_PORT_443_TCP_PORT']))\
.set('spark.kubernetes.container.image', 'omnivector/spark-3.0.0-dev-hadoop-2.7.3-conda-base:0.0.1')\
.set('spark.kubernetes.namespace', os.environ['JUJU_KUBERNETES_NAMESPACE'])\
.set('spark.executor.instances', 5)
A takeaway from the above is that you need the same deps in the same place underneath the jupyter notebook as need to exist on the executors. Notice the value of 'spark.kubernetes.container.image' (the config that defines the image that the executors run in), it is the same image that the jupyter notebook image is built on.
The building of the jupyter notebook image from the image that your executors run is a really simple way of using the build system to organically facilitate the requirements of the workload. This is the largest come up of all in the packaging Jupyter/Spark applications; the ability to have the notebook or driver image built from the same base image as the executors.
The layer-jupyter-k8s applies a role to grant the Jupyter/Spark container the permission needed to provision other containers (Spark workloads) on the cluster. This allows a user to login to the jupyter web ui and provision Spark workloads on demand on the k8s cluster via running cells in the notebook.
A few high level takeaways on why this is good:
- Multi-tenant - Many developers can execute against the k8s cluster simultaneously.
- Dockerized deps - Package your data dependencies as docker containers (this works really well when you need to lock in hadoop, spark, conda, private dep abc, to versions for different workloads).
- Development workflow - Run workloads on different dependencies with out having to re-provision the cluster.
- Ops simplification - Spark driver and executor pods can be built from the same image.
Why not so good:
- Untracked resources - Spark workloads provisioned on k8s via Spark drivers are not tracked by Juju.
- Ceph + K8S, instead of a Hadoop distribution - It takes far more mature infrastructure to run Ceph + K8S correctly than it does to run Hadoop/HDFS. This comes down to the fact that you can run a 100 node Hadoop/HDFS installation on an L2 10G network by clicking your way through the CDH gui. For Ceph + K8S to work correctly, you need to implement an L3 or L2/L3 hybrid network topology that facilitates multi-pathing and scaling links in a pragmatic way, you can’t just use L2, 10G if you want to do Spark on K8S + Ceph past a few nodes.
Conclusion
Which Spark backend and deployment type is right for you, and how where do you run it?
This should be defined by your use case.
Hopefully this write up can provide a light into the snags I’ve hit, and how I got around them to where I am now. Also as a stepping stone for others walking in this direction.
Thanks!